Clear Sky Science · es
Un marco híbrido ConvNeXt–BiLSTM para el reconocimiento robusto de texto en escenas
Por qué importa leer texto en fotografías
Cada día, las cámaras capturan señales de la calle, nombres de comercios, paradas de autobús y pantallazos llenos de palabras. Enseñar a las máquinas a leer ese tipo de texto puede impulsar aplicaciones de navegación, ayudar a personas con baja visión y convertir fotos desordenadas en información buscable. Sin embargo, el texto en el mundo real rara vez está ordenado: puede estar curvado, inclinado, borroso o oculto en fondos cargados. Este estudio presenta una manera más inteligente y rápida para que los ordenadores lean texto tan desafiante, rediseñando cómo analizan las imágenes y cómo aprenden a partir de ejemplos tanto artificiales como reales. 
De escaneos limpios a la vida real desordenada
El software tradicional de lectura de texto se diseñó para documentos escaneados, donde las letras aparecen sobre páginas planas y limpias. El reconocimiento de texto en escenas, en cambio, debe lidiar con señales de carretera tomadas en ángulo, logotipos de neón, reflejos en metal y una mezcla de tipografías e idiomas. Los sistemas anteriores dependían en gran medida de datos sintéticos: palabras generadas por ordenador pegadas en imágenes. Estas grandes colecciones artificiales son fáciles de etiquetar pero carecen del caos completo de las calles reales. Como resultado, los modelos que funcionan bien en conjuntos de prueba pueden fallar ante vallas publicitarias abarrotadas, nombres de tiendas curvados o poca luz. Los autores sostienen que el progreso ahora depende tanto de un mejor procesamiento de imágenes como de una dieta más rica de ejemplos del mundo real.
Una nueva forma de mirar las palabras en las imágenes
El núcleo del sistema propuesto es un analizador de imágenes moderno llamado ConvNeXt, combinado con un lector de secuencias conocido como LSTM bidireccional. Antes de analizar la imagen, una etapa de transformación especial endereza suavemente el texto deformado o curvado para que se parezca más a una palabra horizontal. ConvNeXt divide entonces la imagen en muchas piezas pequeñas y aprende patrones que capturan trazos finos, formas de caracteres y el flujo horizontal más amplio de las palabras, mientras ignora el desorden del fondo. Módulos adicionales ayudan a la red a equilibrar el contexto global frente al detalle local y a centrar su atención en las regiones más informativas, como donde aparecen realmente las letras. Finalmente, el lector de secuencias explora estas características de izquierda a derecha y de derecha a izquierda, y un decodificador basado en atención deletrea la secuencia de caracteres más probable símbolo por símbolo.
Enseñar al sistema con palabras falsas y reales
Entrenar un sistema así requiere enormes cantidades de ejemplos etiquetados. Los autores utilizan una estrategia en dos pasos. Primero, preentrenan con millones de imágenes de palabras sintéticas, que ofrecen una gran variedad de tipografías, tamaños y distorsiones. Durante esta etapa aplican una función de pérdida que concentra el aprendizaje en ejemplos difíciles y evita que el modelo se vuelva demasiado confiado en una sola predicción. Después, afinan el modelo con una amplia colección de conjuntos de datos del mundo real recopilados de competiciones internacionales y proyectos de imágenes abiertas. Estos conjuntos incluyen texto recto y curvado, múltiples idiomas, números de domicilios y señales bajo distintas condiciones de iluminación y clima. El equipo ajusta cuidadosamente el tamaño, filtra y equilibra las muestras para que el modelo vea una mezcla justa de casos y no sobreajuste a una sola fuente.
Qué tan bien funciona en la práctica
Probado en seis bancos de pruebas ampliamente usados, el nuevo marco alcanza una precisión media de aproximadamente 94,7 por ciento cuando se entrena con datos sintéticos y reales, claramente por delante de su versión entrenada solo con sintéticos y competitivo o mejor que otros métodos líderes entrenados en condiciones similares. Un desglose detallado muestra que los bloques adicionales de normalización y atención ayudan especialmente con texto irregular, como palabras curvadas o inclinadas sobre fondos complejos. Al mismo tiempo, el sistema sigue siendo relativamente ligero: usa alrededor de 20 millones de parámetros y puede leer una imagen de palabra en unos pocos milisegundos en una tarjeta gráfica moderna. Este equilibrio entre velocidad y precisión lo hace apto para usos en tiempo real como asistencia al conductor o traducción en vivo en dispositivos móviles. 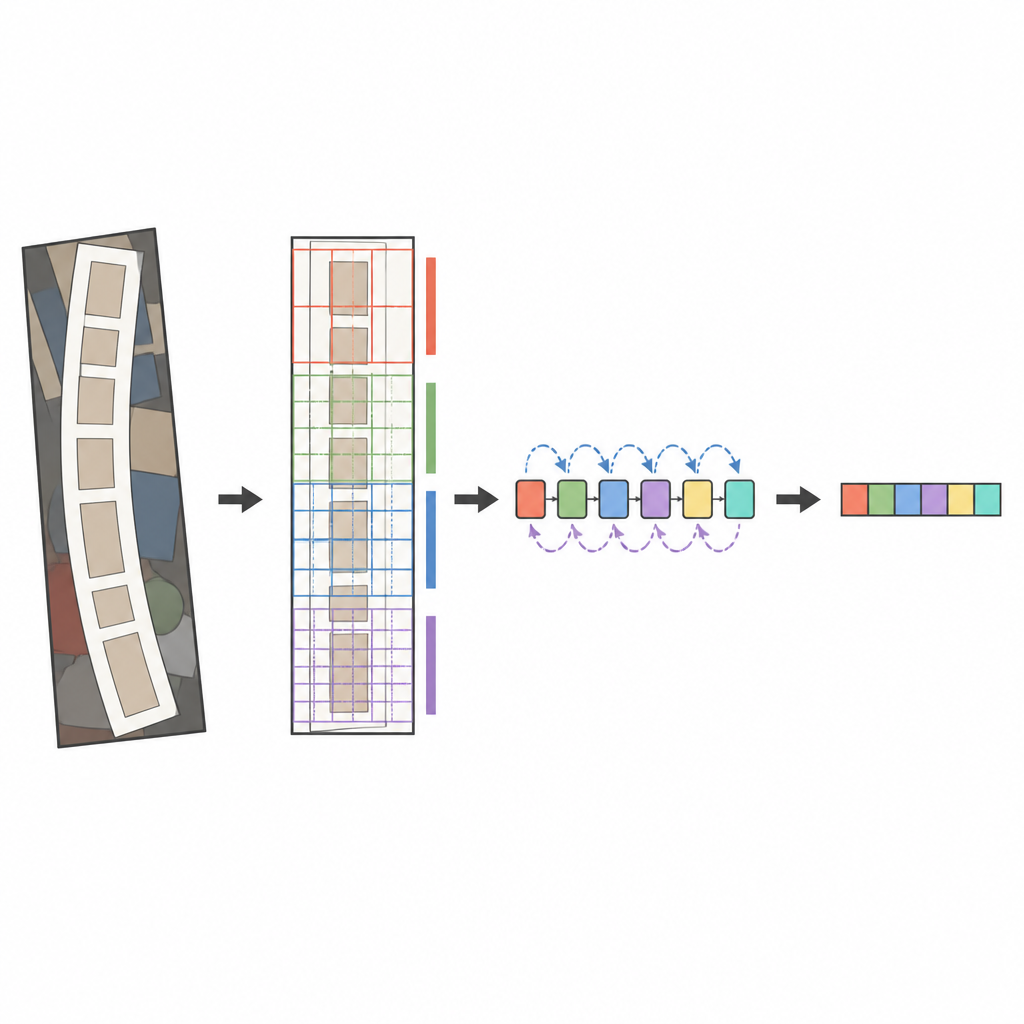
Qué significa esto para la tecnología cotidiana
En términos simples, el estudio muestra que una columna vertebral de imagen cuidadosamente diseñada, combinada con un lector de secuencias inteligente y entrenada con escenas tanto falsas como reales, puede leer texto del mundo real más desordenado de forma más fiable y rápida. Para los no especialistas, esto significa que futuras aplicaciones podrían hacer un mejor trabajo al leer señales de la calle a través del parabrisas, reconocer etiquetas en supermercados o narrar el contenido de una escena para usuarios con baja visión. Aunque el sistema aún tiene dificultades con desenfoque extremo, reflejos intensos y tipografías muy estilizadas, sienta una base sólida para herramientas de lectura de texto más robustas y flexibles que operen en los complejos entornos visuales de la vida cotidiana.
Cita: Khattab, A., Elpeltagy, M., Youness, F. et al. A hybrid ConvNeXt–BiLSTM framework for robust scene text recognition. Sci Rep 16, 15059 (2026). https://doi.org/10.1038/s41598-026-50234-6
Palabras clave: reconocimiento de texto en escenas, aprendizaje profundo, ConvNeXt, conjuntos de datos del mundo real, visión por computador