Clear Sky Science · it
Estrazione di informazioni visive dai documenti tramite grandi modelli visione‑linguaggio guidati da classificazione
Aiutare i computer a leggere documenti disordinati
Gli uffici moderni sono sommersi da pratiche digitali—licenze, documenti d'identità, certificati, ricevute—spesso conservate come immagini scannerizzate o fotografie. In queste immagini sono nascosti fatti chiave come nomi, date e numeri identificativi che devono essere controllati e copiati nei database. Trascrivere manualmente queste informazioni è lento e soggetto a errori, mentre i sistemi automatici attuali faticano con layout affollati, timbri, sfocature e i molteplici stili di documento. Questo articolo introduce un nuovo metodo per permettere all'IA di “leggere” tali documenti in modo più accurato con meno etichettatura e configurazione umana.
Perché gli strumenti tradizionali non bastano
La maggior parte dei sistemi esistenti tratta la comprensione dei documenti come una catena di montaggio rigorosa. Prima, un motore di riconoscimento ottico dei caratteri (OCR) cerca e legge ogni testo presente nell'immagine. Poi un secondo modello analizza quel testo per decidere quali parti sono importanti—per esempio il nome dell'azienda o il numero del certificato. Questo funziona abbastanza bene su formulari puliti e uniformi, ma si rompe quando i documenti variano nel layout, contengono tabelle o sono coperti da sigilli, filigrane o cattiva illuminazione. Migliorare questi sistemi di solito significa raccogliere molti esempi etichettati per ogni nuovo tipo di documento e progettare regole o modelli specifici per ogni caso, il che è costoso e difficile da scalare.
Un modo più intelligente per guidare i modelli visione‑linguaggio
I grandi modelli visione‑linguaggio (LVLM) possono guardare un'immagine e generare testo, un po' come potenti assistenti che possono “vedere”. In linea di principio potrebbero leggere i documenti direttamente, senza un motore OCR separato. Tuttavia, se alimentati con molti tipi di documento e un'istruzione generica, questi modelli spesso si confondono, inventano valori non presenti o perdono dettagli fini. Gli autori propongono un quadro “guidato dalla classificazione” che divide il compito in due passi: prima, decidere rapidamente che tipo di documento è l'immagine; secondo, usare quella decisione per costruire un prompt su misura che dica al LVLM esattamente quali campi estrarre e come formattare le risposte. Questo design consente al modello di concentrarsi ogni volta su un compito più ristretto e chiaro invece di indovinare tra tutte le possibili forme contemporaneamente.
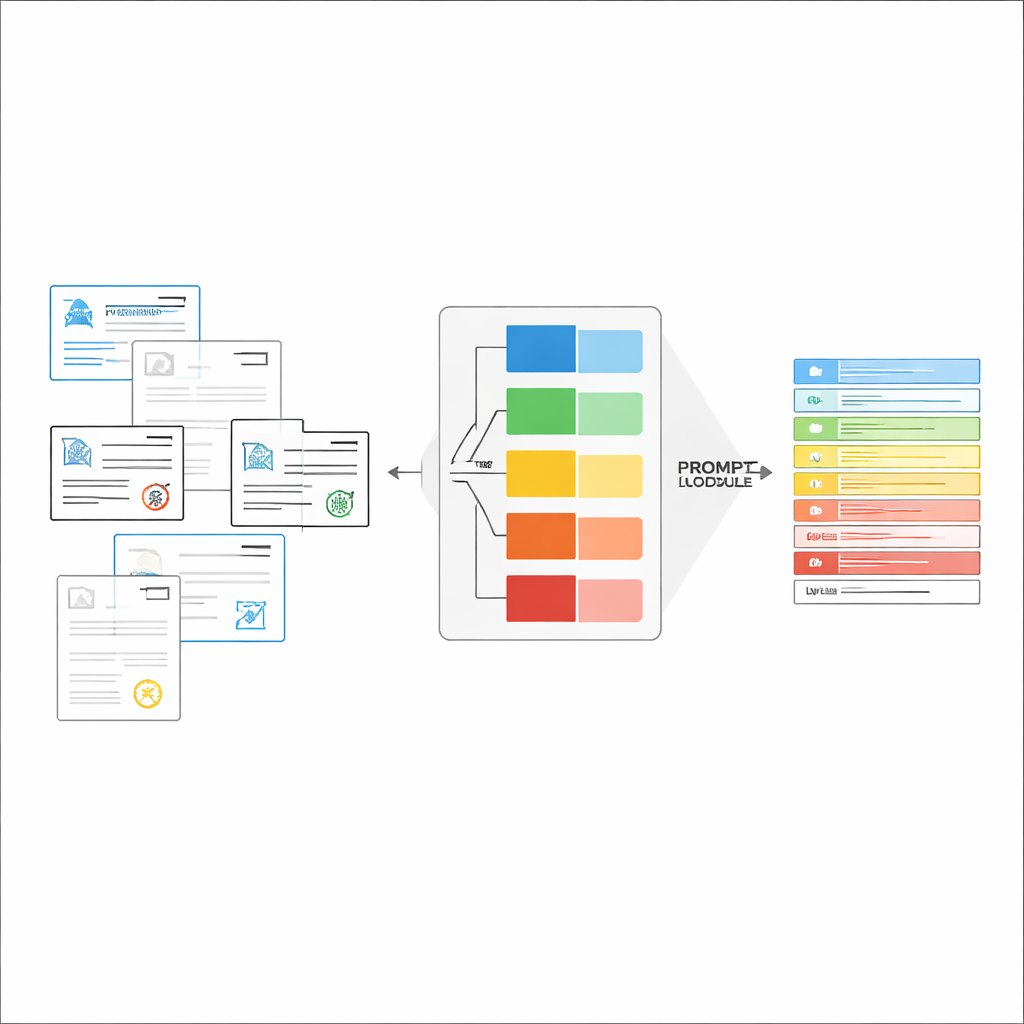
Costruire istruzioni giuste al momento
Una volta riconosciuto il tipo di documento, il sistema compone un'istruzione breve e personalizzata per il LVLM. Una parte condivisa del prompt spiega il lavoro generale—estrarre elementi specifici, rispettare una struttura JSON rigorosa, usare formati di data coerenti e segnare i campi illeggibili come “non identificato”. A questo si aggiungono elementi specifici per tipo: l'elenco esatto dei campi necessari per quel certificato e alcuni esempi di input e output che mostrano come deve apparire un'estrazione corretta. Questo apprendimento in‑context fornisce al LVLM dimostrazioni concrete per ogni tipo di documento senza modificare i suoi parametri interni. Gli autori dimostrano, usando idee dalla teoria dell'informazione, che prompt così mirati funzionano come una “computazione condizionata”: eliminano istruzioni irrilevanti, riducono le distrazioni nell'attenzione del modello e fanno un uso migliore di ogni token generato.
Test nel mondo reale su documenti di gara
Per valutare l'efficacia pratica, i ricercatori hanno costruito un grande dataset realistico da una piattaforma di gara elettronica, contenente quasi 100.000 immagini che coprono 16 tipi di certificati, dalle licenze commerciali e documenti previdenziali a certificazioni di sicurezza e qualità. Questi documenti differiscono ampiamente per complessità del layout, quantità di testo e rumore visivo. Il nuovo quadro è stato testato in due modalità: totalmente zero‑shot, usando un LVLM disponibile con la nuova strategia di prompting, e una versione fine‑tuned adattata al dominio tramite una tecnica di addestramento leggera. In entrambi i casi è stato confrontato con un forte baseline che combinava un OCR all'avanguardia con un moderno modello di estrazione delle informazioni.
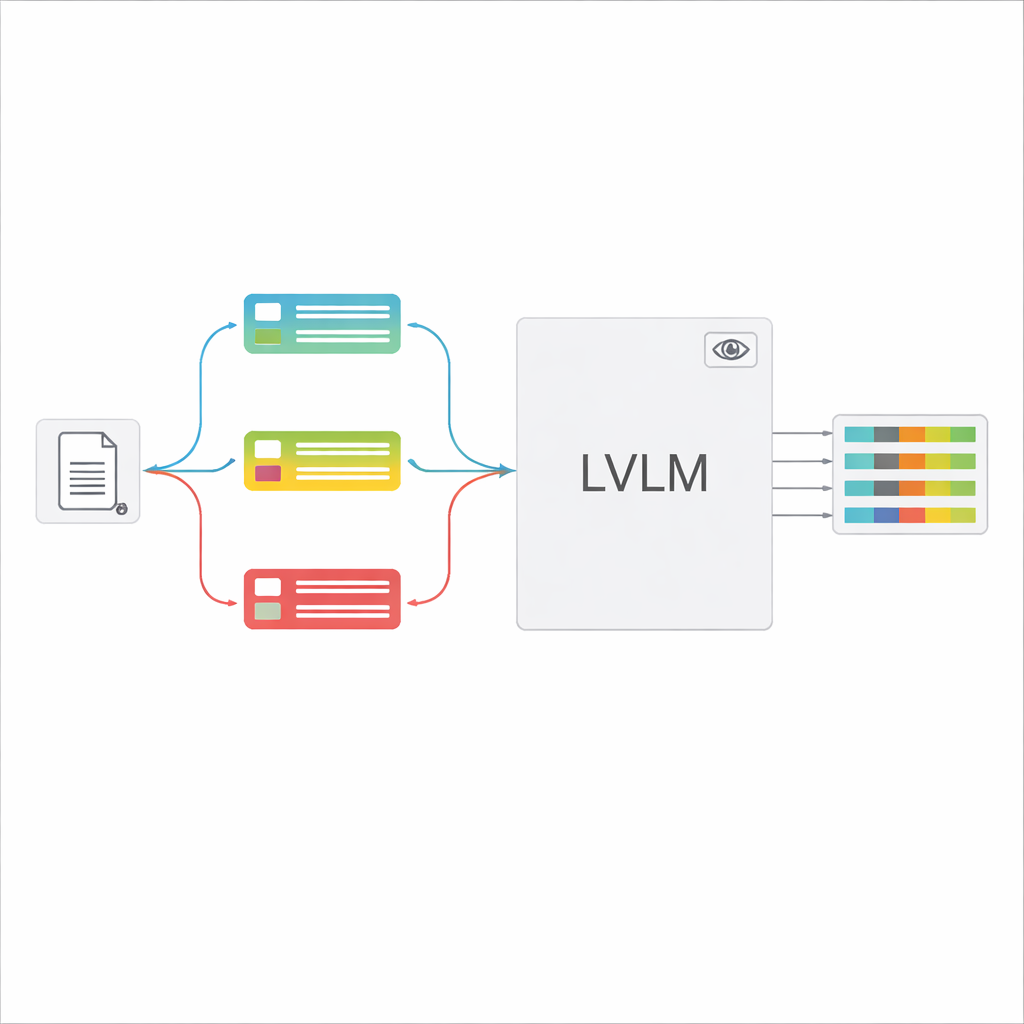
Grandi guadagni di accuratezza con meno lavoro manuale
I risultati sono notevoli. Anche senza fine‑tuning, il LVLM guidato dalla classificazione supera la pipeline supervisionata basata su OCR di oltre 18 punti percentuali in F1‑score (una misura comune di accuratezza) e migliora quanto il testo estratto corrisponde al ground truth. Con un fine‑tuning specifico per il dominio, il framework LVLM raggiunge oltre il 93% di F1, gestendo casi difficili come forti filigrane, basso contrasto e tabelle dense molto meglio dell'approccio tradizionale. Esperimenti accurati mostrano che il classificatore del tipo di documento e gli esempi nel prompt sono particolarmente importanti: rimuoverli provoca grandi cali di accuratezza, a sostegno dell'idea che prompt mirati e consapevoli dell'input siano la chiave.
Cosa significa per il lavoro quotidiano con i documenti
In termini pratici, questa ricerca mostra come trasformare un'IA generalista che può “vedere e parlare” in un assistente d'ufficio affidabile in grado di leggere molti tipi di documenti ufficiali con una personalizzazione minima. Chiedendo prima “che tipo di modulo è?” e poi fornendo al modello un breve insieme di esempi e istruzioni su misura, il sistema diventa sia più accurato sia più facile da distribuire su larga scala. Questo approccio potrebbe snellire attività come controlli di conformità, revisioni di gare e inserimento dati di back‑office, e suggerisce una lezione più ampia: guidare intelligentemente i grandi modelli con il contesto giusto può essere efficace quanto renderli più grandi o addestrarli da zero.
Citazione: Li, H., Chen, G., Xia, J. et al. Visual information extraction from documents via classification-guided large vision-language models. Sci Rep 16, 14158 (2026). https://doi.org/10.1038/s41598-026-49319-z
Parole chiave: comprensione dei documenti, estrazione delle informazioni, modelli visione‑linguaggio, automazione d'ufficio, prompt engineering