Clear Sky Science · pt
Extração de informação visual de documentos via grandes modelos visão-linguagem guiados por classificação
Ajudando computadores a ler papéis bagunçados
Os escritórios modernos estão afogados em documentos digitais—licenças, carteiras de identidade, certificados, recibos—frequentemente armazenados como imagens escaneadas ou fotos. Ocultos nessas imagens estão fatos-chave como nomes, datas e números de identificação que precisam ser verificados e copiados para bancos de dados. Reescrever manualmente essas informações é lento e sujeito a erros, enquanto os sistemas automatizados atuais ainda têm dificuldades com layouts confusos, carimbos, desfoque e os muitos estilos de documento. Este artigo apresenta uma nova forma de fazer a IA “ler” esses documentos com mais precisão e exigindo menos rotulagem e configuração manual.
Por que as ferramentas tradicionais ficam para trás
A maioria dos sistemas existentes trata a compreensão de documentos como uma linha de montagem rígida. Primeiro, um motor de reconhecimento ótico de caracteres (OCR) tenta localizar e ler cada pedaço de texto na imagem. Em seguida, um segundo modelo analisa esse texto para decidir quais trechos são importantes—como o nome da empresa ou o número do certificado. Isso funciona razoavelmente bem em formulários limpos e uniformes, mas falha quando os documentos variam no layout, contêm tabelas ou estão cobertos por selos, marcas d’água ou iluminação ruim. Melhorar esses sistemas geralmente significa coletar muitos exemplos rotulados para cada novo tipo de documento e projetar regras ou modelos específicos para cada caso, o que é caro e difícil de escalar.
Uma forma mais inteligente de guiar modelos visão-linguagem
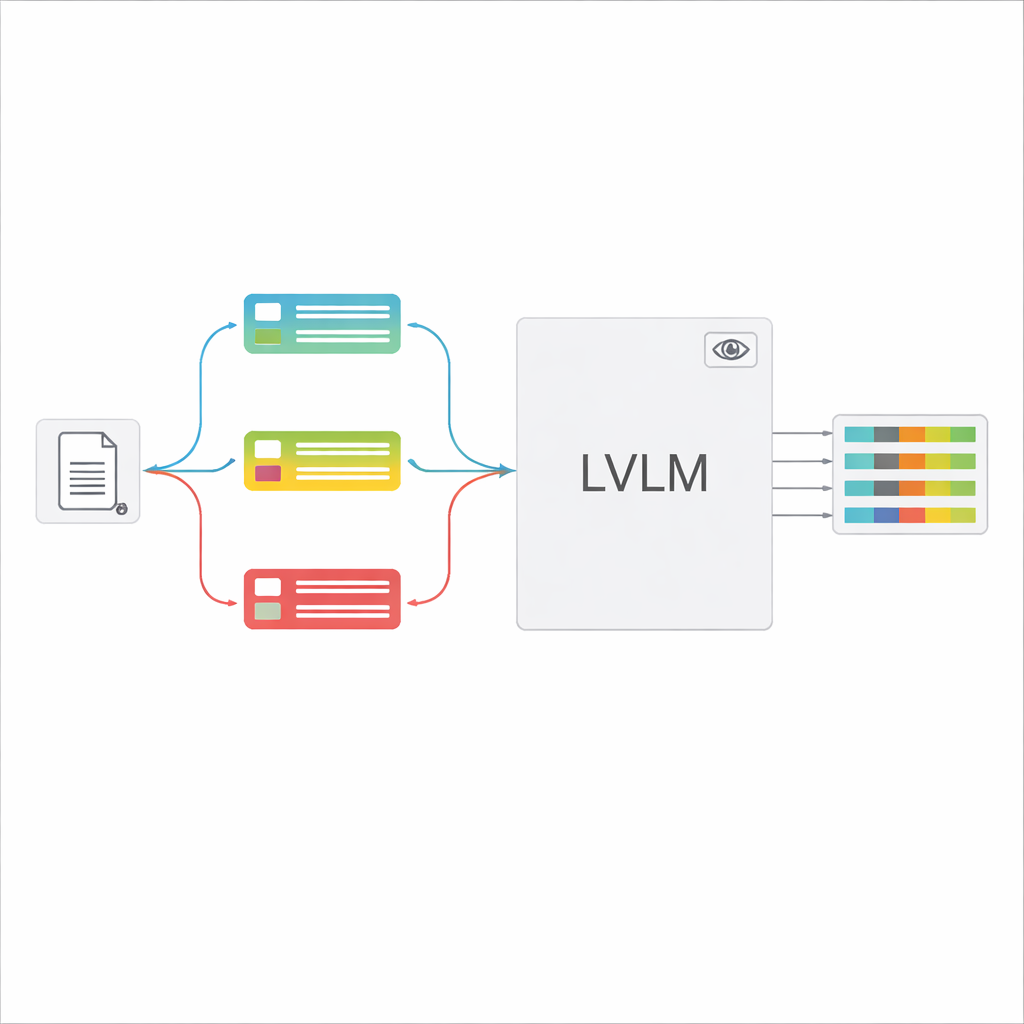
Grandes modelos visão‑linguagem (LVLMs) podem olhar para uma imagem e gerar texto, semelhantes a assistentes poderosos que sabem “ver”. Em princípio, eles poderiam ler documentos diretamente, sem um motor OCR separado. No entanto, ao receber muitos tipos de documentos com uma instrução genérica, esses modelos frequentemente se confundem, alucinam valores que não estão presentes ou deixam passar detalhes finos. Os autores propõem uma estrutura “guiada por classificação” que divide a tarefa em duas etapas: primeiro, decidir rapidamente que tipo de documento a imagem representa; segundo, usar essa decisão para construir um prompt sob medida que diga ao LVLM exatamente quais campos extrair e como formatar as respostas. Esse desenho permite que o modelo foque numa tarefa mais estreita e clara a cada vez, em vez de adivinhar entre todas as formas possíveis de uma só vez.
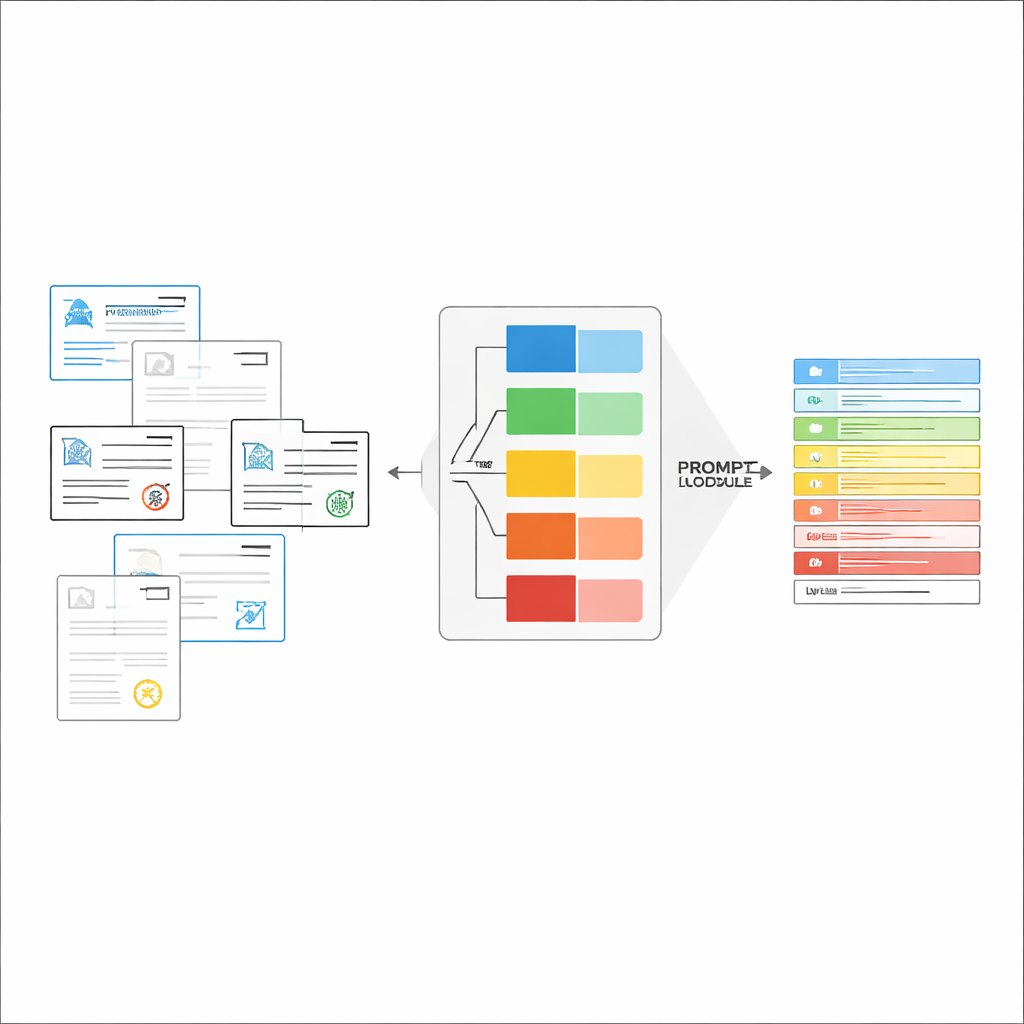
Montando instruções na medida certa em tempo real
Uma vez reconhecido o tipo de documento, o sistema monta uma instrução curta e personalizada para o LVLM. Uma parte compartilhada do prompt explica a tarefa geral—extrair itens específicos, respeitar uma estrutura JSON rigorosa, usar formatos de data consistentes e marcar campos ilegíveis como “não identificado”. Sobre isso são adicionadas peças específicas do tipo: a lista exata de campos necessários para aquele certificado e alguns exemplos de entrada e saída que mostram como a extração correta deve ser feita. Esse aprendizado em contexto fornece ao LVLM demonstrações concretas para cada tipo de documento sem alterar seus parâmetros internos. Os autores mostram, usando ideias da teoria da informação, que prompts focados funcionam como “computação condicional”: eles eliminam instruções irrelevantes, reduzem distrações na atenção do modelo e fazem melhor uso de cada token gerado.
Testes do mundo real em documentos de licitação
Para avaliar o desempenho na prática, os pesquisadores construíram um grande conjunto de dados realista a partir de uma plataforma eletrônica de licitações, contendo quase 100.000 imagens abrangendo 16 tipos de certificados, desde alvarás e registros previdenciários até certificações de segurança e qualidade. Esses documentos variam amplamente em complexidade de layout, quantidade de texto e ruído visual. A nova estrutura foi testada em dois modos: puramente zero‑shot, usando um LVLM pronto com a nova estratégia de prompting, e uma versão ajustada (fine‑tuned) adaptada ao domínio com uma técnica de treinamento leve. Em ambos os casos, compararam-na a uma linha de base robusta que combinava OCR de ponta com um modelo moderno de extração de informação.
Grandes ganhos de precisão com menos esforço manual
Os resultados são marcantes. Mesmo sem fine‑tuning, o LVLM guiado por classificação supera o pipeline supervisionado baseado em OCR por mais de 18 pontos percentuais em F1 (uma medida comum de acurácia) e melhora a correspondência entre o texto extraído e a verdade de referência. Com fine‑tuning específico do domínio, a estrutura LVLM alcança mais de 93% de F1, lidando com casos desafiadores como marcas d’água pesadas, baixo contraste e tabelas densas muito melhor do que a abordagem tradicional. Experimentos cuidadosos mostram que o classificador de tipo de documento e os exemplos do prompt são especialmente importantes: removê‑los causa quedas grandes na precisão, corroborando a ideia de que prompts direcionados e sensíveis à entrada são essenciais.
O que isso significa para o trabalho cotidiano com documentos
Em termos práticos, esta pesquisa mostra como transformar uma IA de uso geral que pode “ver e falar” em um assistente de escritório confiável capaz de ler muitos tipos de documentos oficiais com configuração mínima. Ao primeiro perguntar “Que tipo de formulário é este?” e depois fornecer ao modelo um conjunto curto e personalizado de exemplos e instruções, o sistema fica ao mesmo tempo mais preciso e mais fácil de implantar em escala. Essa abordagem pode agilizar tarefas como verificações de conformidade, análises de propostas e entrada de dados nos bastidores, e sugere uma lição mais ampla: guiar inteligentemente grandes modelos com o contexto certo pode ser tão eficaz quanto torná‑los maiores ou treiná‑los do zero.
Citação: Li, H., Chen, G., Xia, J. et al. Visual information extraction from documents via classification-guided large vision-language models. Sci Rep 16, 14158 (2026). https://doi.org/10.1038/s41598-026-49319-z
Palavras-chave: compreensão de documentos, extração de informação, modelos visão-linguagem, automação de escritório, engenharia de prompts