Clear Sky Science · ja
頑健なシーン文字認識のためのConvNeXt–BiLSTMハイブリッドフレームワーク
写真内の文字を読むことが重要な理由
カメラは日々、街路標識、店名、バス停、文字がびっしり写ったスクリーンショットなどを撮影します。この種の文字をコンピュータに読ませることは、ナビゲーションアプリの強化、低視力者への支援、散らかった写真の検索可能化などに役立ちます。しかし屋外の文字は整っていることが稀で、曲がっていたり、傾いていたり、ぼやけていたり、背景に埋もれていたりします。本研究は、画像の見方と合成例・実例からの学習方法を再設計することで、こうした手強いシーン文字をより賢く、より高速に読み取る手法を紹介します。 
きれいなスキャンから乱れた実世界へ
従来の文字認識ソフトは平坦で整ったページ上のスキャン文書向けに作られてきました。対照的にシーン文字認識は、角度の付いた道路標識、ネオンロゴ、金属の反射、さまざまな書体や言語の混在に対処する必要があります。これまでのシステムは合成データに大きく依存してきました:画像に貼り付けたコンピュータ生成の単語です。これらの大規模な人工データはラベル付けが容易ですが、実際の街の混沌さを完全には再現しません。その結果、テストセットで良好な性能を示すモデルでも、混雑した広告、曲がった店名、暗所では失敗することがあります。著者らは、今後の進展はより良い画像処理と実世界例の豊富な活用の両方にかかっていると主張します。
画像中の単語を新たに見る方法
提案システムの中核は、最新の画像解析器であるConvNeXtと、順序を読む双方向LSTMの組み合わせです。画像を解析する前に、特殊な変換段階がゆがんだり曲がったりしたテキストを穏やかにまっすぐに整え、より水平な単語に近づけます。ConvNeXtは画像を多数の小片に分解し、細かな筆跡や文字の形、単語の長い水平な流れを捉えるパターンを学習しつつ、煩雑な背景のノイズを無視します。追加のモジュールは、ネットワークがグローバルな文脈と局所的な詳細をバランスさせ、文字が現れる情報量の多い領域に注意を集中させるのを助けます。最後に、順序リーダーはこれらの特徴を左右両方向から走査し、注意機構を持つデコーダが一度に一つずつ最も可能性の高い文字列を出力します。
合成と実写の単語でシステムを教える
このようなシステムの学習には大量のラベル付き例が必要です。著者らは二段階の戦略を採用します。まず、フォント、サイズ、歪みの多様性が豊富な何百万もの合成単語画像で事前学習を行います。この段階では、困難な例に学習を集中させ、モデルが単一の予測に過度に自信を持つのを防ぐ損失関数を適用します。次に、国際コンペや公開画像プロジェクトから収集した大規模な実世界データセットで微調整を行います。これらのデータセットには、直線・曲線の文字、多言語、住宅番号、異なる照明や天候下の標識が含まれます。チームはサンプルを慎重にリサイズ、フィルタリング、バランス調整して、モデルが偏ったソースに過度適合しないよう公正なケースの混合を見せています。
実用での性能
6つの広く使われるベンチマークで評価したところ、新しいフレームワークは合成データと実データの両方で学習した場合、平均で約94.7パーセントの精度に到達しました。これは合成のみで学習したバージョンより明らかに優れ、同様の条件で学習した他の手法と比べても競争力があるか上回る結果です。詳細な内訳では、正規化と注意ブロックの追加が特に曲がったり傾いたりした不規則な文字や、雑多な背景の中での認識に効果を発揮していることが示されています。同時に、このシステムは比較的軽量で、約2000万パラメータを使用し、最新のGPU上で単語画像を数ミリ秒の千分の一程度で読み取れます。速度と精度のこのバランスにより、運転支援やモバイルでのライブ翻訳などリアルタイム用途に適しています。 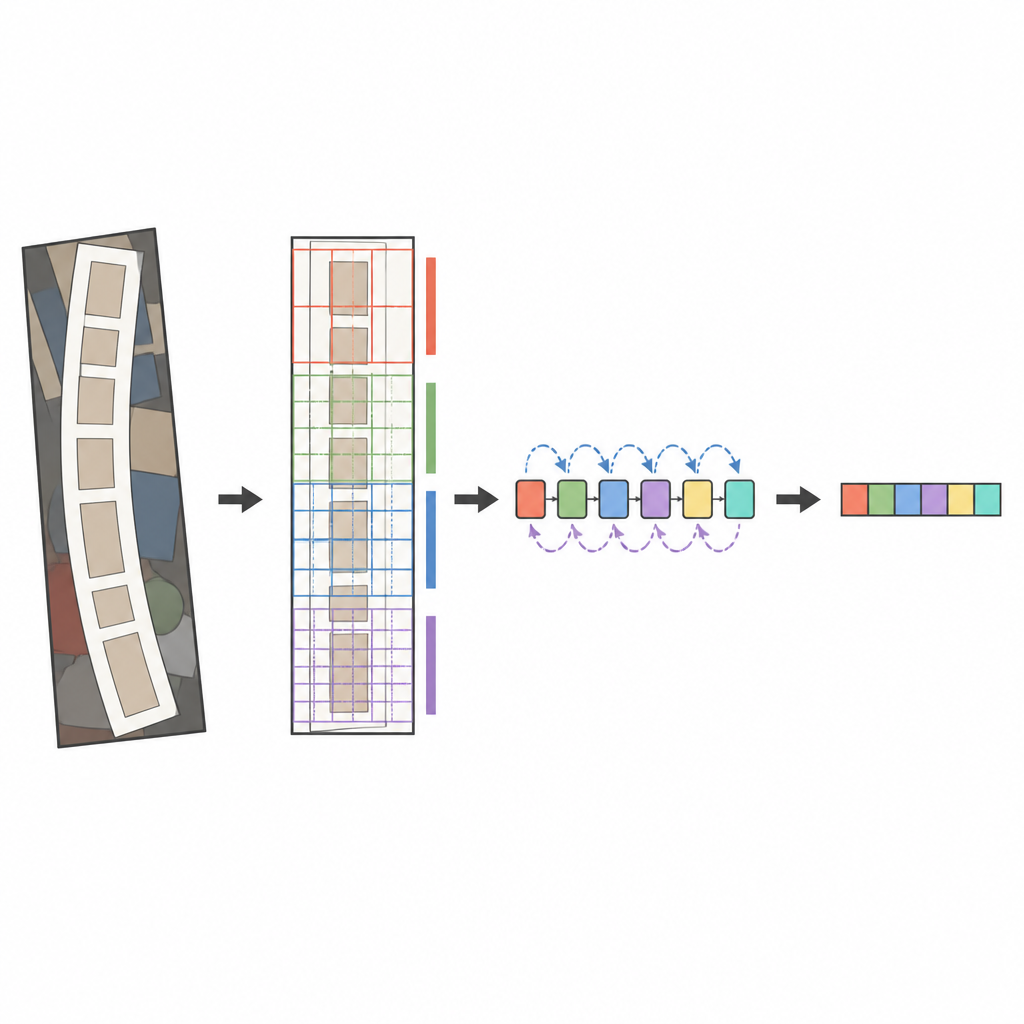
日常技術にとっての意味
簡潔に言えば、本研究は、慎重に設計された画像バックボーンと賢い順序リーダーを組み合わせ、合成と実写の両方で学習させることで、乱れた実世界の文字をより確実かつ迅速に読み取れることを示しています。専門外の人にとっては、将来のアプリがフロントガラス越しの道路標識をより正確に読み取ったり、スーパーのラベルを認識したり、視覚に制限のあるユーザーのためにシーンの内容を語ったりする能力が向上することを意味します。極度のぼけ、強いまぶしさ、非常に装飾的な書体にはまだ苦戦しますが、日常の複雑な視覚環境で動作する、より頑健で柔軟な文字読み取りツールの強固な基盤を築いています。
引用: Khattab, A., Elpeltagy, M., Youness, F. et al. A hybrid ConvNeXt–BiLSTM framework for robust scene text recognition. Sci Rep 16, 15059 (2026). https://doi.org/10.1038/s41598-026-50234-6
キーワード: シーン文字認識, 深層学習, ConvNeXt, 実世界データセット, コンピュータビジョン