Clear Sky Science · zh
通过分类引导的大型视觉-语言模型从文档中提取视觉信息
帮助计算机识别杂乱的纸质材料
现代办公室被大量数字化的纸质材料淹没——执照、身份证、证书、收据等常以扫描件或照片形式保存。这些图片中隐藏着诸如姓名、日期和证件号码等关键事实,需要被核对并录入数据库。人工重键这些信息既慢又易出错,而现有的自动化系统在面对杂乱的布局、印章、模糊或多样的文档样式时仍然吃力。本文提出了一种新方法,使人工智能在更少人工标注和配置的情况下,更准确地“读取”此类文档。
传统工具为何不足
大多数现有系统将文档理解视为严格的流水线。首先,光学字符识别(OCR)引擎尝试在图像中定位并识别每一段文字。然后第二个模型分析这些文本以确定哪些信息重要——例如公司名称或证书编号。在干净、统一的表单上这套做法还算可行,但当文档在布局上变化、包含表格或被印章、水印或光照问题遮挡时就会失效。改进这些系统通常意味着为每种新文档类型收集大量标注样本,并为每种情况精心设计规则或模型,这既昂贵又难以扩展。
对视觉-语言模型的更智能引导
大型视觉-语言模型(LVLM)能够查看图像并生成文本,类似于能“看见”的强大助手。原则上,它们可以直接读取文档,而不依赖单独的OCR引擎。然而,当用一条通用指令喂给许多不同类型文档时,这些模型常常会迷惑,杜撰不存在的值或漏掉细节。作者提出了一个“分类引导”框架,将整体任务拆成两步:首先,快速判断图像属于哪种文档;其次,基于该判断构建定制提示,告诉LVLM要提取哪些字段以及如何格式化答案。此设计使模型每次只需聚焦于更狭窄、更清晰的任务,而非同时在所有可能的表单中猜测。
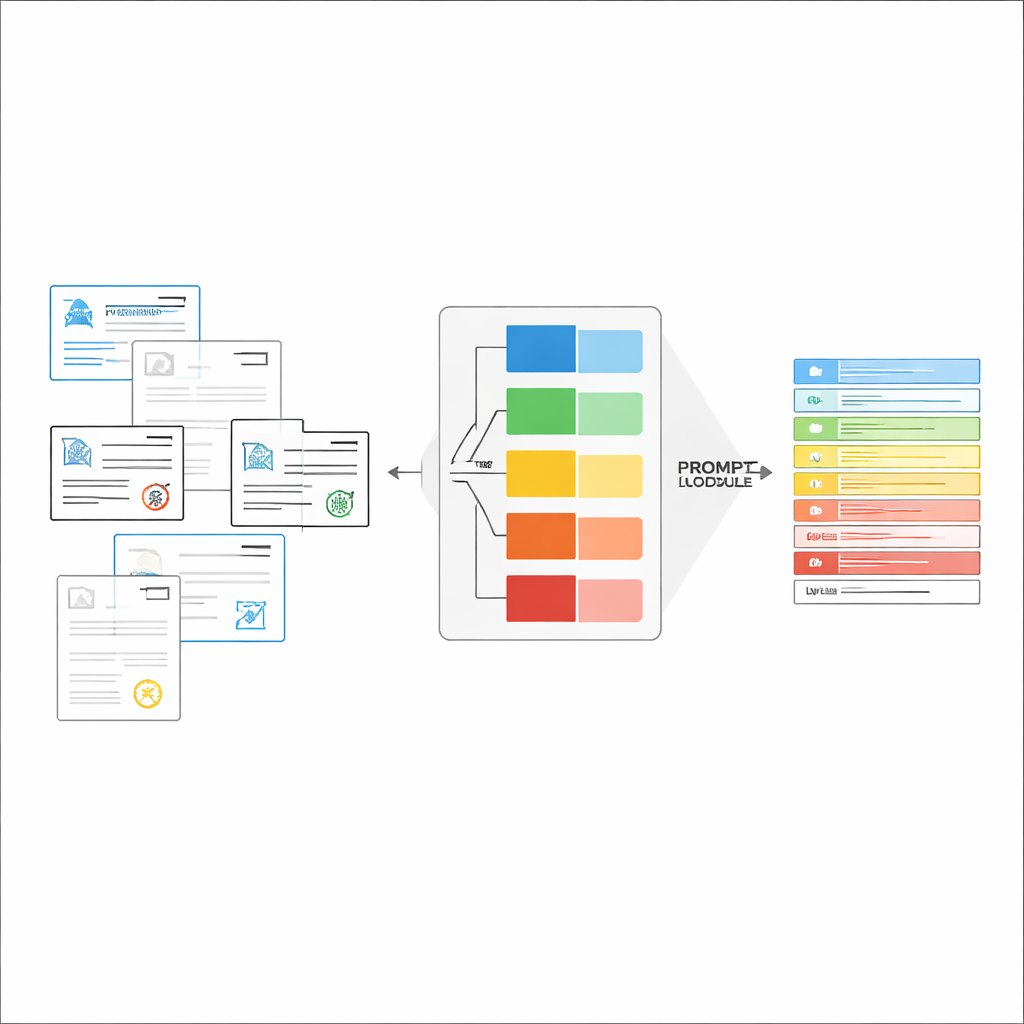
即刻构建恰当的指令
一旦识别出文档类型,系统会为LVLM组装一段简短的定制指令。提示的共通部分说明一般任务——提取特定条目、遵循严格的JSON结构、使用一致的日期格式,并将不可读取的字段标记为“未识别”。在此之上加入类型特定的内容:该证件所需字段的精确列表以及若干输入输出示例,展示正确提取的样式。这种上下文学习为每种文档类型提供了具体示范,而无需改变模型的内部参数。作者基于信息论的思想展示了,如此聚焦的提示像“条件计算”:它们剔除无关指令、减少模型注意力的干扰,并更高效地利用每个生成的标记。
在招标文件上的真实世界测试
为检验该方法的实际效果,研究者从电子招标平台构建了一个大规模、逼真的数据集,包含近10万张图像,涵盖16种证件,从营业执照和社会保障记录到安全与质量认证。这些文档在布局复杂度、文本量和视觉噪声上差异很大。新框架在两种模式下进行了测试:纯零样本(zero-shot),使用带有新提示策略的现成LVLM;以及使用轻量级训练技术适配领域的微调版本。在两种情况下,他们都与一个强基线比较,该基线结合了最先进的OCR与现代信息提取模型。
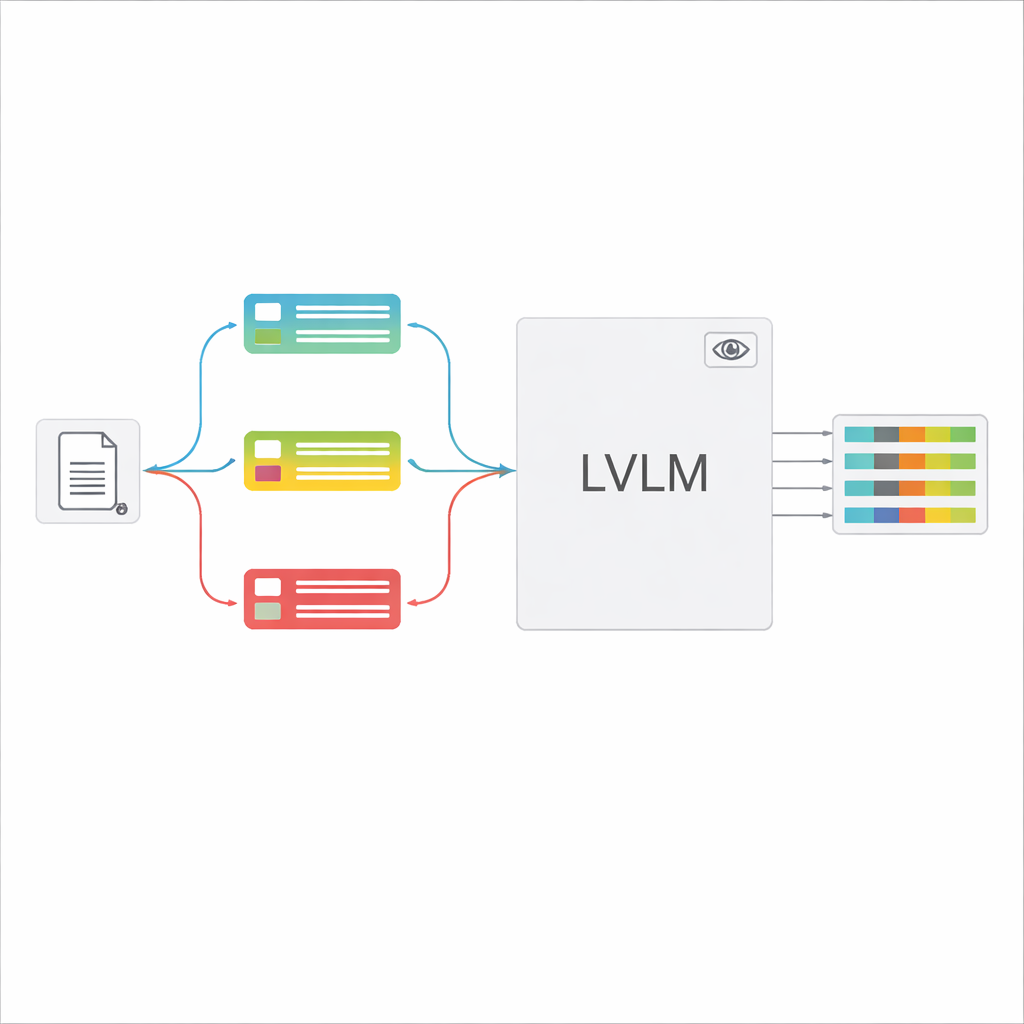
更高准确率且人工成本更低
结果引人注目。即使在未进行微调的情况下,分类引导的LVLM在F1分数(一种常用的准确率度量)上也比监督式OCR管道高出18个百分点以上,并且提高了提取文本与真实值的匹配度。经过领域特定的微调后,LVLM框架可达93%以上的F1,能比传统方法更好地处理重水印、低对比度和密集表格等棘手情况。细致的实验表明,文档类型分类器和提示示例尤其重要:移除它们会导致准确率大幅下降,这支持了针对性、与输入相关的提示是关键的观点。
对日常文档工作的意义
通俗地说,这项研究展示了如何把一个通用的“看与说”AI变成一个可靠的办公助手,能够以最少的定制设置阅读多种官方文件。通过先问“这是什么类型的表单?”,然后给模型一组简短、有针对性的示例和说明,系统在准确性和易部署性上都得到提升。这种方法可简化合规检查、招标审查和后台数据录入等任务,也提示了一个更广泛的教训:用恰当的上下文智能引导大型模型,可以与增大模型规模或从头训练同样强大。
引用: Li, H., Chen, G., Xia, J. et al. Visual information extraction from documents via classification-guided large vision-language models. Sci Rep 16, 14158 (2026). https://doi.org/10.1038/s41598-026-49319-z
关键词: 文档理解, 信息提取, 视觉-语言模型, 办公自动化, 提示工程