Clear Sky Science · es
Extracción de información visual de documentos mediante modelos de gran tamaño vision‑lenguaje guiados por clasificación
Ayudar a los ordenadores a leer papeleo desordenado
Las oficinas modernas están ahogadas en papeleo digital: licencias, carnés de identidad, certificados, recibos, a menudo almacenados como imágenes escaneadas o fotografías. Ocultos en esas imágenes hay datos clave como nombres, fechas y números de identificación que deben verificarse y copiarse en bases de datos. Volver a teclear manualmente esta información es lento y propenso a errores, mientras que los sistemas automatizados actuales todavía tienen problemas con diseños abarrotados, sellos, desenfoque y una gran variedad de estilos documentales. Este artículo presenta una nueva forma para que la IA «lea» esos documentos con más precisión y con menos etiquetado y configuración manual.
Por qué las herramientas tradicionales se quedan cortas
La mayoría de los sistemas existentes tratan la comprensión de documentos como una cadena de montaje estricta. Primero, un motor de reconocimiento óptico de caracteres (OCR) intenta localizar y leer cada fragmento de texto en una imagen. Luego, un segundo modelo analiza ese texto para decidir qué partes son importantes —como el nombre de la empresa o el número de certificado—. Esto funciona razonablemente bien en formularios limpios y uniformes, pero se hunde cuando los documentos varían en diseño, contienen tablas o están cubiertos por sellos, marcas de agua o mala iluminación. Mejorar estos sistemas suele implicar recopilar muchos ejemplos etiquetados para cada nuevo tipo de documento y diseñar reglas o modelos específicos para cada caso, lo que es costoso y difícil de escalar.
Una manera más inteligente de guiar a los modelos vision‑lenguaje
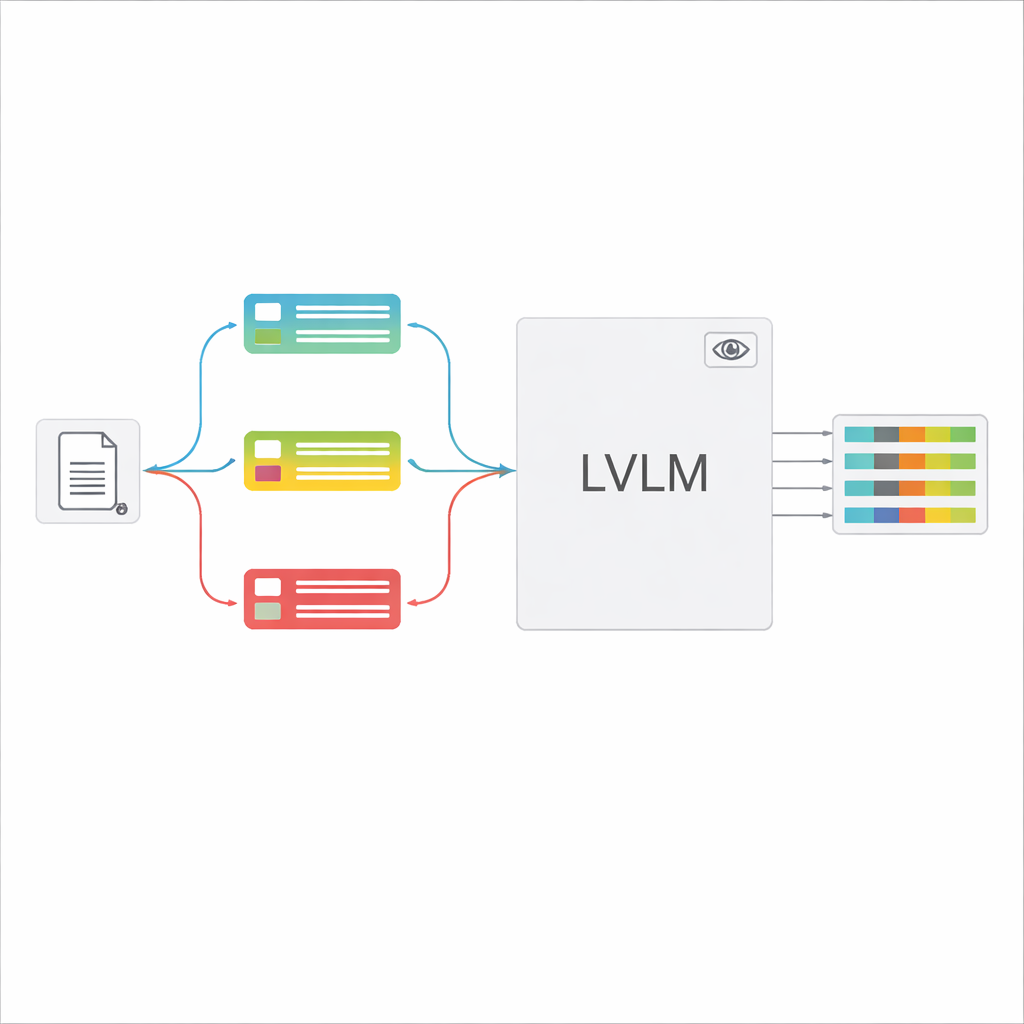
Los grandes modelos vision‑lenguaje (LVLM) pueden observar una imagen y generar texto, como asistentes potentes que pueden «ver». En principio, podrían leer documentos directamente, sin un motor OCR separado. Sin embargo, cuando se les alimenta con muchos tipos de documentos usando una instrucción genérica, estos modelos a menudo se confunden, alucinan valores que no están presentes o pasan por alto detalles finos. Los autores proponen un marco «guiado por clasificación» que divide la tarea general en dos pasos: primero, decidir rápidamente qué tipo de documento es la imagen; segundo, usar esa decisión para construir un prompt a medida que diga al LVLM exactamente qué campos extraer y cómo formatear las respuestas. Este diseño permite que el modelo se concentre en una tarea más limitada y clara cada vez, en lugar de adivinar entre todas las formas posibles a la vez.
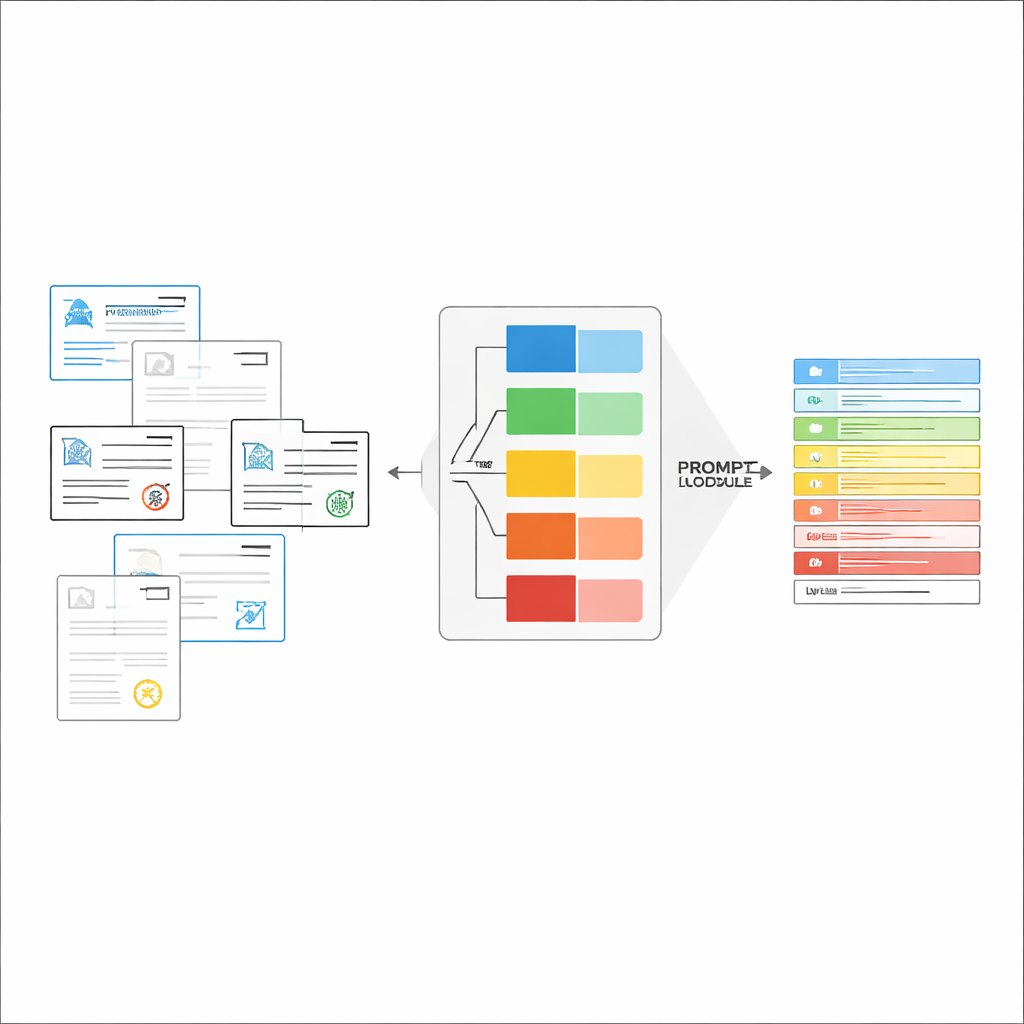
Construir instrucciones justas en el momento
Una vez reconocido el tipo de documento, el sistema arma una instrucción corta y personalizada para el LVLM. Una parte compartida del prompt explica la tarea general: extraer elementos específicos, respetar una estructura JSON estricta, usar formatos de fecha consistentes y marcar como «no identificado» los campos ilegibles. Sobre esto se añaden fragmentos específicos por tipo: la lista exacta de campos necesarios para ese certificado y algunos ejemplos de entradas y salidas que muestran cómo debe ser una extracción correcta. Este aprendizaje en contexto da al LVLM demostraciones concretas para cada tipo de documento sin cambiar sus parámetros internos. Los autores demuestran, usando ideas de la teoría de la información, que prompts tan enfocados actúan como una «computación condicional»: eliminan instrucciones irrelevantes, reducen la distracción en la atención del modelo y hacen un uso más eficaz de cada token generado.
Pruebas en el mundo real con documentos de licitación
Para evaluar su eficacia en la práctica, los investigadores construyeron un conjunto de datos grande y realista a partir de una plataforma electrónica de licitaciones, que contiene casi 100.000 imágenes abarcando 16 tipos de certificados, desde licencias comerciales y registros de seguridad social hasta certificaciones de seguridad y calidad. Estos documentos difieren ampliamente en complejidad del diseño, cantidad de texto y ruido visual. El nuevo marco se probó en dos modos: puramente zero‑shot, usando un LVLM comercial con la nueva estrategia de prompting, y una versión afinada adaptada al dominio mediante una técnica de entrenamiento ligera. En ambos casos lo compararon con una línea base potente que combinaba OCR de última generación con un modelo moderno de extracción de información.
Grandes mejoras de precisión con menos esfuerzo manual
Los resultados son llamativos. Incluso sin afinado, el LVLM guiado por clasificación supera a la canalización supervisada basada en OCR por más de 18 puntos porcentuales en F1 (una medida común de precisión) y mejora la coincidencia entre el texto extraído y la verdad de referencia. Con afinado adicional específico del dominio, el marco LVLM alcanza más del 93% de F1, manejando casos difíciles como marcas de agua intensas, bajo contraste y tablas densas mucho mejor que el enfoque tradicional. Experimentos cuidadosos muestran que el clasificador de tipo de documento y los ejemplos en el prompt son especialmente importantes: eliminarlos provoca caídas grandes en la precisión, lo que respalda la idea de que los prompts dirigidos y sensibles al input son clave.
Qué significa esto para el trabajo documental cotidiano
En términos prácticos, esta investigación muestra cómo convertir una IA de propósito general que puede «ver y hablar» en un asistente de oficina fiable capaz de leer muchos tipos de documentos oficiales con una configuración mínima. Al preguntar primero «¿qué tipo de formulario es este?» y luego dar al modelo un conjunto corto y personalizado de ejemplos e instrucciones, el sistema se vuelve tanto más preciso como más fácil de desplegar a escala. Este enfoque podría agilizar tareas como verificaciones de cumplimiento, revisiones de ofertas y entrada de datos en back office, y sugiere una lección más amplia: guiar con inteligencia a los grandes modelos mediante el contexto adecuado puede ser tan potente como hacerlos más grandes o entrenarlos desde cero.
Cita: Li, H., Chen, G., Xia, J. et al. Visual information extraction from documents via classification-guided large vision-language models. Sci Rep 16, 14158 (2026). https://doi.org/10.1038/s41598-026-49319-z
Palabras clave: comprensión de documentos, extracción de información, modelos vision‑lenguaje, automación de oficinas, ingeniería de prompts