Clear Sky Science · sv
Visuell informationsutvinning från dokument via klassificeringsstyrda stora vision-språk-modeller
Hjälpa datorer att läsa stökiga pappersdokument
Moderna kontor drunknar i digitalt pappersarbete—licenser, ID-kort, intyg, kvitton—som ofta lagras som inskannade bilder eller foton. I dessa bilder finns viktiga fakta som namn, datum och ID‑nummer som måste kontrolleras och överföras till databaser. Att mata in detta manuellt är långsamt och felbenäget, medan dagens automatiska system fortfarande kämpar med röriga layouter, stämplar, suddighet och många olika dokumentstilar. Denna artikel presenterar ett nytt sätt att låta AI ”läsa” sådana dokument mer exakt med mindre mänsklig märkning och uppsättning.
Varför traditionella verktyg inte räcker
De flesta befintliga system behandlar dokumentförståelse som en strikt löpande band‑process. Först försöker en optisk teckenigenkänning (OCR) hitta och läsa varje textbit i en bild. Sedan analyserar en andra modell den texten för att avgöra vilka delar som är viktiga—till exempel företagsnamnet eller intygsnumret. Detta fungerar hyfsat på rena, enhetliga formulär, men fallerar när dokument varierar i layout, innehåller tabeller eller är täckta av sigill, vattenstämplar eller dålig belysning. Att förbättra dessa system innebär ofta att samla många märkta exempel för varje ny dokumenttyp och noggrant utforma regler eller modeller för varje fall, vilket är kostsamt och svårt att skala upp.
En smartare väg att styra vision-språk‑modeller
Stora vision‑språk‑modeller (LVLMs) kan se en bild och generera text, ungefär som kraftfulla assistenter som kan ”se”. I princip skulle de kunna läsa dokument direkt, utan en separat OCR‑motor. Men när de matas med många olika dokumenttyper under en enda generell instruktion blir dessa modeller ofta förvirrade, hittar på värden som inte finns, eller missar fina detaljer. Författarna föreslår ett ”klassificeringsstyrt” ramverk som delar upp uppgiften i två steg: först, avgör snabbt vilken typ av dokument bilden är; sedan använd det beslutet för att bygga en skräddarsydd prompt som talar om för LVLM vilka fält som ska extraheras och hur svaren ska formateras. Denna design låter modellen fokusera på en snävare, tydligare uppgift varje gång istället för att gissa mellan alla möjliga formulär på en gång.
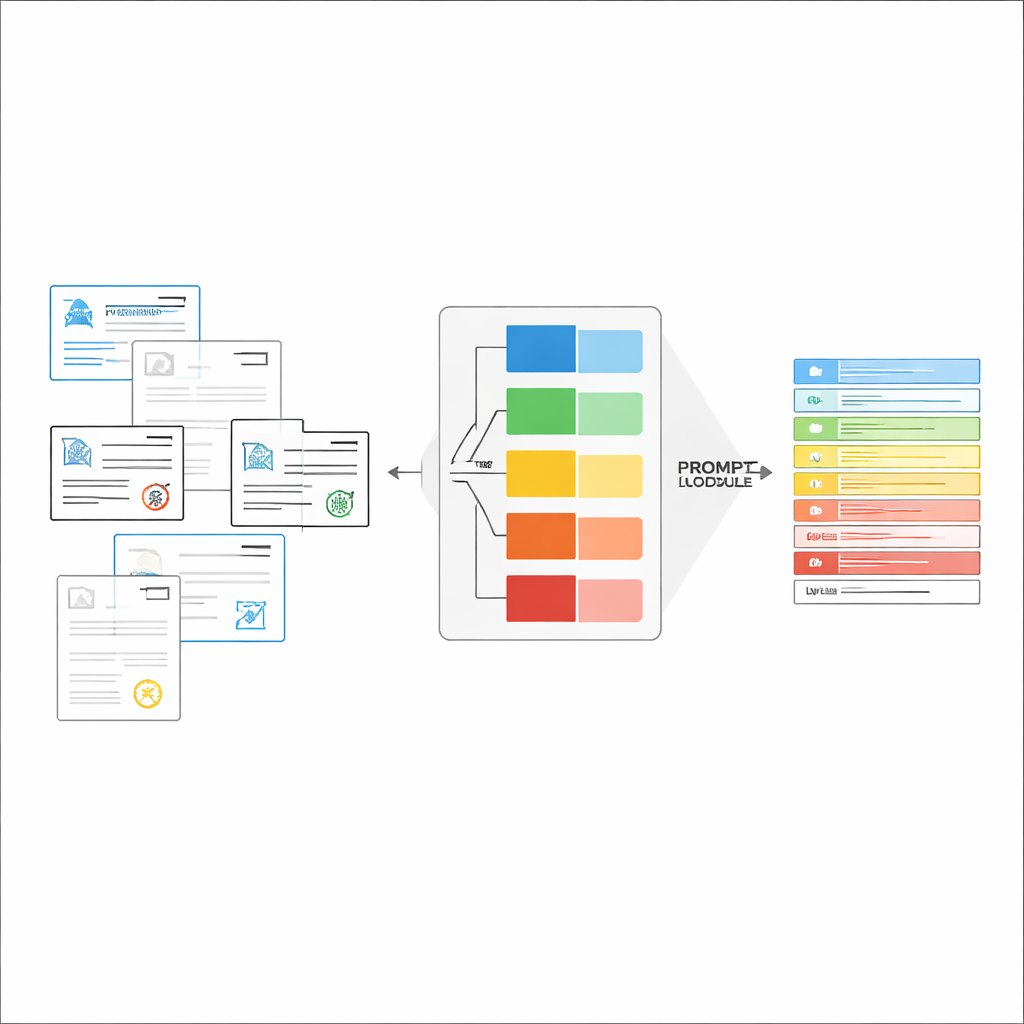
Bygga precis‑lagom‑instruktioner i farten
När dokumenttypen är igenkänd sätter systemet ihop en kort, anpassad instruktion för LVLM. En gemensam del av prompten förklarar det allmänna uppdraget—extrahera specifika poster, följ en strikt JSON‑struktur, använd konsekventa datumformat och markera oläsbara fält som ”unidentified.” Ovanpå detta läggs typ‑specifika delar: den exakta listan över fält som krävs för det aktuella intyget och några exempel på indata och utdata som visar hur korrekt extraktion ser ut. Denna in‑context‑inlärning ger LVLM konkreta demonstrationer för varje dokumenttyp utan att ändra dess interna parametrar. Författarna visar, med idéer från informationsteori, att sådana fokuserade prompts fungerar som ”villkorlig beräkning”: de tar bort irrelevanta instruktioner, minskar distraktion i modellens uppmärksamhet och gör bättre användning av varje genererat token.
Tester i verkligheten på anbuds‑dokument
För att se hur väl detta fungerar i praktiken byggde forskarna en stor, realistisk datamängd från en elektronisk anbudsplattform, innehållande nästan 100 000 bilder som täcker 16 typer av intyg, från företagslicenser och socialförsäkringshandlingar till säkerhets‑ och kvalitetsintyg. Dessa dokument skiljer sig mycket i layoutens komplexitet, textmängd och visuellt brus. Det nya ramverket testades i två lägen: rent zero‑shot, med en färdig LVLM och den nya promptstrategin, och en finkalibrerad version anpassad till domänen med en lättviktig träningsmetod. I båda fallen jämfördes det med en stark referensmetod som kombinerade state‑of‑the‑art OCR med en modern modell för informationsutvinning.
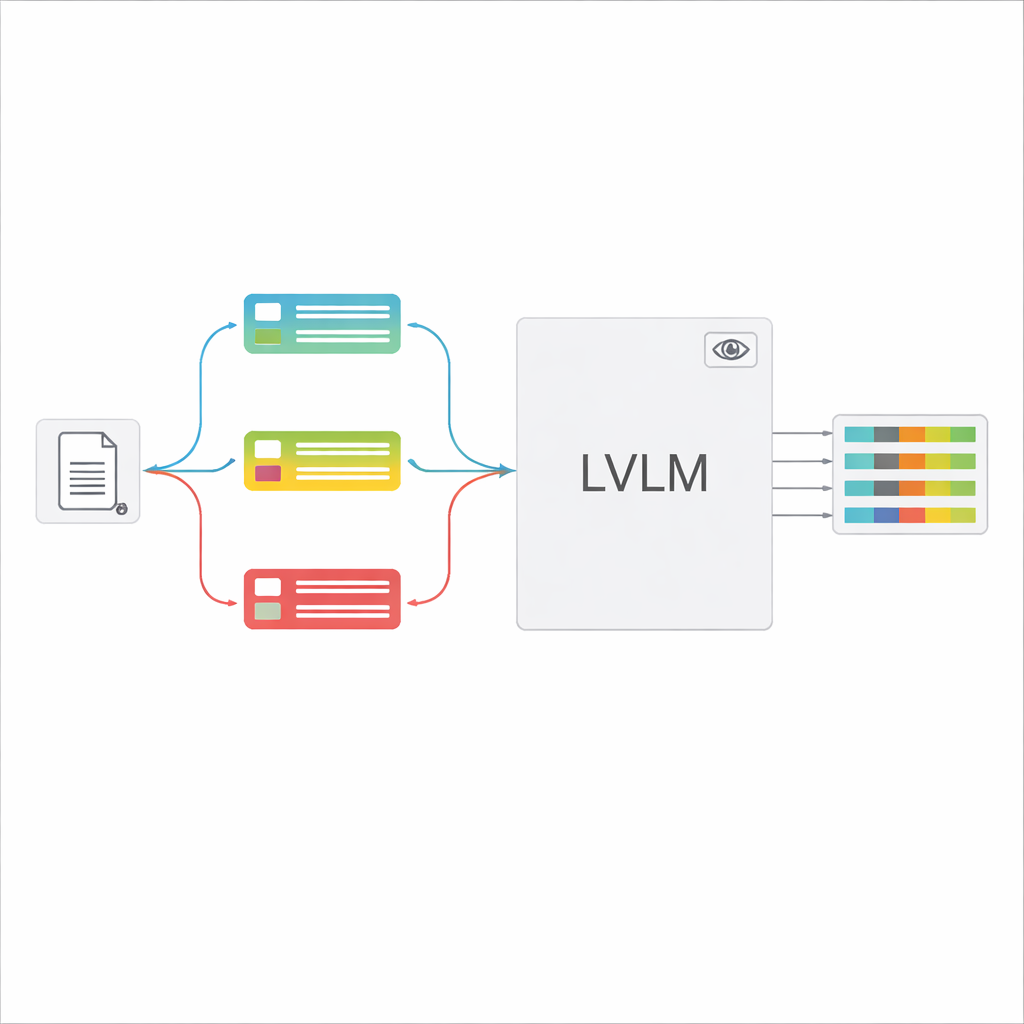
Stora förbättringar i noggrannhet med mindre manuellt arbete
Resultaten är slående. Även utan finkalibrering slår den klassificeringsstyrda LVLM den övervakade OCR‑baserade pipelinen med över 18 procentenheter i F1‑poäng (en vanlig noggrannhetsmätning) och förbättrar hur väl den extraherade texten matchar sanningen. Med ytterligare domänspecifik finkalibrering når LVLM‑ramverket över 93 % F1, och hanterar svåra fall som kraftiga vattenstämplar, låg kontrast och täta tabeller mycket bättre än den traditionella metoden. Omsorgsfulla experiment visar att dokumenttypklassificeraren och promptexemplen är särskilt viktiga: att ta bort dem leder till stora nedgångar i noggrannhet, vilket stöder idén att målinriktade, inputmedvetna prompts är nyckeln.
Vad detta betyder för vardagligt dokumentarbete
I vardagliga termer visar denna forskning hur man förvandlar en allmän AI som kan ”se och tala” till en pålitlig kontorsassistent som kan läsa många typer av officiella dokument med minimal anpassning. Genom att först fråga ”vilken typ av formulär är detta?” och sedan ge modellen en kort, skräddarsydd uppsättning exempel och instruktioner blir systemet både mer exakt och lättare att driftsätta i skala. Denna metod kan effektivisera uppgifter som efterlevnadskontroller, anbudsgranskningar och back‑office datainmatning, och den antyder en bredare läxa: att styra stora modeller smart med rätt kontext kan vara lika kraftfullt som att göra dem större eller träna dem från grunden.
Citering: Li, H., Chen, G., Xia, J. et al. Visual information extraction from documents via classification-guided large vision-language models. Sci Rep 16, 14158 (2026). https://doi.org/10.1038/s41598-026-49319-z
Nyckelord: dokumentförståelse, informationsutvinning, vision-språk-modeller, kontorsautomation, promptdesign