Clear Sky Science · tr
Belgelerden sınıflandırma yoluyla yönlendirilen büyük görsel-dil modelleri ile görsel bilgi çıkarımı
Bilgisayarların Karışık Evrakları Okumasına Yardımcı Olmak
Modern ofisler lisanslar, kimlik kartları, sertifikalar, makbuzlar gibi dijital evraklarla boğuşuyor; bunların çoğu taranmış görüntü veya fotoğraf halinde saklanıyor. Bu resimlerin içinde isimler, tarihler ve kimlik numaraları gibi veritabanlarına geçirilmesi gereken önemli bilgiler gizli. Bu bilgileri elle yeniden yazmak yavaş ve hata yapmaya açık; mevcut otomatik sistemler ise dağınık düzenler, mühürler, bulanıklık ve çok çeşitli belge stilleriyle hâlâ zorlanıyor. Bu makale, insan etiketlemesi ve kurulum gereksinimini azaltarak yapay zekanın böyle belgeleri daha doğru “okumasını” sağlayan yeni bir yaklaşım sunuyor.
Geleneksel Araçların Neden Yetersiz Kaldığı
Mevcut sistemlerin çoğu belge anlama işiyle bir tür montaj hattı gibi ilgilenir. Önce bir optik karakter tanıma (OCR) motoru görüntüdeki her metin parçasını bulup okumaya çalışır. Ardından ikinci bir model bu metni analiz ederek hangi parçaların önemli olduğunu—örneğin şirket adı veya sertifika numarası—belirler. Bu yöntem temiz, tek tip formlarda makul derecede iyi işler, ancak belgeler düzen bakımından değişkenlik gösterdiğinde, tablolar içerdiğinde veya mühürler, filigranlar ya da kötü aydınlatma ile kaplandığında çöküyor. Bu sistemleri iyileştirmek genellikle her yeni belge türü için çok sayıda etiketli örnek toplamak ve her durum için kurallar ya da modeller tasarlamak anlamına geliyor; bu pahalı ve ölçeklenmesi zor bir süreç.
Görsel‑Dil Modellerini Yönlendirmek İçin Daha Akıllı Bir Yöntem
Büyük görsel‑dil modelleri (LVLM'ler) bir görüntüye bakıp metin üretebilir; tıpkı “görebilen” güçlü asistanlar gibi. Prensipte bu modeller ayrı bir OCR motoruna gerek kalmadan belgeleri doğrudan okuyabilir. Ancak birçok farklı belge türü tek bir genel yönergeyle verildiğinde, bu modeller sıklıkla kafa karışıklığı yaşıyor, gerçekte bulunmayan değerleri uyduruyor veya ince ayrıntıları kaçırıyor. Yazarlar, genel görevi iki adıma bölen bir “sınıflandırma‑yönlendirmeli” çerçeve öneriyor: önce bir görüntünün ne tür bir belge olduğunu hızlıca belirlemek; ardından bu karara dayanarak LVLM’ye hangi alanların çıkarılacağını ve yanıtların nasıl biçimlendirileceğini tam olarak söyleyen özel bir istem oluşturmak. Bu tasarım, modelin her seferinde daha dar ve daha net bir göreve odaklanmasını sağlıyor; böylece aynı anda tüm olası formlar arasında tahmin yürütmek zorunda kalmıyor.
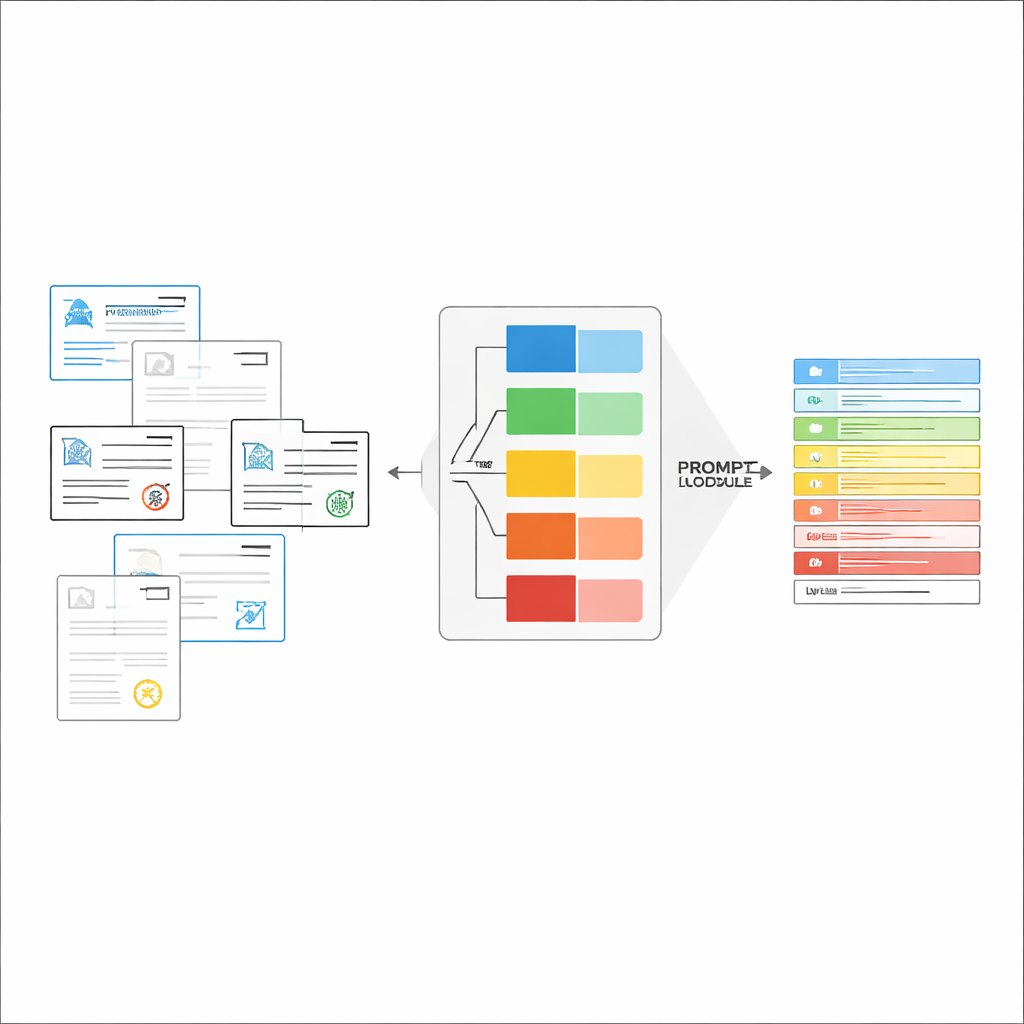
Uygun Uzunlukta Talimatları Anında Oluşturmak
Belge türü tanındıktan sonra sistem, LVLM için kısa, özelleştirilmiş bir yönerge derler. İstemin ortak bir bölümü genel işi açıklar—belirli öğeleri çıkarmak, katı bir JSON yapısına uymak, tutarlı tarih formatları kullanmak ve okunamayan alanları “belirsiz” olarak işaretlemek gibi. Bunun üzerine tür‑özgü parçalar eklenir: ilgili sertifika için gerekli tam alan listesi ve doğru çıkarımın nasıl göründüğünü gösteren birkaç örnek giriş ve çıkış. Bu bağlam içi öğrenme, LVLM’ye belge türü başına somut gösterimler sunar; modelin iç parametreleri değiştirilmeden uygulanır. Yazarlar, bilgi kuramından yararlanarak, bu odaklı istemlerin “şartlı hesaplama” gibi davrandığını gösteriyor: alakasız yönergeleri eler, modelin dikkatindeki dikkati azaltır ve üretilen her token’ın daha verimli kullanılmasını sağlar.
Gerçek Dünya Testleri: İhale Belgeleri Üzerinde
Bu yaklaşımın pratikte ne kadar iyi çalıştığını görmek için araştırmacılar, iş lisansları, sosyal güvenlik kayıtları ve güvenlik ile kalite sertifikalarına kadar uzanan 16 tür sertifikeyi kapsayan, yaklaşık 100.000 görüntüden oluşan büyük ve gerçekçi bir veri seti oluşturdu. Bu belgeler düzen karmaşıklığı, metin miktarı ve görsel gürültü açısından büyük farklılıklar gösteriyor. Yeni çerçeve iki modda test edildi: yeni istem stratejisini kullanan hazır bir LVLM ile tamamen sıfır‑atış (zero‑shot) ve hafif bir eğitim tekniğiyle alana uyarlanmış ince ayarlı bir versiyon. Her iki durumda da, durumu devlet‑sanayi standardı OCR ile modern bir bilgi‑çıkarım modelini birleştiren güçlü bir temel yöntemle karşılaştırıldı.
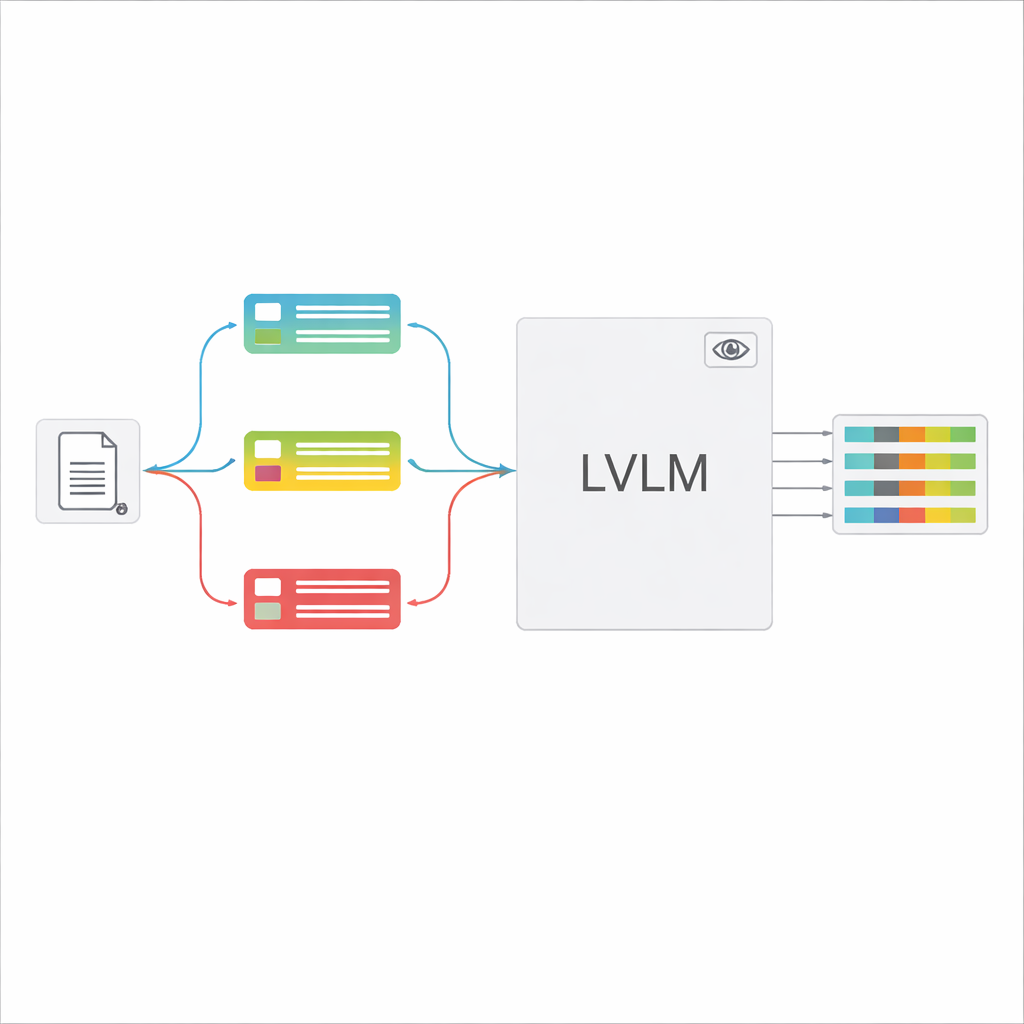
Daha Az Elle Çabayla Büyük Doğruluk Artışları
Sonuçlar çarpıcı. İnce ayar yapılmamış olsa bile, sınıflandırma‑yönlendirmeli LVLM denetimli OCR‑tabanlı boru hattını F1‑skorunda (yaygın bir doğruluk ölçüsü) 18 puandan fazla geride bırakıyor ve çıkarılan metnin gerçek veriyle ne kadar uyuştuğunu iyileştiriyor. Alana özgü ek ince ayarla LVLM çerçevesi %93’ün üzerinde F1 skoruna ulaşıyor; ağır filigranlar, düşük kontrast ve yoğun tablolar gibi zorlu durumları geleneksel yaklaşımdan çok daha iyi işleyebiliyor. Titiz deneyler, belge türü sınıflandırıcısının ve istem örneklerinin özellikle önemli olduğunu gösteriyor: bunlar kaldırıldığında doğrulukta büyük düşüşler görülüyor; bu da hedefe yönelik, girdiye duyarlı istemlerin anahtar olduğuna dair fikri destekliyor.
Günlük Belge İşleri İçin Anlamı
Günlük terimlerle bu araştırma, “gören ve konuşan” genel amaçlı bir yapay zekayı çok az özelleştirme ile birçok resmi belgeyi okuyabilen güvenilir bir ofis asistanına nasıl dönüştürebileceğini gösteriyor. Önce “Bu ne tür bir form?” diye sorup ardından modele kısa, hedefe yönelik örnekler ve talimatlar vererek, sistem hem daha doğru hem de ölçeklendirmesi daha kolay hale geliyor. Bu yaklaşım uyumluluk kontrolleri, ihale incelemeleri ve arka ofis veri girişi gibi işleri kolaylaştırabilir ve daha geniş bir dersin işaretini veriyor: büyük modelleri akıllıca bağlamla yönlendirmek, onları daha büyük yapmaya ya da baştan eğitmeye çalışmak kadar etkili olabilir.
Atıf: Li, H., Chen, G., Xia, J. et al. Visual information extraction from documents via classification-guided large vision-language models. Sci Rep 16, 14158 (2026). https://doi.org/10.1038/s41598-026-49319-z
Anahtar kelimeler: belge anlama, bilgi çıkarımı, görsel-dil modelleri, ofis otomasyonu, istem mühendisliği