Clear Sky Science · ja
分類で導く大規模ビジョン・言語モデルによる文書からの視覚情報抽出
乱雑な紙資料をコンピュータに読ませる
現代のオフィスはライセンス、身分証明書、証明書、領収書などのデジタル書類であふれており、多くはスキャン画像や写真として保存されています。これらの画像には、名前、日付、識別番号などデータベースに転記・確認する必要のある重要な事実が隠れています。手作業での再入力は遅くミスが起きやすい一方、既存の自動化システムは散らかったレイアウト、押印、ぼやけ、さまざまな文書様式にまだ苦戦しています。本論文は、少ないラベリングと設定でこうした文書をより正確に「読む」ための新しい方法を紹介します。
従来手法が及ばない理由
既存の多くのシステムは文書理解を厳密な工程に分けて扱います。まずOCRエンジンが画像中のテキストを検出して読み取り、次に別のモデルがそのテキストを解析して会社名や証明書番号など重要な箇所を判別します。これは整った均一なフォームではそれなりに機能しますが、レイアウトが多様で表を含む場合や、押印や透かし、悪い照明の下では破綻します。これらを改善するには対象ごとに多数のラベル付き例を収集し、ルールやモデルを個別に設計する必要があり、コストが高くスケールしにくいのが現実です。
ビジョン・言語モデルを賢く誘導する方法
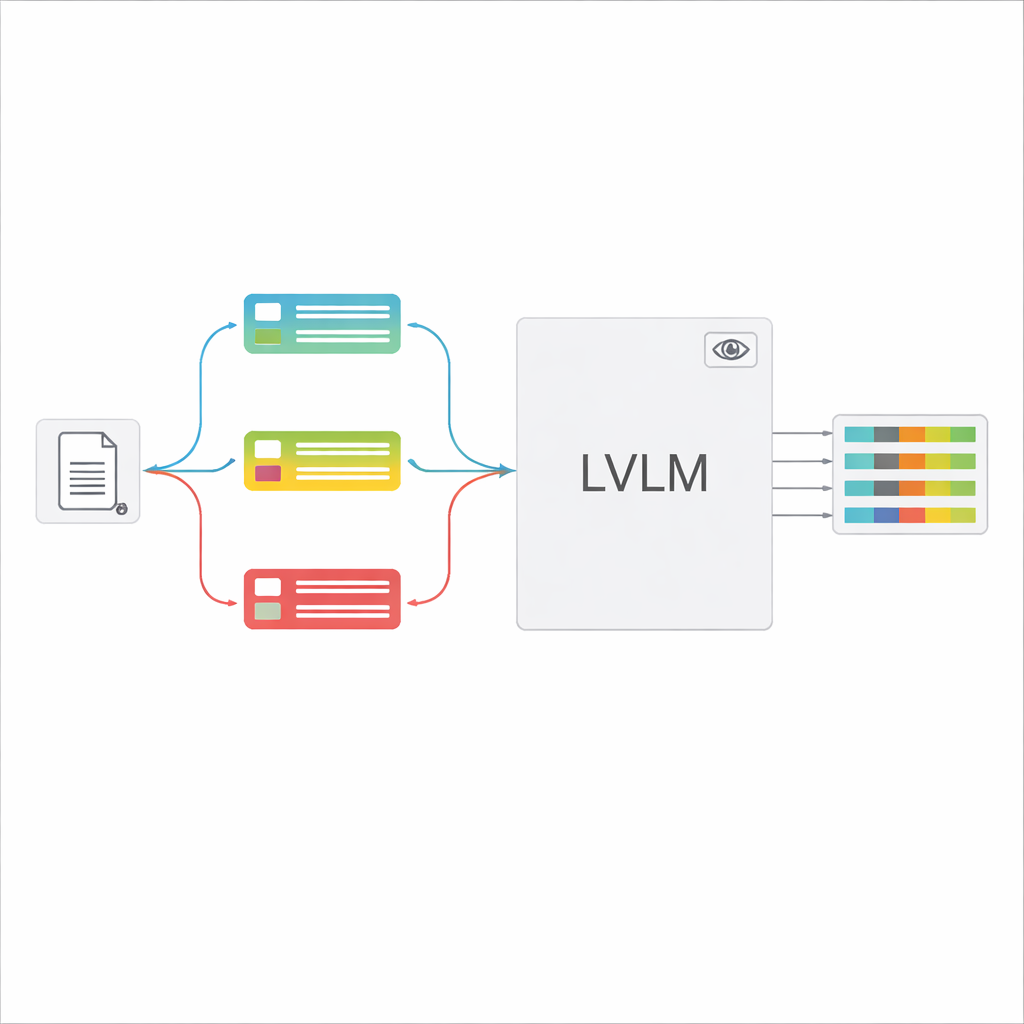
大規模ビジョン・言語モデル(LVLM)は画像を見てテキストを生成できます。原理的には、個別のOCRを使わずに文書を直接読めるはずです。しかし、多種類の文書を単一の一般的な指示で与えると、モデルは混乱し、実際には存在しない値を「幻覚」したり、細かな情報を見落としたりしがちです。著者らは「分類で導く」フレームワークを提案します。まず画像がどの種類の文書かを素早く判定し、その判定を基にLVLMに渡すカスタムプロンプトを構築して、抽出すべき項目と回答形式を正確に指定します。これによりモデルは一度にすべての可能性を推測するのではなく、より狭く明確な課題に集中できます。
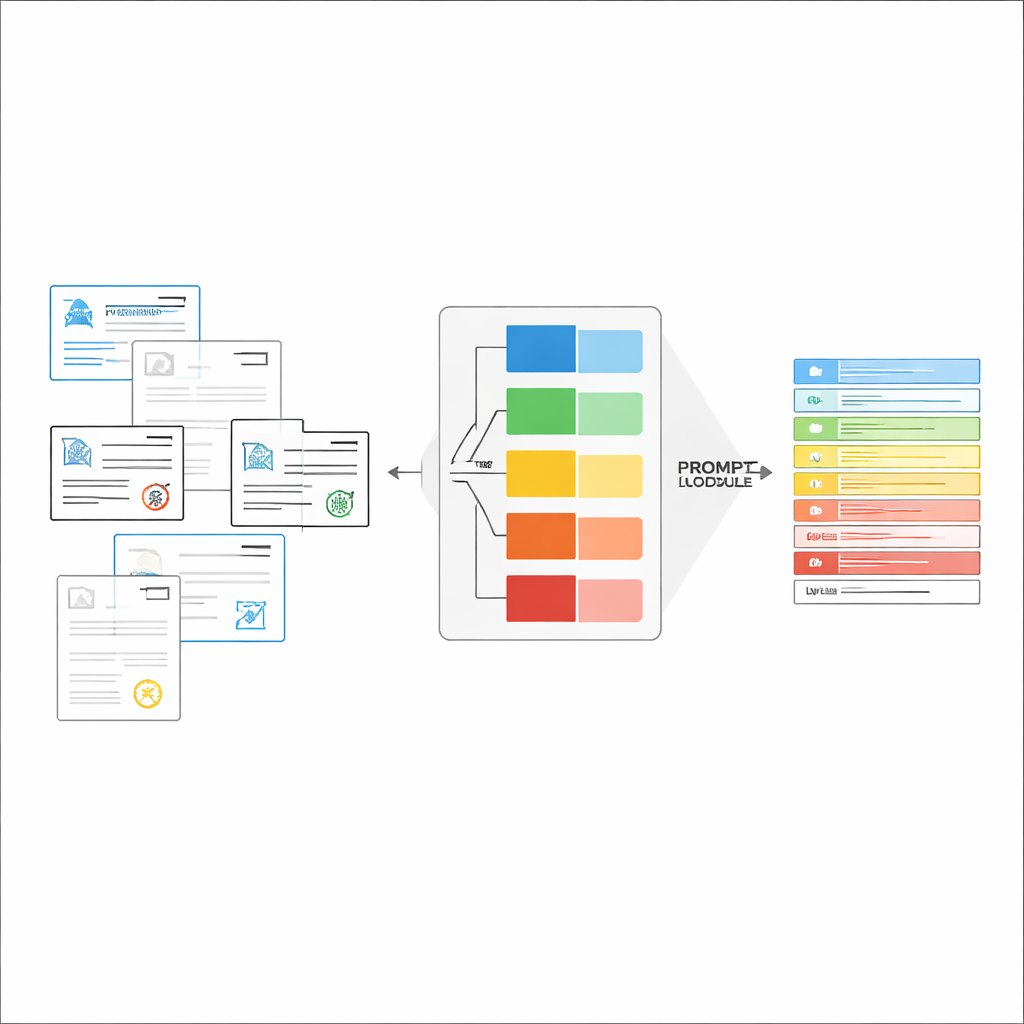
その場でちょうど良い指示を作る
文書種類が識別されると、システムはLVLM向けに短くカスタマイズされた指示を組み立てます。プロンプトの共通部分では、特定項目を抽出すること、厳格なJSON構造を守ること、日付の形式を統一すること、読み取れない項目は「unidentified」とマークすることなど一般的な作業内容を説明します。これに加えて、種類ごとの具体的な項目リストや、正しい抽出例を示すいくつかの入出力例を盛り込みます。このコンテキスト内学習によりLVLMは内部パラメータを変えずに文書タイプごとの具体的な実演を得られます。著者らは情報理論の視点を使って、こうした焦点の絞られたプロンプトが「条件付き計算」のように働き、無関係な指示を取り除き、モデルの注意散漫を減らし、生成する各トークンをより有効に使えるようにすることを示しています。
入札書類での実証試験
実用性を検証するため、研究者らは電子入札プラットフォームから約10万枚、16種類の証明書に及ぶ大規模で現実的なデータセットを構築しました。対象には会社登記や社会保険関連、品質・安全の認証などが含まれ、レイアウトの複雑さ、テキスト量、視覚ノイズは大きく異なります。新しいフレームワークは2つのモードで評価されました。ひとつはオフ・ザ・シェルフのLVLMに新しいプロンプト戦略を適用した純粋なゼロショット、もうひとつは軽量な訓練手法でドメインに適応させたファインチューニング版です。両者とも、最先端のOCRと現代的な情報抽出モデルを組み合わせた強力なベースラインと比較されました。
手間を減らして精度を大幅に向上
結果は顕著です。ファインチューニングを行わない場合でも、分類で導くLVLMは教師ありOCRベースのパイプラインをF1スコアで18ポイント以上上回り、抽出テキストの真値との一致も改善しました。ドメイン特化のファインチューニングを加えると、LVLMフレームワークは93%を超えるF1を達成し、強い透かし、低コントラスト、密な表組みなどの難しいケースを従来手法よりはるかにうまく扱いました。慎重な実験により、文書種類分類器とプロンプト内の例示が特に重要であることが示され、これらを省くと精度が大きく落ちるため、入力に応じたターゲット化されたプロンプトが鍵であることが支持されます。
日常の文書作業への意義
日常的な視点では、この研究は「見て話せる」汎用AIを、最小限のカスタム設定で多種の公的文書を読める信頼できるオフィスアシスタントに変える方法を示しています。まず「これは何のフォームか?」と問うことで文書タイプを特定し、その後短く調整された例と指示を与えることで、システムは精度が高く、スケールしやすくなります。このアプローチはコンプライアンスチェック、入札レビュー、バックオフィスのデータ入力などの業務を効率化でき、より大きくしたり最初から訓練し直したりする代わりに、大規模モデルを適切な文脈で賢く誘導することの有効性を示しています。
引用: Li, H., Chen, G., Xia, J. et al. Visual information extraction from documents via classification-guided large vision-language models. Sci Rep 16, 14158 (2026). https://doi.org/10.1038/s41598-026-49319-z
キーワード: 文書理解, 情報抽出, ビジョン・言語モデル, オフィス自動化, プロンプトエンジニアリング