Clear Sky Science · de
Visuelle Informationsextraktion aus Dokumenten durch klassifikationsgesteuerte große Vision‑Language‑Modelle
Computern helfen, unordentliche Unterlagen zu lesen
Moderne Büros ersticken an digitalen Unterlagen – Lizenzen, Ausweise, Zertifikate, Belege – die oft als eingescannte Bilder oder Fotos abgelegt werden. In diesen Bildern verbergen sich wichtige Fakten wie Namen, Daten und Ausweisnummern, die geprüft und in Datenbanken übertragen werden müssen. Das manuelle Abtippen dieser Informationen ist langsam und fehleranfällig, während heutige automatisierte Systeme bei unübersichtlichem Layout, Stempeln, Unschärfe und den vielen verschiedenen Dokumentstilen noch Probleme haben. Dieses Paper stellt eine neue Methode vor, mit der KI solche Dokumente genauer lesen kann und gleichzeitig weniger menschliche Kennzeichnung und Einrichtung benötigt.
Warum herkömmliche Werkzeuge nicht ausreichen
Die meisten bestehenden Systeme behandeln Dokumentverständnis als straffe Produktionskette. Zuerst versucht eine optische Zeichenerkennung (OCR), jeden Text im Bild zu finden und zu lesen. Dann analysiert ein zweites Modell diesen Text, um zu entscheiden, welche Teile wichtig sind – etwa Firmenname oder Zertifikatnummer. Das funktioniert bei sauberen, einheitlichen Formularen ganz gut, scheitert aber, wenn Dokumente im Layout variieren, Tabellen enthalten oder von Siegeln, Wasserzeichen oder schlechter Beleuchtung überlagert sind. Diese Systeme zu verbessern bedeutet meist, viele gelabelte Beispiele für jeden neuen Dokumenttyp zu sammeln und für jeden Fall Regeln oder Modelle sorgfältig zu entwerfen, was kostspielig ist und sich schwer skalieren lässt.
Ein klügerer Weg, Vision‑Language‑Modelle zu lenken
Große Vision‑Language‑Modelle (LVLMs) können ein Bild betrachten und Text erzeugen, ähnlich wie leistungsfähige Assistenten, die „sehen“ können. Grundsätzlich könnten sie Dokumente direkt lesen, ohne eine separate OCR‑Engine. Werden sie jedoch mit vielen verschiedenen Dokumenttypen und einer generischen Anweisung gefüttert, geraten diese Modelle oft in Verwirrung, halluzinieren Werte, die nicht vorhanden sind, oder übersehen feine Details. Die Autorinnen und Autoren schlagen ein „klassifikationsgesteuertes“ Framework vor, das die Gesamtaufgabe in zwei Schritte gliedert: Zuerst wird rasch entschieden, um welchen Dokumenttyp es sich handelt; zweitens wird diese Entscheidung genutzt, um einen maßgeschneiderten Prompt zu erzeugen, der das LVLM genau anweist, welche Felder zu extrahieren sind und wie die Antworten zu formatieren sind. Dieses Design lässt das Modell jedes Mal an einer engeren, klareren Aufgabe arbeiten, statt zwischen allen möglichen Formularen zugleich zu raten.
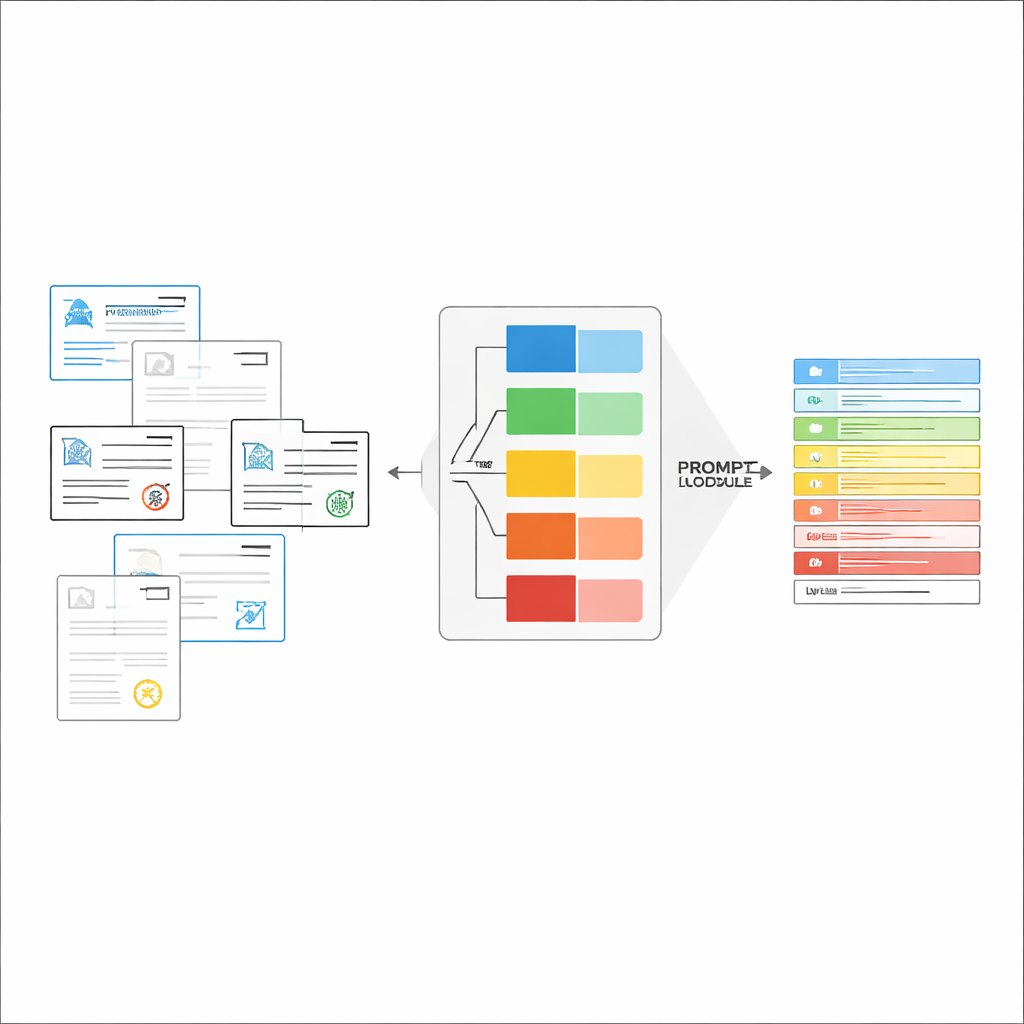
Passgenaue Anweisungen on the fly erstellen
Sobald der Dokumenttyp erkannt ist, stellt das System eine kurze, angepasste Anweisung für das LVLM zusammen. Ein gemeinsamer Teil des Prompts erklärt die allgemeine Aufgabe – spezifische Elemente extrahieren, eine strikte JSON‑Struktur einhalten, einheitliche Datumsformate verwenden und unlesbare Felder als „unidentifiziert“ kennzeichnen. Darüber werden typspezifische Teile ergänzt: die genaue Liste der für dieses Zertifikat benötigten Felder und einige Beispiel‑Eingaben und -Ausgaben, die zeigen, wie korrekte Extraktion aussieht. Dieses In‑Context‑Learning liefert dem LVLM konkrete Demonstrationen für jeden Dokumenttyp, ohne seine internen Parameter zu verändern. Die Autorinnen und Autoren zeigen mithilfe von Ideen aus der Informationstheorie, dass solche fokussierten Prompts wie „bedingte Rechnung“ wirken: Sie blenden irrelevante Anweisungen aus, reduzieren Ablenkung in der Modellaufmerksamkeit und nutzen jedes generierte Token besser.
Tests in der Praxis an Ausschreibungsunterlagen
Um zu prüfen, wie gut das in der Praxis funktioniert, bauten die Forschenden einen großen, realistischen Datensatz von einer elektronischen Ausschreibungsplattform auf, der fast 100.000 Bilder mit 16 Arten von Zertifikaten umfasst – von Gewerbelizenzen und Sozialversicherungsnachweisen bis hin zu Sicherheits‑ und Qualitätszertifikaten. Diese Dokumente unterscheiden sich stark in Layoutkomplexität, Textmenge und visuellen Störungen. Das neue Framework wurde in zwei Modi getestet: rein Zero‑Shot, mit einem handelsüblichen LVLM und der neuen Prompt‑Strategie, und in einer feinabgestimmten Version, die mit einer leichten Trainingsmethode an die Domäne angepasst wurde. In beiden Fällen wurde mit einer starken Baseline verglichen, die hochmoderne OCR mit einem modernen Information‑Extraction‑Modell kombiniert.
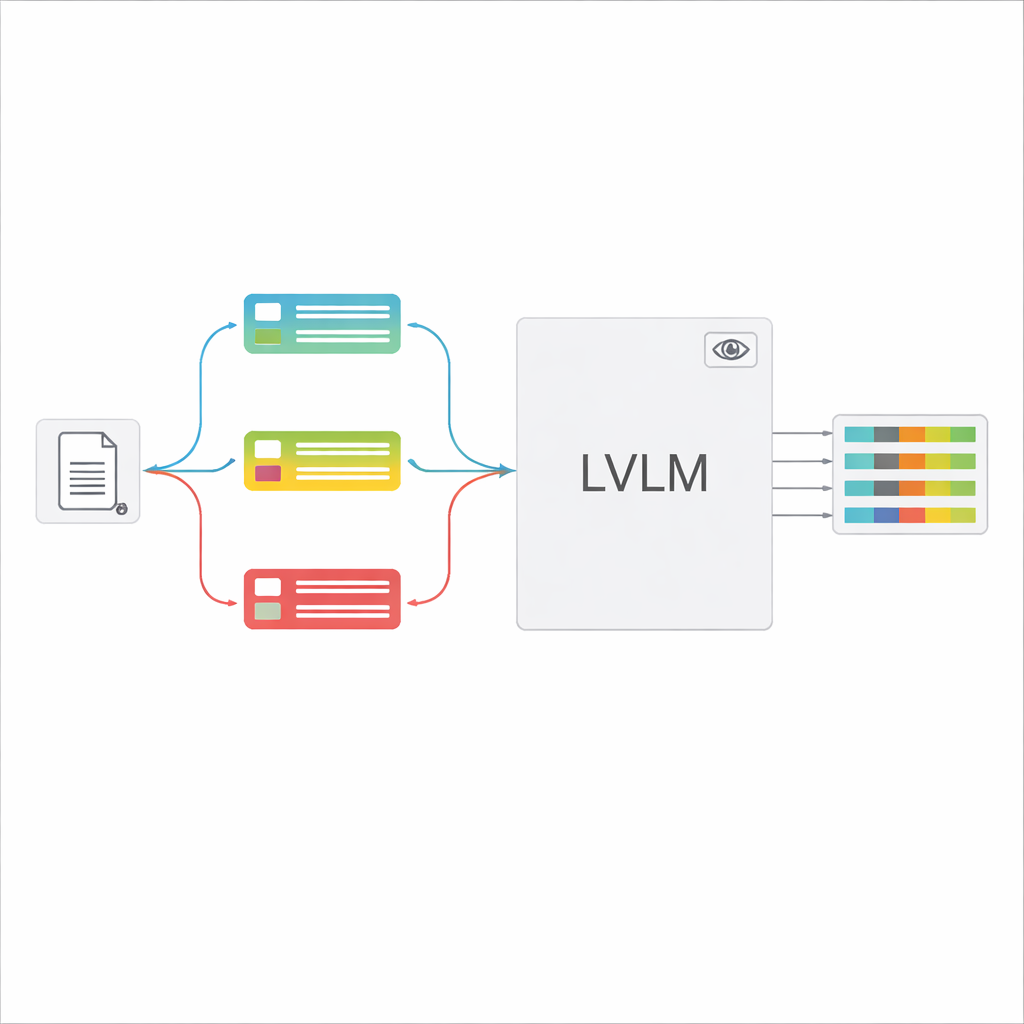
Hohe Genauigkeitsgewinne bei weniger manuellem Aufwand
Die Ergebnisse sind eindrücklich. Selbst ohne Fine‑Tuning übertrifft das klassifikationsgesteuerte LVLM die überwachte, OCR‑basierte Pipeline um über 18 Prozentpunkte im F1‑Score (ein übliches Maß für Genauigkeit) und verbessert die Übereinstimmung des extrahierten Textes mit der Referenz. Mit zusätzlichem domänenspezifischem Fine‑Tuning erreicht das LVLM‑Framework mehr als 93% F1 und bewältigt schwierige Fälle wie starke Wasserzeichen, geringen Kontrast und dichte Tabellen deutlich besser als der traditionelle Ansatz. Sorgfältige Experimente zeigen, dass der Dokumenttyp‑Klassifikator und die Prompt‑Beispiele besonders wichtig sind: Werden sie entfernt, fallen die Genauigkeitswerte stark ab, was die These stützt, dass zielgerichtete, eingangsbezogene Prompts entscheidend sind.
Was das für die tägliche Dokumentarbeit bedeutet
Alltagsgerecht zeigt diese Forschung, wie sich eine allgemeine KI, die „sehen und sprechen“ kann, in einen verlässlichen Büroassistenten verwandeln lässt, der viele Arten offizieller Dokumente mit minimaler kundenspezifischer Einrichtung liest. Indem das System zuerst fragt: „Welcher Formularart haben wir es hier zu tun?“ und dem Modell anschließend eine kurze, maßgeschneiderte Menge an Beispielen und Anweisungen gibt, wird es sowohl genauer als auch leichter in großem Maßstab einsetzbar. Dieser Ansatz könnte Aufgaben wie Compliance‑Prüfungen, Angebotsprüfungen und Back‑Office‑Dateneingabe vereinfachen und deutet auf eine breitere Lehre hin: Große Modelle klug mit dem richtigen Kontext zu führen kann genauso wirkungsvoll sein wie sie größer zu machen oder von Grund auf neu zu trainieren.
Zitation: Li, H., Chen, G., Xia, J. et al. Visual information extraction from documents via classification-guided large vision-language models. Sci Rep 16, 14158 (2026). https://doi.org/10.1038/s41598-026-49319-z
Schlüsselwörter: Dokumentverständnis, Informationsextraktion, Vision‑Language‑Modelle, Büroautomatisierung, Prompt‑Engineering