Clear Sky Science · tr
Hibrit ConvNeXt–BiLSTM çerçevesiyle dayanıklı sahne metni tanıma
Fotoğraflardaki metni okumak neden önemli
Her gün kameralar yol tabelaları, dükkan isimleri, otobüs durakları ve kelimelerle dolu ekran görüntüleri yakalar. Bilgisayarlara bu tür metinleri okumayı öğretmek, navigasyon uygulamalarını güçlendirebilir, görme zorluğu olan kişilere yardımcı olabilir ve dağınık fotoğrafları aranabilir bilgiye dönüştürebilir. Ancak sokaktaki metinler nadiren düzenlidir: eğri, eğik, bulanık veya kalabalık arka planlarda gizlenmiş olabilirler. Bu çalışma, bilgisayarların bu zorlu sahne metinlerini okuması için görüntülere bakma ve sahte ile gerçek örneklerden öğrenme biçimini yeniden tasarlayarak daha akıllı ve daha hızlı bir yöntem sunuyor. 
Temiz taramalardan karmaşık gerçek hayata
Geleneksel metin okuma yazılımları, harflerin düz, temiz sayfalar üzerinde olduğu taranmış belgeler için tasarlanmıştı. Buna karşın sahne metni tanıma, açıyla yakalanmış yol tabelaları, neon logolar, metal üzerindeki yansımalar ve farklı yazı tipleri ile dillerin karışımıyla başa çıkmak zorunda. Geçmiş sistemler büyük ölçüde sentetik verilere dayanıyordu: görüntülere yapay olarak yerleştirilmiş bilgisayar üretimli kelimeler. Bu büyük yapay koleksiyonlar etiketlemesi kolay olsa da gerçek sokakların tüm kaosunu yansıtmaz. Sonuç olarak, test setlerinde iyi performans gösteren modeller kalabalık reklam panoları, eğri dükkan isimleri veya düşük ışık koşullarıyla karşılaştıklarında başarısız olabiliyor. Yazarlar, ilerlemenin artık hem daha iyi görüntü işlemeye hem de daha zengin gerçek dünya örneklerine bağlı olduğunu savunuyor.
Görüntülerdeki kelimelere bakmanın yeni yolu
Önerilen sistemin çekirdeği, ConvNeXt adlı modern bir görüntü analizcisi ile çift yönlü LSTM olarak bilinen bir sıra okuyucunun birleşimidir. Görüntü analiz edilmeden önce, eğri veya bükülmüş metni nazikçe düzelten özel bir dönüşüm aşaması olur; böylece metin daha yatay bir kelime gibi görünür. ConvNeXt daha sonra görüntüyü birçok küçük parçaya ayırır ve ince çizgileri, karakter şekillerini ve kelimelerin daha uzun yatay akışını yakalayan desenleri öğrenirken dikkat dağıtan arka plan karmaşasını görmezden gelir. Ek modüller ağın küresel bağlam ile yerel detay arasındaki dengeyi kurmasına ve harflerin gerçekte bulunduğu gibi en bilgi verici bölgelere odaklanmasına yardımcı olur. Son olarak, sıra okuyucu bu özellikleri soldan sağa ve sağdan sola tarar ve dikkat tabanlı bir çözücü en olası karakter dizimini birer sembol halinde heceleyerek çıkartır.
Sistemi sahte ve gerçek kelimelerle öğretmek
Böyle bir sistemi eğitmek büyük sayıda etiketli örnek gerektirir. Yazarlar iki aşamalı bir strateji kullanıyor. Önce, yazı tipleri, boyutlar ve bozulmalarda büyük çeşitlilik sunan milyonlarca sentetik kelime görüntüsü üzerinde ön eğitim yapıyorlar. Bu aşamada, öğrenmeyi zor örneklere odaklayan ve modelin tek bir tahmine aşırı güvenmesini engelleyen bir kayıp fonksiyonu uygulanıyor. Ardından, uluslararası yarışmalardan ve açık görüntü projelerinden derlenen büyük bir gerçek dünya veri seti koleksiyonu üzerinde ince ayar yapılıyor. Bu veri setleri düz ve eğri metinleri, birden fazla dili, ev numaralarını ve farklı ışık ve hava koşullarındaki tabelaları içeriyor. Ekip, modelin dengeli bir örnek karması görmesini ve herhangi bir kaynağa fazla uyum sağlamamasını sağlamak için örnekleri dikkatle yeniden boyutlandırıyor, filtreliyor ve dengeliyor.
Pratikte ne kadar iyi çalışıyor
Altı yaygın kullanılan benchmark üzerinde test edildiğinde, yeni çerçeve sentetik ve gerçek verilerle eğitildiğinde ortalama yaklaşık %94,7 doğruluk elde ediyor; bu, yalnızca sentetik verilerle eğitilmiş sürümünün oldukça ileride ve benzer koşullar altında eğitilmiş diğer önde gelen yöntemlerle rekabetçi veya daha iyi durumda. Ayrıntılı bir döküm, eklenen normalizasyon ve dikkat bloklarının özellikle eğri veya eğik kelimeler gibi düzensiz metinlerde ve karmaşık arka planlarda yardımcı olduğunu gösteriyor. Aynı zamanda sistem görece hafif kalıyor: yaklaşık 20 milyon parametre kullanıyor ve modern bir grafik kartında bir kelime görüntüsünü birkaç milisaniyenin binde birinde okuyabiliyor. Hız ve doğruluk arasındaki bu denge, sürücü yardım sistemleri veya mobil cihazlarda canlı çeviri gibi gerçek zamanlı uygulamalar için uygun hale getiriyor. 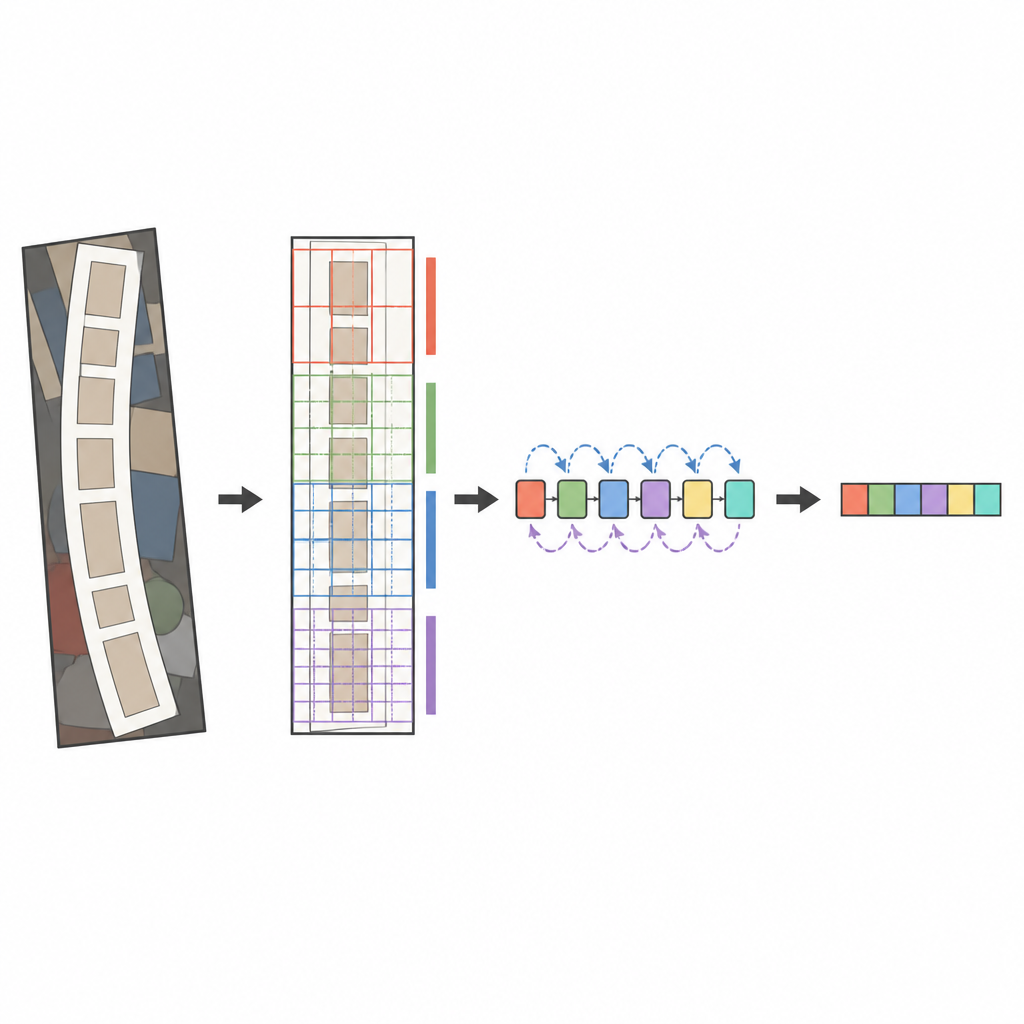
Günlük teknoloji için anlamı
Basitçe söylemek gerekirse, çalışma, dikkatle tasarlanmış bir görüntü omurgası ile akıllı bir sıra okuyucunun ve hem sahte hem gerçek sahnelerle eğitimin dağınık gerçek dünya metinlerini daha güvenilir ve hızlı bir şekilde okuyabileceğini gösteriyor. Uzman olmayan kullanıcılar için bu, gelecekteki uygulamaların bir ön camdan geçen yol tabelalarını daha iyi okuması, süpermarketlerde etiketleri tanıması veya sahnenin içeriğini iyi göremeyen kullanıcılar için anlatması anlamına gelebilir. Sistem yine de aşırı bulanıklık, yoğun parlama ve son derece stilize yazı tipleriyle zorlanıyor, ancak günlük yaşamın karmaşık görsel ortamlarında çalışan daha sağlam, esnek metin okuma araçları için sağlam bir temel oluşturuyor.
Atıf: Khattab, A., Elpeltagy, M., Youness, F. et al. A hybrid ConvNeXt–BiLSTM framework for robust scene text recognition. Sci Rep 16, 15059 (2026). https://doi.org/10.1038/s41598-026-50234-6
Anahtar kelimeler: sahne metni tanıma, derin öğrenme, ConvNeXt, gerçek dünya veri setleri, bilgisayarla görme