Clear Sky Science · ar
إطار هجيني ConvNeXt–BiLSTM للتعرّف المتين على النصوص في المشاهد
لماذا يهم قراءة النص في الصور
تلتقط الكاميرات يومياً لافتات الشوارع، أسماء المحلات، محطات الحافلات، ولقطات شاشة مليئة بالكلمات. تعليم الحواسيب قراءة هذا النوع من النصوص يمكن أن يعزّز تطبيقات الملاحة، يساعد الأشخاص ضعيفي البصر، ويحوّل الصور الفوضوية إلى معلومات قابلة للبحث. ومع ذلك، فإن النص في العالم الحقيقي نادراً ما يكون مرتّباً: قد يكون منحنيًا، مائلاً، ضبابيًا، أو مخفيًا في خلفيات مزدحمة. تقدّم هذه الدراسة طريقة أذكى وأسرع للحواسيب لقراءة مثل هذا النص التحدي، عبر إعادة تصميم كيفية النظر إلى الصور وكيفية التعلم من أمثلة مزيفة وحقيقية. 
من المسوحات النظيفة إلى الحياة الحقيقية المبعثرة
بُنيت برامج قراءة النصوص التقليدية للمستندات الممسوحة ضوئياً، حيث تقف الحروف على صفحات مسطّحة ونظيفة. أمّا التعرّف على نصوص المشاهد فيجب أن يتعامل مع لافتات الطرق المصوّرة بزاوية، شعارات النيون، الانعكاسات على المعدن، ومزيج من الخطوط واللغات. اعتمدت الأنظمة السابقة بشكل كبير على بيانات تركيبية: كلمات مولّدة حاسوبياً مُلصقة على صور. هذه المجموعات الاصطناعية الكبيرة سهلة الوسم لكنها تفتقر إلى فوضى الشوارع الحقيقية. ونتيجة لذلك، قد تفشل النماذج التي تُظهر أداءً جيداً على مجموعات الاختبار عندما تواجه لوحات إعلانات مزدحمة، أسماء محلات منحنية، أو إضاءة منخفضة. يجادل المؤلفون بأن التقدّم الآن يعتمد على كل من معالجة صور أفضل ونظام غذائي أغنى من الأمثلة من العالم الحقيقي.
طريقة جديدة لرؤية الكلمات في الصور
جوهر النظام المقترح هو محلل صور حديث يُدعى ConvNeXt، مدموج مع قارئ تسلسلي يعرف بـ BiLSTM ثنائي الاتجاه. قبل تحليل الصورة، تقوم مرحلة تحويل خاصة بفرد النص المشوّه أو المنحني بلطف ليشبه كلمة أفقية أكثر. ثم يجزّئ ConvNeXt الصورة إلى العديد من الأجزاء الصغيرة ويتعلّم أنماطاً تلتقط الضربات الدقيقة، أشكال الحروف، والتدفق الأفقي الأطول للكلمات، مع تجاهل التشويش الخلفي المشتت. تساعد وحدات إضافية الشبكة على تحقيق توازن بين السياق العام والتفاصيل المحلية وتركيز الانتباه على المناطق الأكثر إفادة، مثل مواضع ظهور الحروف فعلاً. أخيراً، يفحص القارئ التسلسلي هذه الميزات من اليسار إلى اليمين ومن اليمين إلى اليسار، ويقوم مفكك ترميز قائم على الانتباه بتهجئة تسلسل الأحرف الأكثر احتمالاً رمزاً تلو الآخر.
تدريب النظام على كلمات مزيفة وحقيقية
يتطلب تدريب مثل هذا النظام أعدادًا هائلة من الأمثلة الموسومة. يستخدم المؤلفون استراتيجية من خطوتين. أولاً، يقومون بالتدريب المسبق على ملايين صور الكلمات التركيبية، التي توفر تنوعاً هائلاً في الخطوط والأحجام والتشوهات. خلال هذه المرحلة يطبقون دالة خسارة تركز التعلم على الأمثلة الصعبة وتمنع النموذج من أن يصبح واثقاً جداً من أي تنبؤ فردي. بعد ذلك، يتم ضبط النموذج بدقة على مجموعة كبيرة من مجموعات البيانات من العالم الحقيقي المجمعة من مسابقات دولية ومشاريع صور مفتوحة. تتضمن هذه المجموعات نصوصًا مستقيمة ومنحنية، لغات متعددة، أرقام منازل، ولافتات تحت إضاءات وطقس متباينين. يعمل الفريق على تغيير المقاسات، ترشيح، وموازنة العينات بعناية حتى يرى النموذج مزيجاً عادلاً من الحالات ولا يتكيّف بشكل مفرط مع مصدر واحد.
مدى فعاليته عملياً
عند الاختبار على ستة معايير مستخدمة على نطاق واسع، يصل الإطار الجديد إلى متوسط دقة يقارب 94.7 بالمئة عند تدريبه على كل من البيانات التركيبية والحقيقية، متقدماً بوضوح على نسخته المعتمدة على التركيبية فقط ومنافساً أو متفوقاً على طرق رائدة أخرى تم تدريبها في ظروف مماثلة. توضح تفصيلات الأداء أن كتل التطبيع والانتباه المضافة تُفيد بشكل خاص مع النصوص غير المنتظمة، مثل الكلمات المنحنية أو المائلة أمام خلفيات مزدحمة. في الوقت نفسه، يبقى النظام خفيفاً نسبياً: فهو يستخدم نحو 20 مليون معلمة ويمكنه قراءة صورة كلمة في بضعة آلاف من الثانية على بطاقة رسومية حديثة. هذا التوازن بين السرعة والدقة يجعله مناسباً للاستخدامات في الوقت الحقيقي مثل مساعدة السائق أو الترجمة الحية على الأجهزة المحمولة. 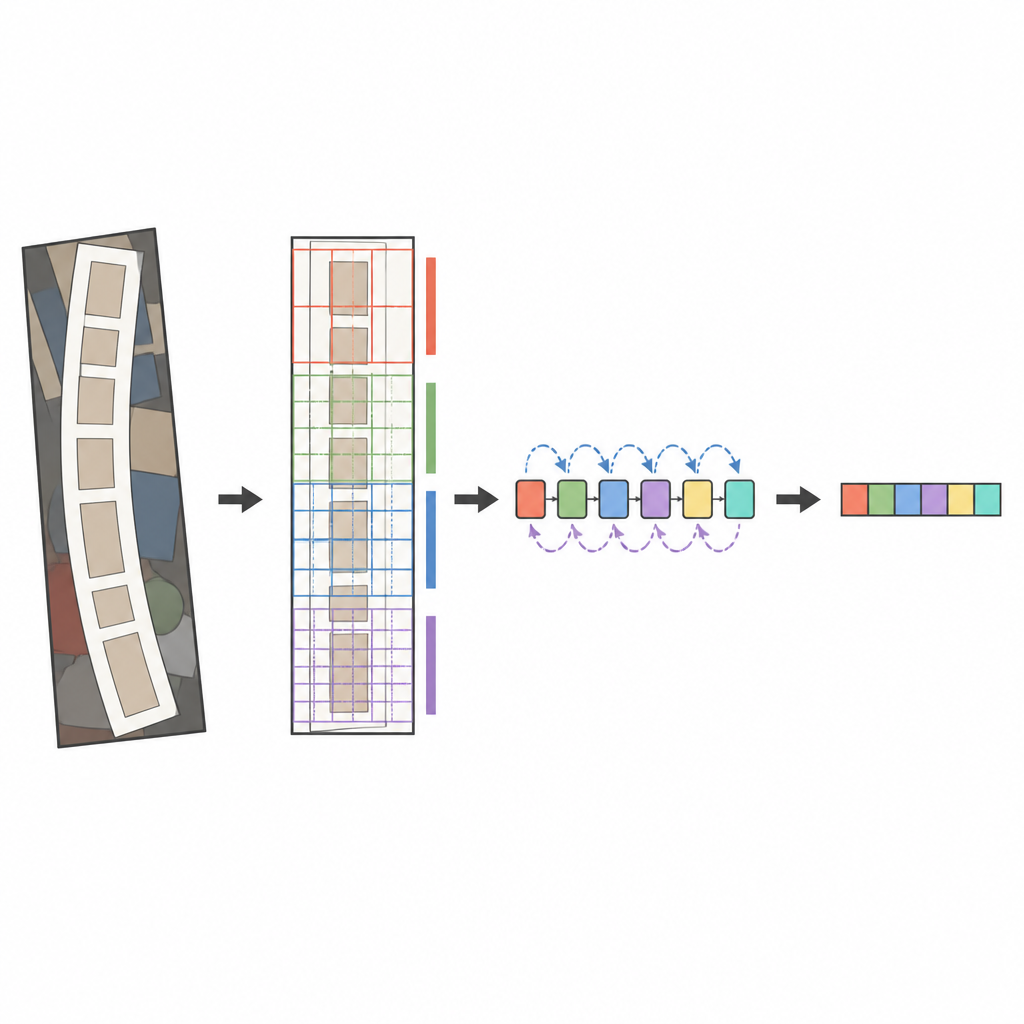
ماذا يعني هذا لتكنولوجيا الحياة اليومية
ببساطة، تُبيّن الدراسة أن بنية صورة مصممة بعناية، مقترنة بقارئ تسلسلي ذكي ومدرّب على مشاهد مزيفة وحقيقية، يمكنها قراءة نصوص العالم الحقيقي المبعثرة بشكل أكثر موثوقية وسرعة. للمستخدمين غير المتخصصين، يعني هذا أن التطبيقات المستقبلية قد تؤدي عملاً أفضل في قراءة لافتات الشوارع عبر الزجاج الأمامي، والتعرّف على الملصقات في المتاجر، أو سرد محتوى المشهد لمستخدمي الأجهزة ذوي ضعف البصر. وبينما لا يزال النظام يواجه صعوبة مع الضبابية الشديدة، الوهج القوي، والخطوط ذات التنميق العالي، فإنه يؤسس قاعدة صلبة لأدوات قراءة نصوص أكثر متانة ومرونة تعمل في بيئات بصرية معقدة من الحياة اليومية.
الاستشهاد: Khattab, A., Elpeltagy, M., Youness, F. et al. A hybrid ConvNeXt–BiLSTM framework for robust scene text recognition. Sci Rep 16, 15059 (2026). https://doi.org/10.1038/s41598-026-50234-6
الكلمات المفتاحية: التعرّف على نصوص المشاهد, التعلّم العميق, ConvNeXt, مجموعات بيانات من العالم الحقيقي, رؤية الحاسوب