Clear Sky Science · nl
Visuele informatie-extractie uit documenten via classificatie-gestuurde grote visie-taalmodellen
Computers helpen rommelige papieren te lezen
Moderne kantoren verdrinken in digitale papieren—licenties, ID-kaarten, certificaten, bonnetjes—die vaak zijn opgeslagen als gescande afbeeldingen of foto’s. In deze afbeeldingen zitten sleutelgegevens zoals namen, data en identificatienummers die gecontroleerd en in databases gekopieerd moeten worden. Deze informatie handmatig overtypen is traag en foutgevoelig, terwijl de huidige geautomatiseerde systemen nog steeds moeite hebben met rommelige lay-outs, stempels, onscherpte en de vele verschillende documentstijlen. Dit artikel introduceert een nieuwe manier om AI dergelijke documenten nauwkeuriger te laten “lezen” met minder menselijke annotatie en instellingen.
Waarom traditionele tools tekortschieten
De meeste bestaande systemen beschouwen documentbegrip als een strikte assemblagelijn. Eerst probeert een OCR-engine (optische tekenherkenning) elk tekstfragment in een afbeelding te vinden en te lezen. Vervolgens analyseert een tweede model die tekst om te beslissen welke stukken belangrijk zijn—zoals de bedrijfsnaam of het certificaatnummer. Dit werkt redelijk goed bij schone, uniforme formulieren, maar faalt wanneer documenten in opmaak variëren, tabellen bevatten of bedekt zijn met zegels, watermerken of slechte belichting. Het verbeteren van deze systemen betekent meestal dat je veel gelabelde voorbeelden voor elk nieuw documenttype moet verzamelen en zorgvuldig regels of modellen voor elk geval moet ontwerpen, wat duur is en moeilijk te schalen.
Een slimmer manier om visie-taalmodellen te sturen
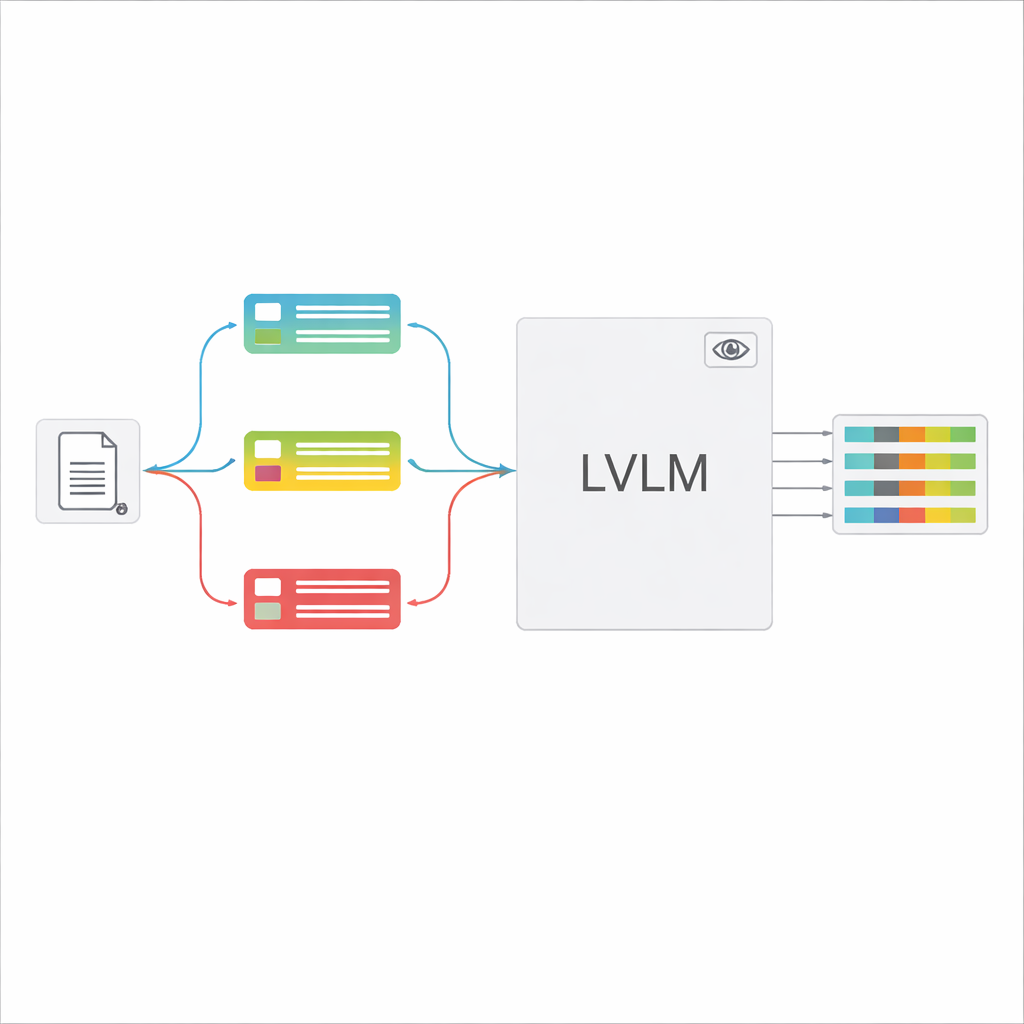
Grote visie‑taalmodellen (LVLMs) kunnen naar een afbeelding kijken en tekst genereren, vergelijkbaar met krachtige assistenten die kunnen “zien”. In principe zouden ze documenten direct kunnen lezen, zonder een aparte OCR-engine. Wanneer ze echter veel verschillende documenttypes met één algemene instructie krijgen, raken deze modellen vaak in de war, hallucineren ze waarden die er niet zijn of missen ze fijne details. De auteurs stellen een "classificatie-gestuurde" structuur voor die de taak in twee stappen opdeelt: bepaal eerst snel met wat voor soort document je te maken hebt; gebruik die beslissing vervolgens om een op maat gemaakte prompt te bouwen die het LVLM precies vertelt welke velden moet worden geëxtraheerd en hoe de antwoorden geformatteerd moeten zijn. Dit ontwerp laat het model zich telkens op een nauwere, duidelijkere taak richten in plaats van te gokken tussen alle mogelijke formulieren tegelijk.
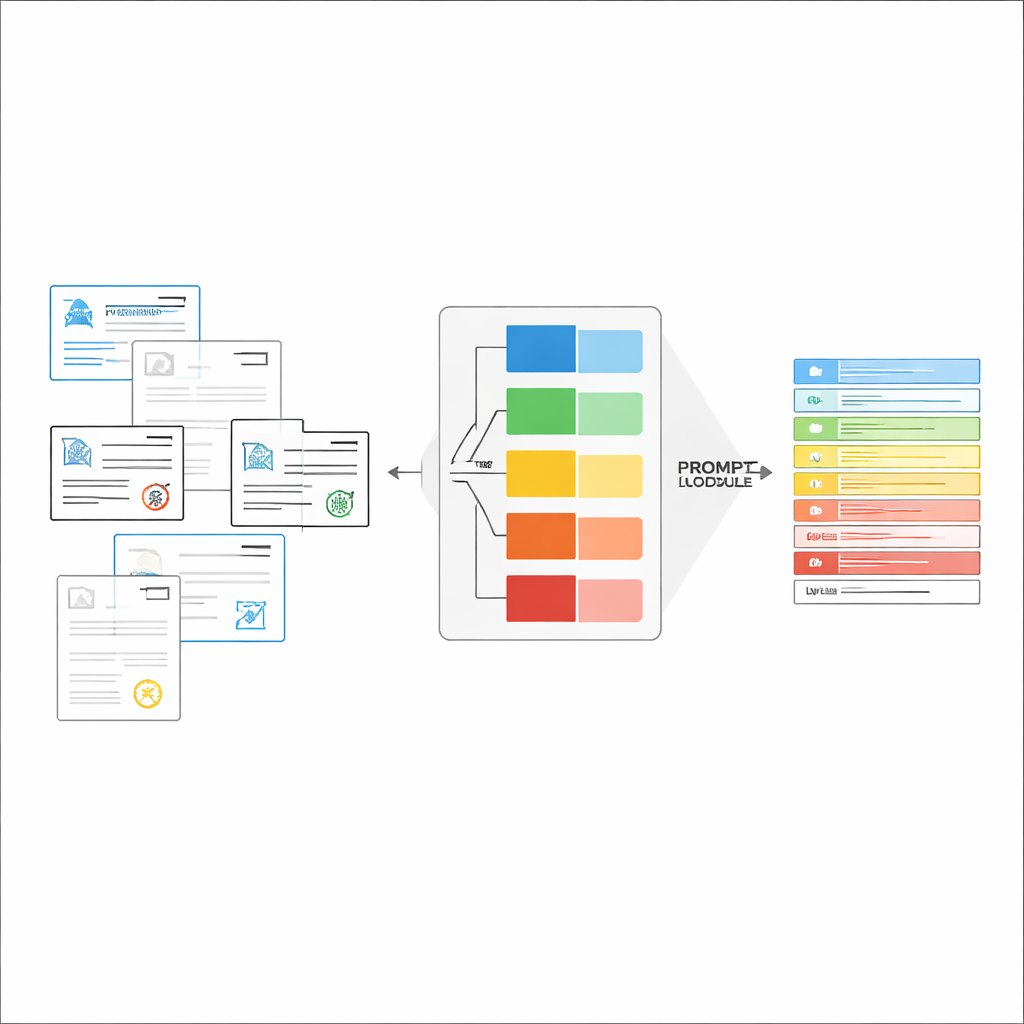
Ter plekke precies-pas instructies samenstellen
Wanneer het documenttype is herkend, stelt het systeem een korte, aangepaste instructie voor het LVLM samen. Een gedeeld deel van de prompt legt de algemene opdracht uit—specifieke items extraheren, een strikt JSON-structuur respecteren, consistente datumformaten gebruiken en onleesbare velden markeren als “onbekend”. Daarbovenop worden type-specifieke onderdelen toegevoegd: de exacte lijst van velden die voor dat certificaat nodig zijn en een paar voorbeeldinvoer- en uitvoerparen die laten zien hoe correcte extractie eruitziet. Dit in-context leren geeft het LVLM concrete demonstraties voor elk documenttype zonder de interne parameters te wijzigen. De auteurs tonen aan, met ideeën uit de informatietheorie, dat dergelijke gerichte prompts werken als "voorwaardelijke berekening": ze verwijderen irrelevante instructies, verminderen afleiding in de aandacht van het model en benutten elk gegenereerd token efficiënter.
Testen in de praktijk met aanbestedingsdocumenten
Om te beoordelen hoe dit in de praktijk werkt, bouwden de onderzoekers een grote, realistische dataset van een elektronisch aanbestedingsplatform, met bijna 100.000 afbeeldingen verspreid over 16 soorten certificaten, van handelsvergunningen en socialezekerheidsdocumenten tot veiligheids- en kwaliteitscertificaten. Deze documenten verschillen sterk in lay-outcomplexiteit, hoeveelheid tekst en visuele ruis. Het nieuwe raamwerk werd getest in twee modi: puur zero-shot, waarbij een kant-en-klaar LVLM met de nieuwe prompting-strategie werd gebruikt, en een fijn-afgestelde versie aangepast aan het domein met een lichte trainingsmethode. In beide gevallen vergeleken ze het met een sterke baseline die state-of-the-art OCR combineerde met een modern informatie-extractiemodel.
Grote nauwkeurigheidswinst met minder handmatig werk
De resultaten zijn opvallend. Zelfs zonder fijnafstemming verslaat het classificatie-gestuurde LVLM de door supervisie geleide OCR-pijplijn met meer dan 18 procentpunt in F1‑score (een gebruikelijke nauwkeurigheidsmaat) en verbetert het hoe goed de geëxtraheerde tekst overeenkomt met de grondwaarheid. Met aanvullende domeinspecifieke fijnafstemming bereikt het LVLM-raamwerk meer dan 93% F1, en handelt het uitdagende gevallen zoals zware watermerken, laag contrast en dichte tabellen veel beter af dan de traditionele aanpak. Zorgvuldige experimenten tonen dat de documenttype-classifier en de voorbeeldprompts bijzonder belangrijk zijn: het weghalen ervan veroorzaakt grote dalingen in nauwkeurigheid, wat het idee ondersteunt dat gerichte, invoer‑bewuste prompts essentieel zijn.
Wat dit betekent voor alledaags documentwerk
In eenvoudige termen laat dit onderzoek zien hoe je een algemeen AI-model dat kan “zien en praten” kunt omvormen tot een betrouwbare kantoorassistent die veel soorten officiële documenten kan lezen met minimale maatwerkconfiguratie. Door eerst te vragen: “Welk type formulier is dit?” en het model vervolgens een korte, op maat gemaakte set voorbeelden en instructies te geven, wordt het systeem zowel nauwkeuriger als eenvoudiger op schaal te implementeren. Deze aanpak kan taken stroomlijnen zoals compliancycontroles, aanbestedingsbeoordelingen en backoffice-gegevensinvoer, en het wijst op een bredere les: het slim sturen van grote modellen met de juiste context kan net zo krachtig zijn als ze groter maken of helemaal opnieuw trainen.
Bronvermelding: Li, H., Chen, G., Xia, J. et al. Visual information extraction from documents via classification-guided large vision-language models. Sci Rep 16, 14158 (2026). https://doi.org/10.1038/s41598-026-49319-z
Trefwoorden: documentbegrip, informatie-extractie, visie-taalmodellen, kantoorsautomatisering, prompt engineering