Clear Sky Science · fr
Extraction d'informations visuelles à partir de documents via des grands modèles vision‑langage guidés par classification
Aider les ordinateurs à lire des documents désordonnés
Les bureaux modernes sont submergés par des documents numériques — licences, pièces d'identité, certificats, reçus — souvent stockés sous forme de scans ou de photos. Cachées dans ces images se trouvent des informations clés comme des noms, des dates et des numéros d'identification qu'il faut vérifier et saisir dans des bases de données. Retaper ces informations à la main est lent et source d'erreurs, tandis que les systèmes automatisés actuels peinent encore face aux mises en page encombrées, aux tampons, au flou et à la grande variété de formats. Cet article présente une nouvelle méthode pour permettre à l'IA de « lire » ces documents avec plus de précision tout en exigeant moins d'annotations et de configurations humaines.
Pourquoi les outils traditionnels montrent leurs limites
La plupart des systèmes actuels considèrent la compréhension de documents comme une chaîne de production stricte. D'abord, un moteur de reconnaissance optique de caractères (OCR) tente de repérer et de lire chaque fragment de texte dans l'image. Ensuite, un second modèle analyse ce texte pour décider quelles parties sont importantes — par exemple le nom de l'entreprise ou le numéro de certificat. Cela fonctionne assez bien sur des formulaires propres et uniformes, mais échoue lorsque les documents varient de mise en page, contiennent des tableaux ou sont recouverts de sceaux, de filigranes ou soumis à un mauvais éclairage. Améliorer ces systèmes implique généralement de collecter de nombreux exemples annotés pour chaque type de document et de concevoir des règles ou modèles spécifiques à chaque cas, ce qui coûte cher et ne scale pas facilement.
Une manière plus intelligente de guider les modèles vision‑langage
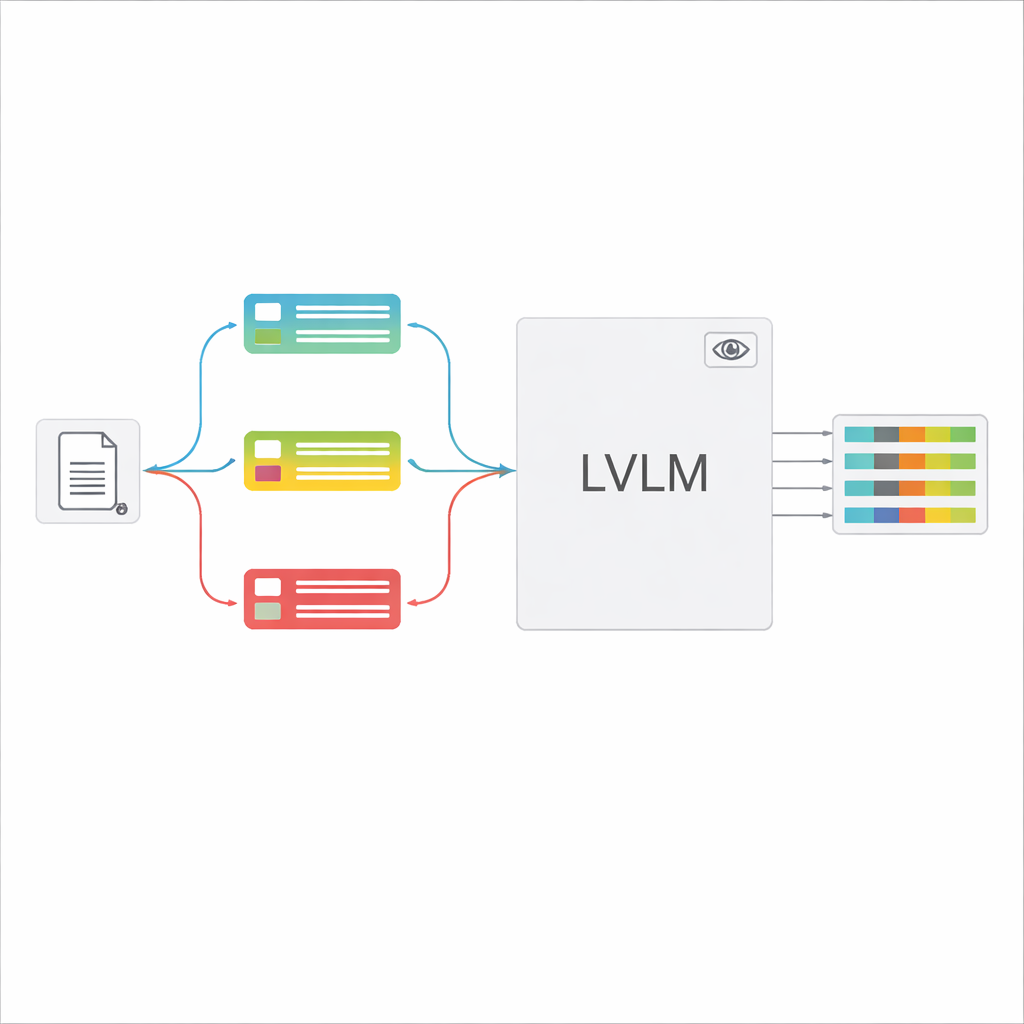
Les grands modèles vision‑langage (LVLM) peuvent analyser une image et générer du texte, à l'instar d'assistants puissants capables de « voir ». En principe, ils pourraient lire les documents directement, sans moteur OCR séparé. Cependant, lorsqu'on leur présente de nombreux types de documents avec une instruction générique, ces modèles se retrouvent souvent confus, inventent des valeurs qui n'existent pas (hallucinations) ou passent à côté de détails fins. Les auteurs proposent un cadre « guidé par classification » qui décompose la tâche globale en deux étapes : d'abord, décider rapidement du type de document ; ensuite, utiliser cette décision pour construire un prompt sur mesure qui indique au LVLM exactement quels champs extraire et comment formater les réponses. Cette conception permet au modèle de se concentrer à chaque fois sur une tâche plus étroite et claire au lieu d'essayer de deviner parmi tous les formulaires possibles.
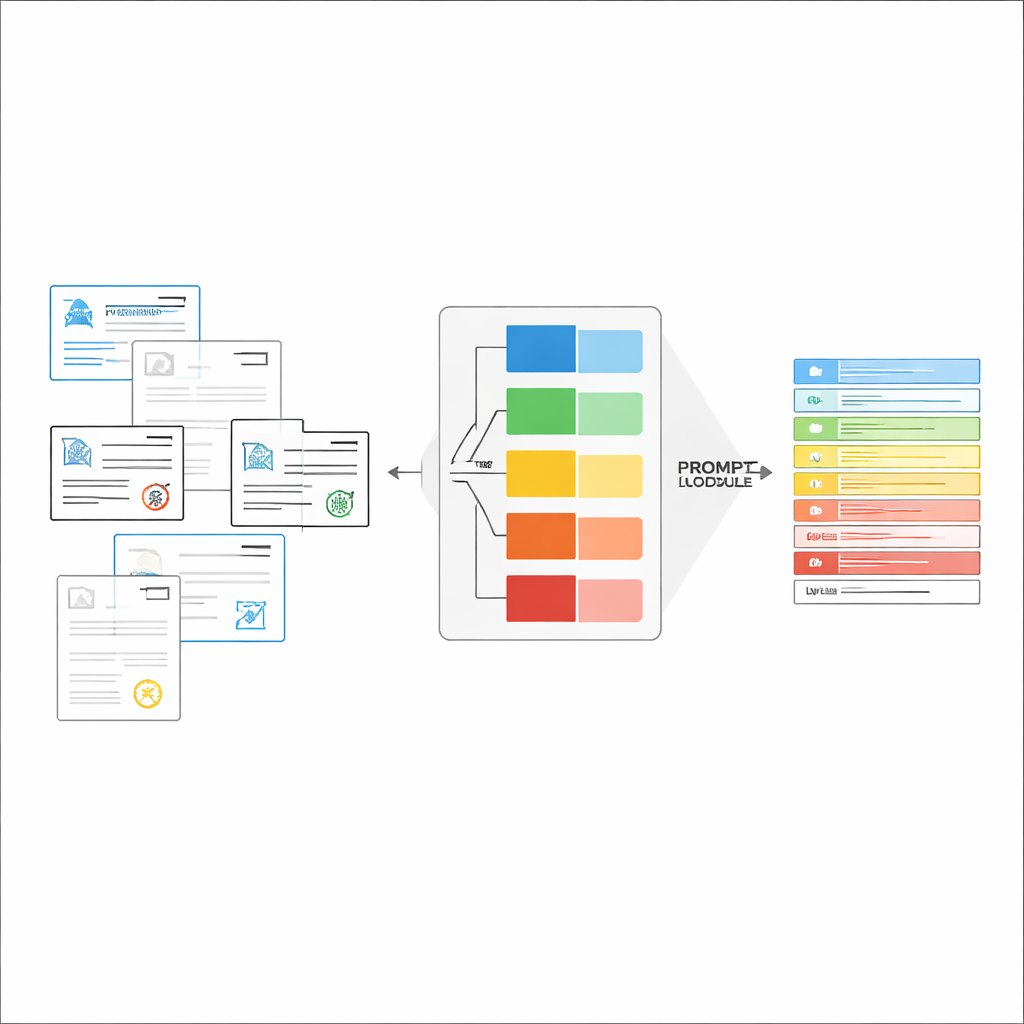
Construire des instructions adaptées à la volée
Une fois le type de document reconnu, le système assemble une instruction courte et personnalisée pour le LVLM. Une partie commune du prompt explique la tâche générale — extraire des éléments spécifiques, respecter une structure JSON stricte, utiliser des formats de date cohérents et marquer les champs illisibles comme « non identifié ». À cela s'ajoutent des éléments propres au type : la liste exacte des champs requis pour ce certificat et quelques exemples d'entrées et de sorties montrant ce qu'est une extraction correcte. Cet apprentissage « in‑context » fournit au LVLM des démonstrations concrètes pour chaque type de document sans modifier ses paramètres internes. Les auteurs montrent, en s'appuyant sur des idées de la théorie de l'information, que de tels prompts ciblés agissent comme une « computation conditionnelle » : ils éliminent les instructions non pertinentes, réduisent les distractions dans l'attention du modèle et optimisent l'utilisation de chaque jeton généré.
Tests en conditions réelles sur des documents d'appel d'offres
Pour mesurer l'efficacité de l'approche, les chercheurs ont constitué un grand jeu de données réaliste à partir d'une plateforme d'appels d'offres électronique, contenant près de 100 000 images couvrant 16 types de certificats, des licences commerciales et dossiers de sécurité sociale aux certifications de sécurité et de qualité. Ces documents varient fortement en complexité de mise en page, en quantité de texte et en bruit visuel. Le nouveau cadre a été testé en deux modes : en zéro‑shot pur, en utilisant un LVLM prêt à l'emploi avec la nouvelle stratégie de prompting, et en version fine‑tuned, adaptée au domaine via une technique d'entraînement légère. Dans les deux cas, ils l'ont comparé à une base solide combinant un OCR de pointe et un modèle moderne d'extraction d'informations.
Fortes gains d'exactitude avec moins d'effort manuel
Les résultats sont frappants. Même sans fine‑tuning, le LVLM guidé par classification surpasse le pipeline supervisé basé sur l'OCR de plus de 18 points de pourcentage en F1‑score (une mesure courante de précision) et améliore la concordance entre le texte extrait et la vérité terrain. Avec un fine‑tuning spécifique au domaine, le cadre LVLM atteint plus de 93 % de F1, gérant bien mieux que l'approche traditionnelle des cas difficiles comme les forts filigranes, le faible contraste et les tableaux denses. Des expériences soignées montrent que le classifieur de type de document et les exemples inclus dans le prompt sont particulièrement importants : les supprimer entraîne de fortes baisses de précision, ce qui confirme que des prompts ciblés et dépendants de l'entrée sont essentiels.
Que signifie cela pour le travail documentaire quotidien ?
Concrètement, cette recherche montre comment transformer une IA généraliste capable de « voir et parler » en un assistant de bureau fiable, capable de lire de nombreux types de documents officiels avec un minimum de configuration spécifique. En posant d'abord la question « quel type de formulaire est‑ce ? » puis en fournissant au modèle un jeu court et adapté d'exemples et d'instructions, le système devient à la fois plus précis et plus facile à déployer à grande échelle. Cette approche pourrait rationaliser des tâches telles que les contrôles de conformité, l'examen des offres et la saisie de données en back‑office, et suggère une leçon plus générale : guider intelligemment les grands modèles avec le bon contexte peut être aussi puissant que les agrandir ou les réentraîner depuis zéro.
Citation: Li, H., Chen, G., Xia, J. et al. Visual information extraction from documents via classification-guided large vision-language models. Sci Rep 16, 14158 (2026). https://doi.org/10.1038/s41598-026-49319-z
Mots-clés: compréhension de documents, extraction d'informations, modèles vision‑langage, automatisation bureautique, ingénierie de prompt