Clear Sky Science · en
A hybrid ConvNeXt–BiLSTM framework for robust scene text recognition
Why reading text in photos matters
Every day, cameras capture street signs, shop names, bus stops, and screen shots filled with words. Teaching computers to read this kind of text can power navigation apps, help people with low vision, and turn messy photos into searchable information. Yet text in the wild is rarely neat: it can be curved, tilted, blurry, or hidden in busy backgrounds. This study introduces a smarter and faster way for computers to read such challenging scene text, by redesigning how they look at images and how they learn from both fake and real examples. 
From clean scans to messy real life
Traditional text reading software was built for scanned documents, where letters sit on flat, clean pages. Scene text recognition, by contrast, must deal with road signs caught at an angle, neon logos, reflections on metal, and a mix of fonts and languages. Past systems leaned heavily on synthetic data: computer generated words pasted on images. These large artificial collections are easy to label but lack the full chaos of real streets. As a result, models that do well on test sets can still fail when confronted with crowded billboards, curved shop names, or low light. The authors argue that progress now depends on both better image processing and a richer diet of real-world examples.
A new way to look at words in images
The core of the proposed system is a modern image analyzer called ConvNeXt, combined with a sequence reader known as a bidirectional LSTM. Before the image is analyzed, a special transformation stage gently straightens warped or curved text so it looks more like a horizontal word. ConvNeXt then breaks the image into many small pieces and learns patterns that capture fine strokes, character shapes, and the longer horizontal flow of words, while ignoring distracting background clutter. Extra modules help the network balance global context against local detail and focus its attention on the most informative regions, such as where letters actually appear. Finally, the sequence reader scans these features from left to right and right to left, and an attention based decoder spells out the most likely character sequence one symbol at a time.
Teaching the system with fake and real words
Training such a system requires vast numbers of labeled examples. The authors use a two step strategy. First, they pre-train on millions of synthetic word images, which offer huge variety in fonts, sizes, and distortions. During this stage they apply a loss function that focuses learning on hard examples and prevents the model from becoming too confident in any single prediction. Next, they fine tune on a large collection of real-world datasets gathered from international competitions and open image projects. These datasets include straight and curved text, multiple languages, house numbers, and signs under different lighting and weather. The team carefully resizes, filters, and balances samples so the model sees a fair mix of cases and does not overfit to any one source.
How well it works in practice
Tested on six widely used benchmarks, the new framework reaches an average accuracy of about 94.7 percent when trained on both synthetic and real data, clearly ahead of its own synthetic only version and competitive or better than other leading methods trained under similar conditions. A detailed breakdown shows that the added normalization and attention blocks especially help with irregular text, such as curved or tilted words against cluttered backgrounds. At the same time, the system remains relatively light: it uses about 20 million parameters and can read a word image in a few thousandths of a second on a modern graphics card. This balance between speed and accuracy makes it suitable for real-time uses like driver assistance or live translation on mobile devices. 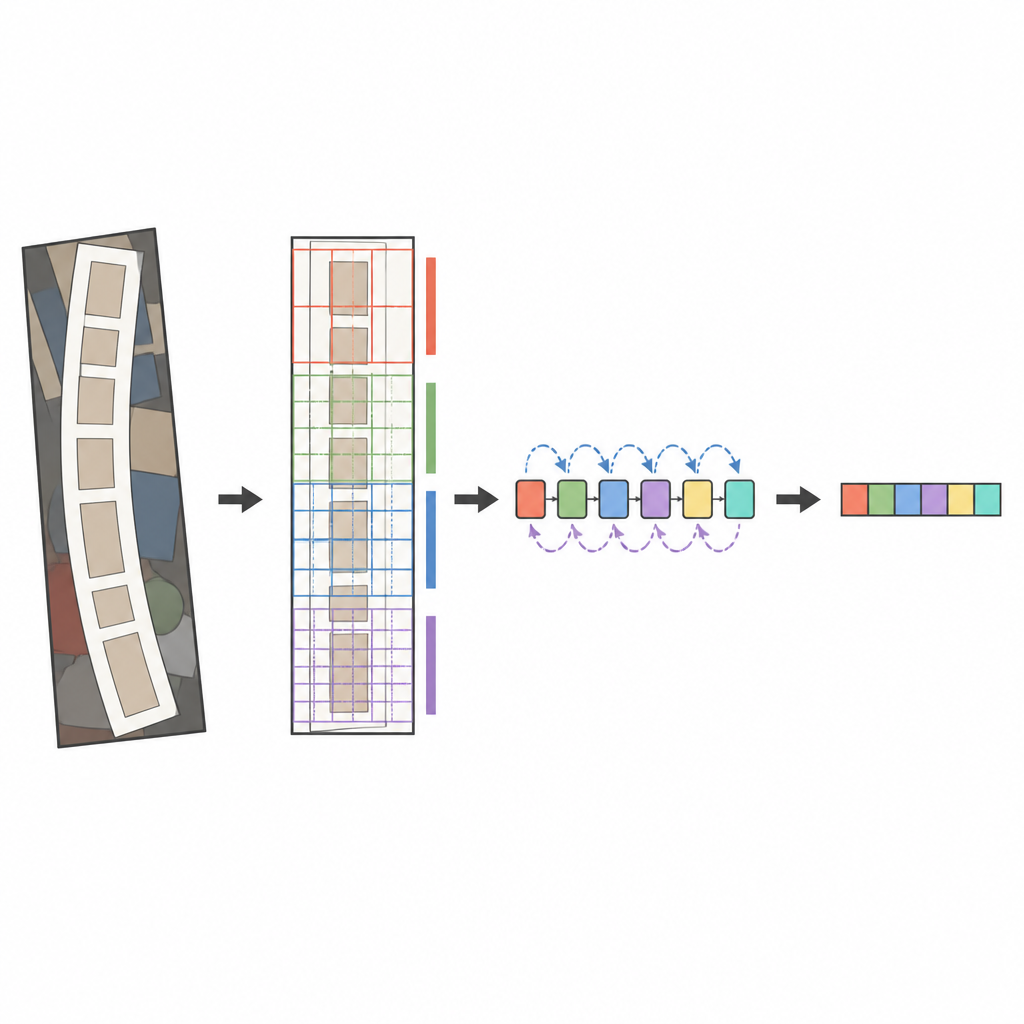
What this means for everyday technology
Put simply, the study shows that a carefully designed image backbone, paired with a smart sequence reader and trained on both fake and real scenes, can read messy real-world text more reliably and quickly. For non-specialists, this means future apps may do a better job of reading street signs through a windshield, recognizing labels in supermarkets, or narrating the contents of a scene for users who cannot see it well. While the system still struggles with extreme blur, heavy glare, and highly stylized fonts, it lays a strong foundation for more robust, flexible text reading tools that operate in the complex visual environments of everyday life.
Citation: Khattab, A., Elpeltagy, M., Youness, F. et al. A hybrid ConvNeXt–BiLSTM framework for robust scene text recognition. Sci Rep 16, 15059 (2026). https://doi.org/10.1038/s41598-026-50234-6
Keywords: scene text recognition, deep learning, ConvNeXt, real-world datasets, computer vision