Clear Sky Science · ar
استخراج المعلومات البصرية من المستندات عبر نماذج رؤية-لغة كبيرة موجهة بواسطة التصنيف
مساعدة الحواسيب على قراءة المستندات المبعثرة
تغرق المكاتب الحديثة في أوراق رقمية—تراخيص، بطاقات هوية، شهادات، إيصالات—غالباً ما تُخزن كصور ممسوحة ضوئياً أو صور فوتوغرافية. وتحتوي هذه الصور على حقائق مهمة مثل الأسماء والتواريخ وأرقام الهوية التي يجب التحقق منها ونسخها إلى قواعد البيانات. إعادة كتابة هذه المعلومات يدوياً بطيئة ومعرضة للأخطاء، بينما لا تزال الأنظمة الآلية الحالية تكافح مع تخطيطات مزدحمة، وختمات، وتمويه، وأنماط مستندات متعددة. تقدم هذه الورقة طريقة جديدة لتمكين الذكاء الاصطناعي من "قراءة" مثل هذه المستندات بدقة أكبر وبحاجة أقل لتوسيم وإعداد يدوي.
لماذا تفشل الأدوات التقليدية
تعامل معظم الأنظمة الحالية فهم المستندات كسلسلة إنتاج صارمة. أولاً، يحاول محرك التعرف الضوئي على الحروف (OCR) اكتشاف وقراءة كل نص في الصورة. ثم يقوم نموذج ثانٍ بتحليل ذلك النص لتحديد الأجزاء المهمة—مثل اسم الشركة أو رقم الشهادة. يعمل هذا بشكل معقول على النماذج النظيفة والمتجانسة، لكنه ينهار عندما تختلف المستندات في التخطيط، أو تحتوي على جداول، أو تغطيها أختام أو علامات مائية أو إضاءة سيئة. تحسين هذه الأنظمة يعني عادةً جمع أمثلة موسومة كثيرة لكل نوع مستند جديد وتصميم قواعد أو نماذج لكل حالة بعناية، وهو أمر مكلف ويصعب توسيعه.
طريقة أذكى لتوجيه نماذج الرؤية-اللغة
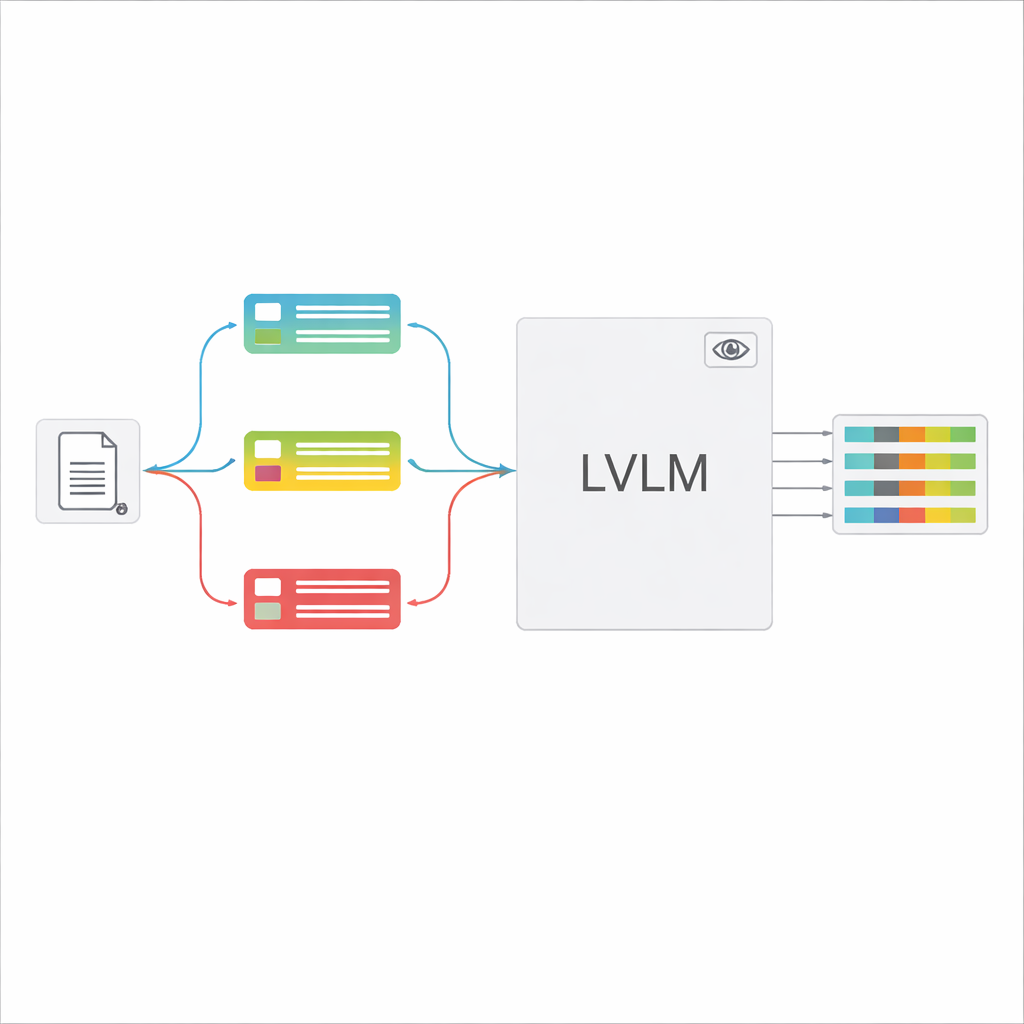
يمكن لنماذج الرؤية-اللغة الكبيرة (LVLMs) أن تُنظر إلى صورة وتولد نصاً، مثل المساعدين الأقوياء القادرين على "الرؤية". من حيث المبدأ، يمكنها قراءة المستندات مباشرة دون حاجة لمحرك OCR منفصل. ومع ذلك، عند تزويدها بأنواع مستندات متعددة وتعليمات عامة واحدة، غالباً ما ترتبك هذه النماذج أو تُنتج قيماً غير موجودة أو تفشل في التقاط تفاصيل دقيقة. يقترح المؤلفون إطاراً "موجهاً بواسطة التصنيف" يكسر المهمة العامة إلى خطوتين: أولاً، تحديد نوع المستند بسرعة؛ ثانياً، استخدام هذا القرار لبناء مطالبة مخصصة تخبر النموذج بالحقول التي يجب استخراجها وكيفية صياغة الإجابات. يسمح هذا التصميم للنموذج بالتركيز على مهمة أضيق وأكثر وضوحاً في كل مرة بدلاً من التخمين بين كل النماذج المحتملة دفعة واحدة.
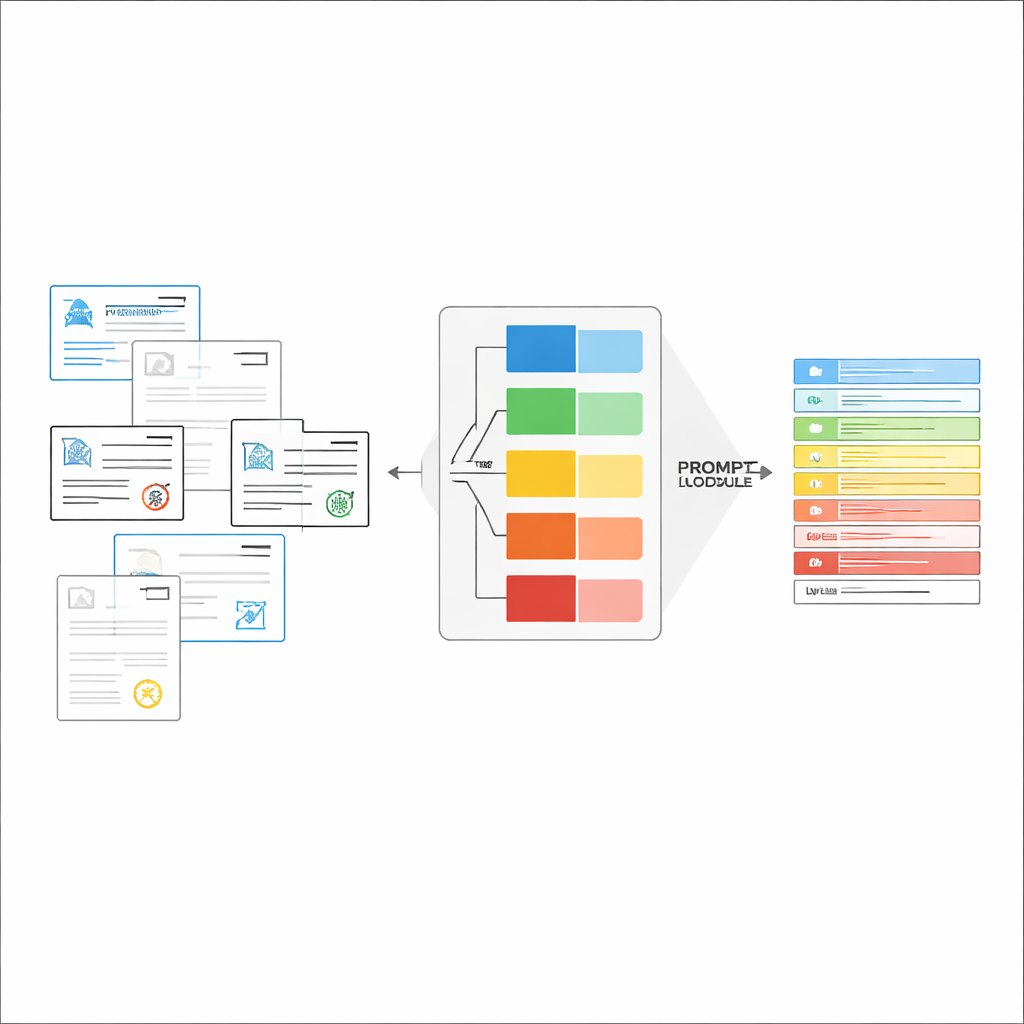
بناء تعليمات مناسبة في الوقت المناسب
بمجرد التعرف على نوع المستند، يجمع النظام تعليمات قصيرة ومخصصة للنموذج. جزء مشترك من المطالبة يشرح المهمة العامة—استخراج عناصر محددة، احترام بنية JSON صارمة، استخدام صيغ تواريخ متسقة، ووضع علامة "غير محدد" على الحقول غير القابلة للقراءة. فوق ذلك تُضاف قطع خاصة بالنوع: القائمة الدقيقة بالحقول المطلوبة لتلك الشهادة وبعض أمثلة المدخلات والمخرجات التي تُظهر الشكل الصحيح للاستخراج. يمنح هذا التعلم داخل السياق النموذج أمثلة ملموسة لكل نوع مستند دون تغيير معاييره الداخلية. يوضح المؤلفون، مستفيدين من أفكار من نظرية المعلومات، أن مثل هذه المطالبات المركزة تعمل كـ"حساب شرطي": فهي تزيل التعليمات غير ذات الصلة، تقلل التشتت في انتباه النموذج، وتجعل استخدام كل رمز مُولد أكثر فعالية.
اختبارات واقعية على مستندات المناقصات
لمعرفة مدى فعالية هذا في الممارسة، بنى الباحثون مجموعة بيانات كبيرة وواقعية من منصة مناقصات إلكترونية، تحتوي على ما يقرب من 100,000 صورة تغطي 16 نوعاً من الشهادات، من تراخيص الأعمال وسجلات الضمان الاجتماعي إلى شهادات السلامة والجودة. تختلف هذه المستندات بشكل كبير في تعقيد التخطيط، وكمية النص، والضوضاء البصرية. اختُبر الإطار الجديد في وضعين: سجل صفري بحت (zero-shot) باستخدام نموذج LVLM جاهز مع استراتيجية المطالبة الجديدة، وإصدار دقيق مُكيف مع المجال باستخدام تقنية تدريب خفيفة الوزن. في كلتا الحالتين، قورن بأحد خطوط الأساس القوية التي تجمع بين أحدث محركات OCR ونموذج استخراج معلومات عصري.
قفزات كبيرة في الدقة مع جهد يدوي أقل
النتائج ملفتة. حتى بدون ضبط دقيق، يتفوق النموذج الموجه بواسطة التصنيف على خط الأنابيب الخاضع للإشراف المعتمد على OCR بأكثر من 18 نقطة مئوية في مقياس F1 (مقياس شائع للدقة) ويحسن مدى تطابق النص المستخرج مع الحقيقة المرجعية. مع التكييف الإضافي الخاص بالمجال، يصل إطار LVLM إلى أكثر من 93% في F1، مع تعامل أفضل بكثير مع الحالات الصعبة مثل العلامات المائية الثقيلة، والتباين المنخفض، والجداول الكثيفة مقارنةً بالنهج التقليدي. تُظهر تجارب دقيقة أن مُصنف نوع المستند وأمثلة المطالبة لهما أهمية خاصة: إزالتها يتسبب في هبوط كبير في الدقة، مما يدعم فكرة أن المطالبات الموجهة وواعية الإدخال هي المفتاح.
ماذا يعني هذا لعمل المستندات اليومي
بشكل عملي، تُظهر هذه الدراسة كيفية تحويل ذكاء اصطناعي عام القادر على "الرؤية والتحدث" إلى مساعد مكتبي موثوق يمكنه قراءة أنواع عديدة من المستندات الرسمية مع إعداد مخصص ضئيل. من خلال طرح سؤالين فقط—"ما نوع الاستمارة هذه؟" ثم إعطاء النموذج مجموعة قصيرة ومخصصة من الأمثلة والتعليمات—يصبح النظام أكثر دقة وأسهل للنشر على نطاق واسع. يمكن لهذا النهج تبسيط مهام مثل فحوصات الامتثال، مراجعات العطاءات، وإدخال البيانات الخلفي، ويشير إلى درس أوسع: توجيه النماذج الكبيرة بالسياق المناسب يمكن أن يكون فعالاً بقدر جعلها أكبر أو تدريبها من البداية.
الاستشهاد: Li, H., Chen, G., Xia, J. et al. Visual information extraction from documents via classification-guided large vision-language models. Sci Rep 16, 14158 (2026). https://doi.org/10.1038/s41598-026-49319-z
الكلمات المفتاحية: فهم المستندات, استخراج المعلومات, نماذج رؤية-لغة, أتمتة المكاتب, هندسة المطالبات