Clear Sky Science · en
Visual information extraction from documents via classification-guided large vision-language models
Helping Computers Read Messy Paperwork
Modern offices are drowning in digital paperwork—licenses, ID cards, certificates, receipts—often stored as scanned images or photos. Hidden in these pictures are key facts like names, dates, and ID numbers that must be checked and copied into databases. Manually retyping this information is slow and error‑prone, while today’s automated systems still struggle with cluttered layouts, stamps, blur, and many different document styles. This paper introduces a new way to let AI “read” such documents more accurately with less human labeling and setup.
Why Traditional Tools Fall Short
Most existing systems treat document understanding as a strict assembly line. First, an optical character recognition (OCR) engine tries to spot and read every piece of text in an image. Then a second model analyzes that text to decide which bits are important—such as the company name or certificate number. This works reasonably well on clean, uniform forms, but breaks down when documents vary in layout, contain tables, or are covered by seals, watermarks, or poor lighting. Improving these systems usually means collecting many labeled examples for each new document type and carefully designing rules or models for each case, which is costly and hard to scale.
A Smarter Way to Guide Vision-Language Models
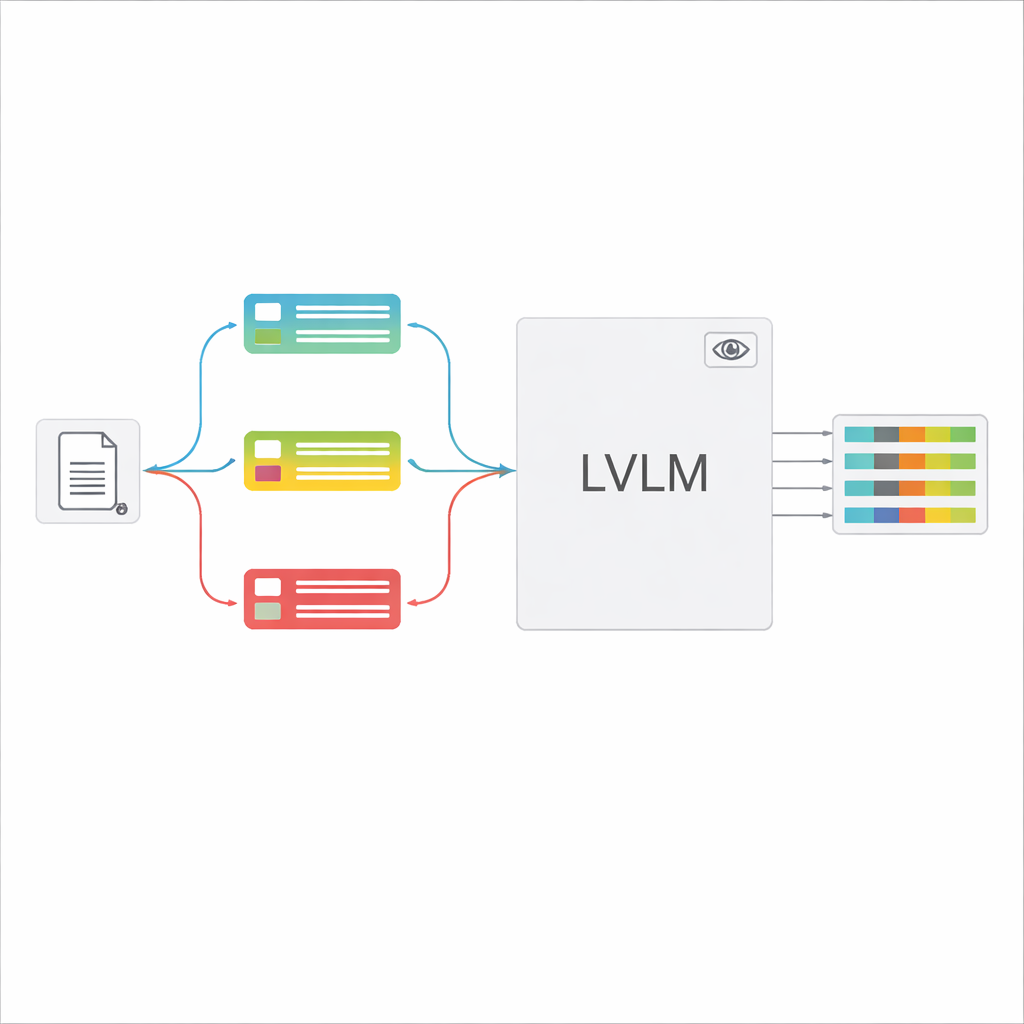
Large vision‑language models (LVLMs) can look at an image and generate text, much like powerful assistants that can “see.” In principle, they could read documents directly, without a separate OCR engine. However, when fed many different document types with one generic instruction, these models often become confused, hallucinate values that are not really present, or miss fine details. The authors propose a “classification‑guided” framework that breaks the overall task into two steps: first, quickly decide what kind of document an image is; second, use that decision to build a tailored prompt that tells the LVLM exactly which fields to extract and how to format the answers. This design lets the model focus on a narrower, clearer task each time instead of guessing among all possible forms at once.
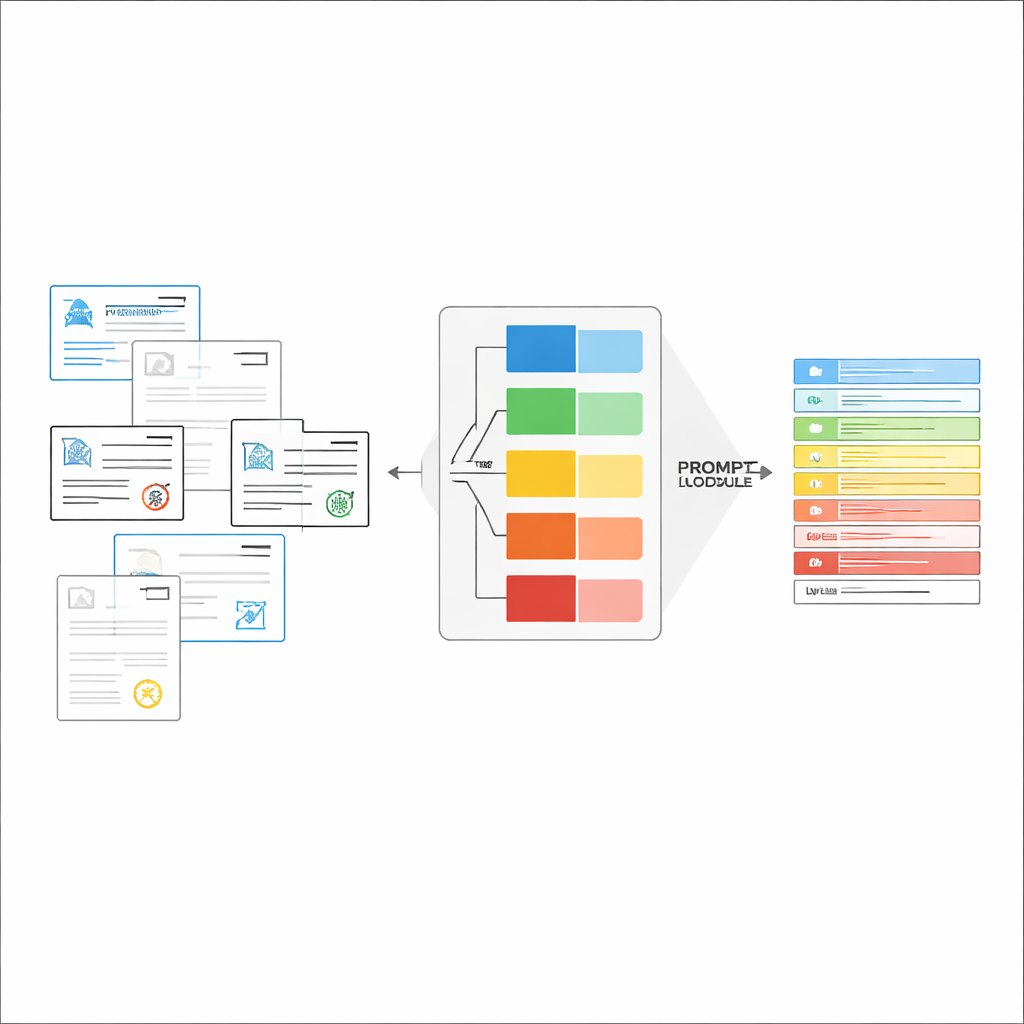
Building Just‑Right Instructions on the Fly
Once the document type is recognized, the system assembles a short, customized instruction for the LVLM. A shared part of the prompt explains the general job—extract specific items, respect a strict JSON structure, use consistent date formats, and mark unreadable fields as “unidentified.” On top of this, type‑specific pieces are added: the exact list of fields needed for that certificate and a few example inputs and outputs that show what correct extraction looks like. This in‑context learning gives the LVLM concrete demonstrations for each document type without changing its internal parameters. The authors show, using ideas from information theory, that such focused prompts act like “conditional computation”: they strip away irrelevant instructions, reduce distraction in the model’s attention, and make better use of each generated token.
Real‑World Tests on Bidding Documents
To see how well this works in practice, the researchers built a large, realistic dataset from an electronic bidding platform, containing nearly 100,000 images spanning 16 kinds of certificates, from business licenses and social security records to safety and quality certifications. These documents differ widely in layout complexity, amount of text, and visual noise. The new framework was tested in two modes: purely zero‑shot, using an off‑the‑shelf LVLM with the new prompting strategy, and a fine‑tuned version adapted to the domain using a lightweight training technique. In both cases, they compared it to a strong baseline that combined state‑of‑the‑art OCR with a modern information‑extraction model.
Big Accuracy Gains with Less Manual Effort
The results are striking. Even without fine‑tuning, the classification‑guided LVLM beats the supervised OCR‑based pipeline by over 18 percentage points in F1‑score (a common accuracy measure) and improves how closely the extracted text matches the ground truth. With additional domain‑specific fine‑tuning, the LVLM framework reaches more than 93% F1, handling challenging cases like heavy watermarks, low contrast, and dense tables far better than the traditional approach. Careful experiments show that the document‑type classifier and the prompt examples are especially important: removing them causes large drops in accuracy, supporting the idea that targeted, input‑aware prompts are key.
What This Means for Everyday Document Work
In everyday terms, this research shows how to turn a general‑purpose AI that can “see and talk” into a reliable office assistant that can read many kinds of official documents with minimal custom setup. By first asking, “What kind of form is this?” and then giving the model a short, tailored set of examples and instructions, the system becomes both more accurate and easier to deploy at scale. This approach could streamline tasks such as compliance checks, tender reviews, and back‑office data entry, and it hints at a broader lesson: smartly guiding large models with the right context can be as powerful as making them bigger or training them from scratch.
Citation: Li, H., Chen, G., Xia, J. et al. Visual information extraction from documents via classification-guided large vision-language models. Sci Rep 16, 14158 (2026). https://doi.org/10.1038/s41598-026-49319-z
Keywords: document understanding, information extraction, vision-language models, office automation, prompt engineering