Clear Sky Science · pl
Wydobywanie informacji wizualnej z dokumentów za pomocą dużych modeli wizualno‑językowych kierowanych klasyfikacją
Pomoc komputerom w czytaniu niechlujnych dokumentów
Nowoczesne biura toną w cyfrowych dokumentach — licencjach, dowodach tożsamości, świadectwach, paragonach — często przechowywanych jako zeskanowane obrazy lub zdjęcia. Ukryte na tych obrazach są kluczowe dane, takie jak nazwiska, daty czy numery identyfikacyjne, które trzeba zweryfikować i przepisać do baz danych. Ręczne przepisywanie jest powolne i podatne na błędy, a współczesne systemy automatyczne wciąż mają problemy ze złożonym układem, pieczęciami, rozmyciem czy wieloma stylami dokumentów. Artykuł przedstawia nowe podejście, które pozwala sztucznej inteligencji „czytać” takie dokumenty dokładniej przy mniejszym nakładzie ręcznego oznaczania danych i konfiguracji.
Dlaczego tradycyjne narzędzia zawodzą
Większość istniejących systemów traktuje rozumienie dokumentów jak sztywną linię montażową. Najpierw silnik optycznego rozpoznawania znaków (OCR) próbuje odnaleźć i odczytać każdy fragment tekstu na obrazie. Potem drugi model analizuje ten tekst, aby zdecydować, które fragmenty są istotne — na przykład nazwa firmy czy numer świadectwa. To działa w miarę dobrze na czystych, jednorodnych formularzach, lecz zawodzi, gdy dokumenty różnią się układem, zawierają tabele albo są pokryte pieczęciami, znakami wodnymi lub cierpią na złe oświetlenie. Poprawa tych systemów zwykle oznacza zbieranie wielu oznaczonych przykładów dla każdego nowego typu dokumentu i staranne opracowywanie reguł lub modeli dla każdego przypadku, co jest kosztowne i trudne do skalowania.
Mądrzejszy sposób kierowania modelami wizualno‑językowymi
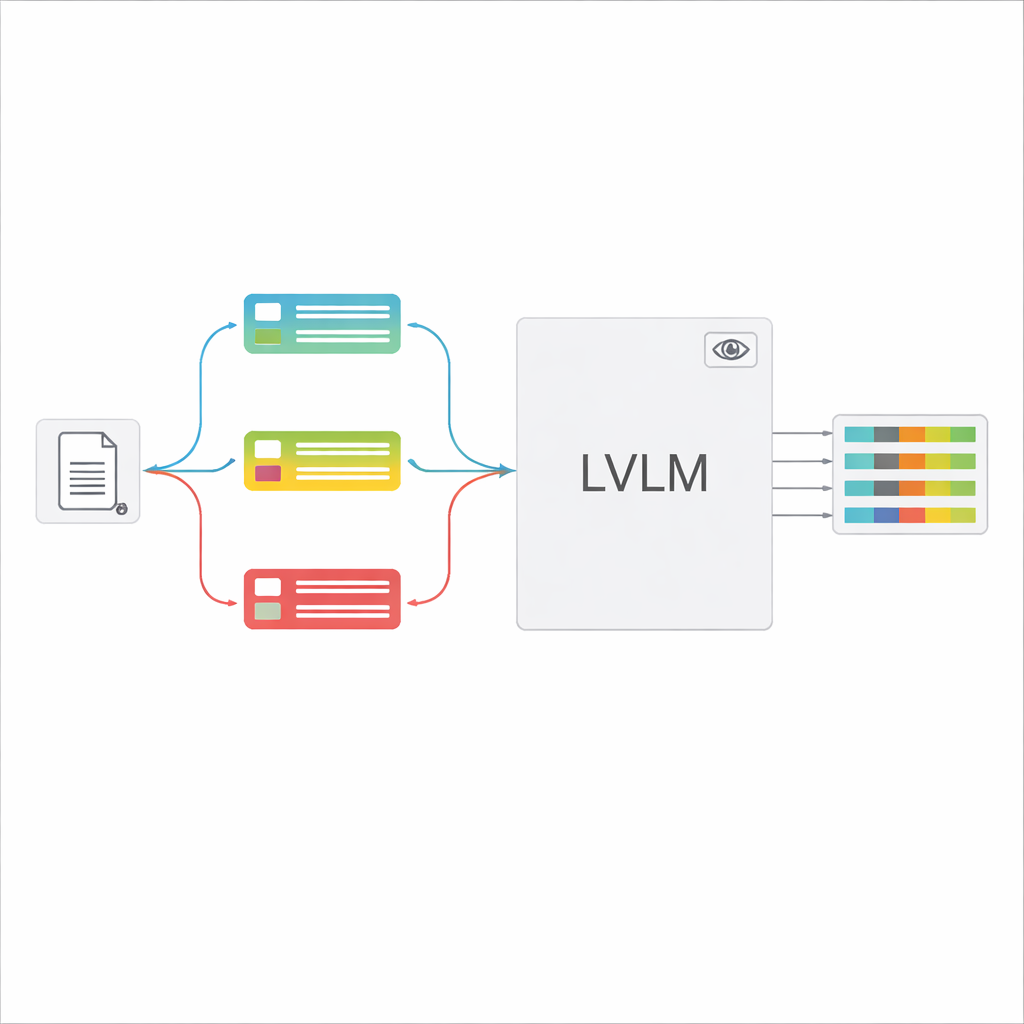
Duże modele wizualno‑językowe (LVLM) potrafią spojrzeć na obraz i wygenerować tekst, podobnie jak zaawansowane asystenty, które „widzą”. Z zasadzie mogłyby czytać dokumenty bez oddzielnego silnika OCR. Jednak dostarczone jedną ogólną instrukcją dla wielu różnych typów dokumentów, modele te często się gubią, wymyślają wartości, których tam nie ma, lub pomijają drobne szczegóły. Autorzy proponują ramę „kierowaną klasyfikacją”, która dzieli zadanie na dwa kroki: najpierw szybko ustalić, jakiego typu jest dokument, a następnie użyć tej decyzji do zbudowania dopasowanego promptu, który mówi LVLM dokładnie, jakie pola wydobyć i jak sformatować odpowiedzi. Takie podejście pozwala modelowi skupić się za każdym razem na węższym, jaśniejszym zadaniu zamiast domyślać się spośród wszystkich możliwych formularzy naraz.
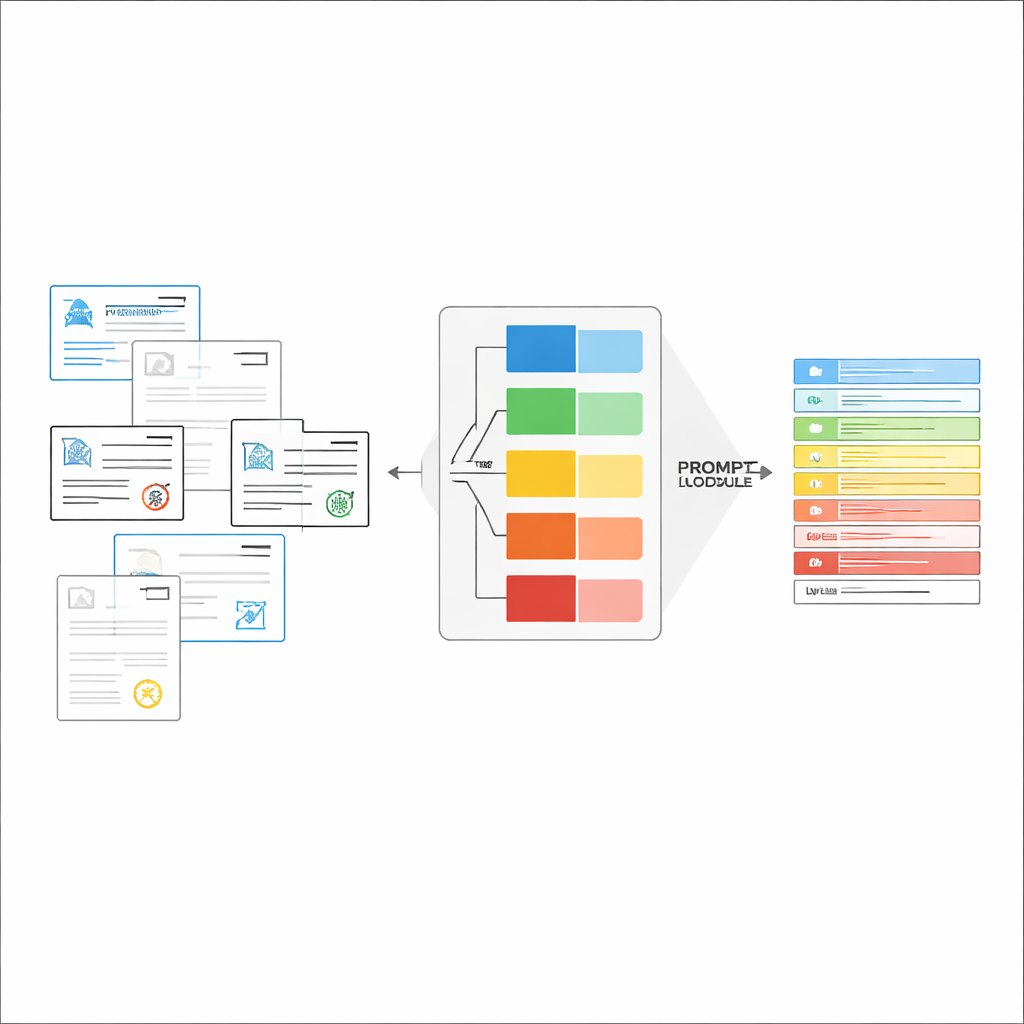
Tworzenie dokładnie dopasowanych instrukcji w locie
Gdy typ dokumentu zostanie rozpoznany, system składa krótką, spersonalizowaną instrukcję dla LVLM. Wspólna część promptu wyjaśnia ogólne zadanie — wydobyć określone elementy, przestrzegać ścisłej struktury JSON, używać spójnych formatów dat i oznaczać nieczytelne pola jako „niezidentyfikowane”. Do tego dodawane są fragmenty specyficzne dla typu: dokładna lista wymaganych pól dla danego świadectwa oraz kilka przykładów wejść i wyjść pokazujących prawidłowe wydobycie. To uczenie w kontekście dostarcza LVLM konkretnych demonstracji dla każdego typu dokumentu bez zmiany jego wewnętrznych parametrów. Autorzy pokazują, korzystając z idei z teorii informacji, że tak skoncentrowane prompty działają jak „warunkowa obliczalność”: odfiltrowują nieistotne instrukcje, zmniejszają rozpraszanie uwagi modelu i umożliwiają lepsze wykorzystanie każdego wygenerowanego tokena.
Testy w realistycznych warunkach na dokumentach przetargowych
Aby sprawdzić skuteczność podejścia w praktyce, badacze zbudowali dużą, realistyczną bazę danych z platformy przetargowej, zawierającą prawie 100 000 obrazów obejmujących 16 rodzajów świadectw, od licencji biznesowych i dokumentów ubezpieczeń społecznych po certyfikaty bezpieczeństwa i jakości. Dokumenty te znacznie różnią się pod względem złożoności układu, ilości tekstu i szumów wizualnych. Nowe podejście testowano w dwóch trybach: czysto zero‑shot, używając gotowego LVLM z nową strategią promptowania, oraz wersję dopasowaną do domeny przy pomocy lekkiej techniki treningowej. W obu przypadkach porównano je z silną bazą odniesienia łączącą nowoczesny OCR ze współczesnym modelem wydobywania informacji.
Duży wzrost dokładności przy mniejszym wysiłku ręcznym
Wyniki są uderzające. Nawet bez dostrajania, kierowany klasyfikacją LVLM przewyższa nadzorowany pipeline oparty na OCR o ponad 18 punktów procentowych w F1 (powszechnie stosowana miara dokładności) i poprawia zgodność wydobytego tekstu z prawdą źródłową. Przy dodatkowym dostrojeniu specyficznym dla domeny, ramy LVLM osiągają ponad 93% F1, radząc sobie dużo lepiej niż tradycyjne podejście w trudnych przypadkach, takich jak silne znaki wodne, niski kontrast czy gęste tabele. Dokładne eksperymenty pokazują, że klasyfikator typu dokumentu i przykłady w promptach są szczególnie istotne: ich usunięcie powoduje duże spadki dokładności, co potwierdza, że celowane, zależne od wejścia promptowanie jest kluczowe.
Co to znaczy dla codziennej pracy z dokumentami
W praktycznych słowach, badania te pokazują, jak zamienić ogólnego AI, który potrafi „widzieć i mówić”, w niezawodnego asystenta biurowego, potrafiącego odczytywać wiele rodzajów oficjalnych dokumentów przy minimalnej konfiguracji. Najpierw pytając „Jaki to formularz?”, a potem dając modelowi krótki, dopasowany zestaw przykładów i instrukcji, system staje się zarówno dokładniejszy, jak i łatwiejszy do wdrożenia na dużą skalę. Podejście to może usprawnić zadania takie jak kontrole zgodności, przeglądy ofert czy wprowadzanie danych do zaplecza, a także sugeruje szerszą lekcję: inteligentne kierowanie dużymi modelami właściwym kontekstem może być równie potężne jak ich powiększanie albo trenowanie od podstaw.
Cytowanie: Li, H., Chen, G., Xia, J. et al. Visual information extraction from documents via classification-guided large vision-language models. Sci Rep 16, 14158 (2026). https://doi.org/10.1038/s41598-026-49319-z
Słowa kluczowe: rozumienie dokumentów, wydobywanie informacji, modele wizualno‑językowe, automatyzacja biurowa, inżynieria zapytań