Clear Sky Science · he
חילוץ מידע חזותי ממסמכים באמצעות מודלים גדולים חזון-שפה מונחים על ידי סיווג
לעזור למחשבים לקרוא ניירת מבולגנת
משרדים מודרניים טובעים בניירת דיגיטלית — רישיונות, תעודות זהות, אישורים, קבלות — שלעיתים שמורים כסריקות או תמונות. בתמונות הללו מוטמנים פרטים מרכזיים כמו שמות, תאריכים ומספרי זהות שיש לוודא ולהעתיק למסדי נתונים. הקלדה ידנית של המידע איטית ורגישה לשגיאות, בעוד שמערכות אוטומטיות כיום עדיין נאבקות בפריסות עמוסות, חותמות, טשטוש וסגנונות מסמכים רבים. המאמר הזה מציג שיטה חדשה שמאפשרת ל-AI «לקרוא» מסמכים כאלה בדיוק רב יותר עם פחות תיוג והגדרות שבוצעו בידי אדם.
מדוע הכלים המסורתיים לא עומדים ביעד
מרבית המערכות הקיימות מטפלות בהבנת מסמכים כקו ייצור קשיח. ראשית, מנוע זיהוי תווים אופטי (OCR) מנסה לזהות ולקרוא כל טקסט בתמונה. לאחר מכן מודל שני מנתח את הטקסט הזה כדי להחליט אילו חלקים חשובים — כגון שם החברה או מספר האישור. זה עובד באופן סביר על טפסים נקיים ואחידים, אך מתפרק כאשר המסמכים משתנים בפריסה, מכילים טבלאות, או מכוסים בחתמות, סימני מים או תאורה גרועה. שיפור המערכות האלו בדרך כלל דורש איסוף דוגמאות מתוייגות רבות לכל סוג מסמך ותכנון חוקים או מודלים מותאמים לכל מקרה — דבר יקר וקשה להרחבה.
דרך חכמה יותר להנחות מודלי חזון-שפה
מודלים גדולים חזון-שפה (LVLMs) יכולים להסתכל על תמונה וליצור טקסט, בדומה לעוזרים חזקים שיכולים «לראות». בעקרון, הם יוכלו לקרוא מסמכים ישירות, ללא מנוע OCR נפרד. עם זאת, כאשר מאכילים אותם בסוגים רבים של מסמכים עם הוראה כללית אחת, המודלים האלה לעתים מתבלבלים, מייצרים אמיתות מדומות שלא קיימות בפועל, או מפספסים פרטים עדינים. המחברים מציעים מסגרת «מונחית סיווג» שמפצלת את המשימה לשני שלבים: ראשית, להחליט במהירות איזה סוג מסמך התמונה מייצגת; שנית, להשתמש בהחלטה זו כדי לבנות פרומפט מותאם שמורה ל-LVLM בדיוק אילו שדות לחלץ וכיצד לעצב את התשובות. עיצוב זה מאפשר למודל להתמקד במשימה צרה ובהירה יותר בכל פעם במקום לנחש בין כל הטפסים האפשריים בבת אחת.
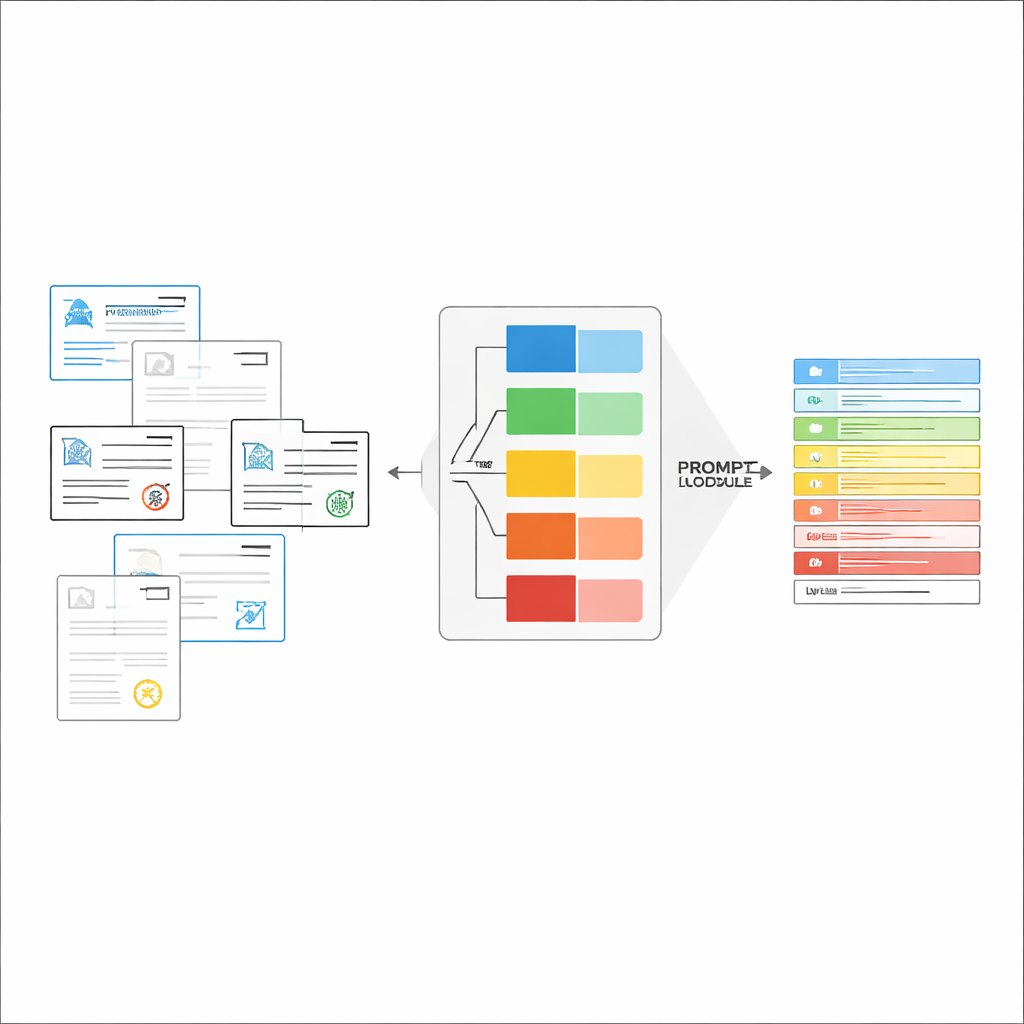
בניית הוראות מדויקות בזמן אמת
לאחר זיהוי סוג המסמך, המערכת מרכיבה הוראה קצרה ומותאמת ל-LVLM. חלק משותף בפרומפט מסביר את המשימה הכללית — לחלץ פריטים ספציפיים, לכבד מבנה JSON קפדני, להשתמש בפורמטי תאריכים עקביים ולסמן שדות בלתי קריאים כ"לא מזוהה". מעל לכך מוסיפים חלקים ספציפיים לסוג: רשימת השדות המדויקת הדרושה לאותו אישור וכמה דוגמאות של קלט ופלט שמדגימות מהו חילוץ נכון. למידה בהקשר זה נותנת ל-LVLM הדגמות קונקרטיות לכל סוג מסמך מבלי לשנות את הפרמטרים הפנימיים שלו. המחברים מראים, באמצעות רעיונות מתורת המידע, שפרומפטים ממוקדים כאלה פועלים כמו "חישוב מותנה": הם מסירים הוראות לא רלוונטיות, מפחיתים הסחות דעת בתשומת הלב של המודל ומשפרים את ניצול כל טוקן שנוצר.
מבחנים מעשיים על מסמכי מכרזים
כדי לבדוק עד כמה זה עובד בפועל, החוקרים בנו מאגר נתונים גדול וריאליסטי מפלטפורמת מכרזים אלקטרונית, הכולל כמעט 100,000 תמונות המכסות 16 סוגי אישורים, מרישיונות עסק ותעודות ביטוח לאומי ועד אישורי בטיחות ואיכות. מסמכים אלו שונים באופן נרחב במורכבות הפריסה, בכמות הטקסט וברעש הוויזואלי. המסגרת החדשה נבדקה בשני מצבים: מצב זירו-שוט טהור, באמצעות LVLM מוכן מהמדף עם אסטרטגיית הפרומפט החדשה, וגרסה מותאמת (fine-tuned) לתחום באמצעות טכניקת אימון קלת משקל. בשני המקרים השוו אותה לבסיס חזק ששילב OCR מהשורה הראשונה עם מודל מודרני לחילוץ מידע.
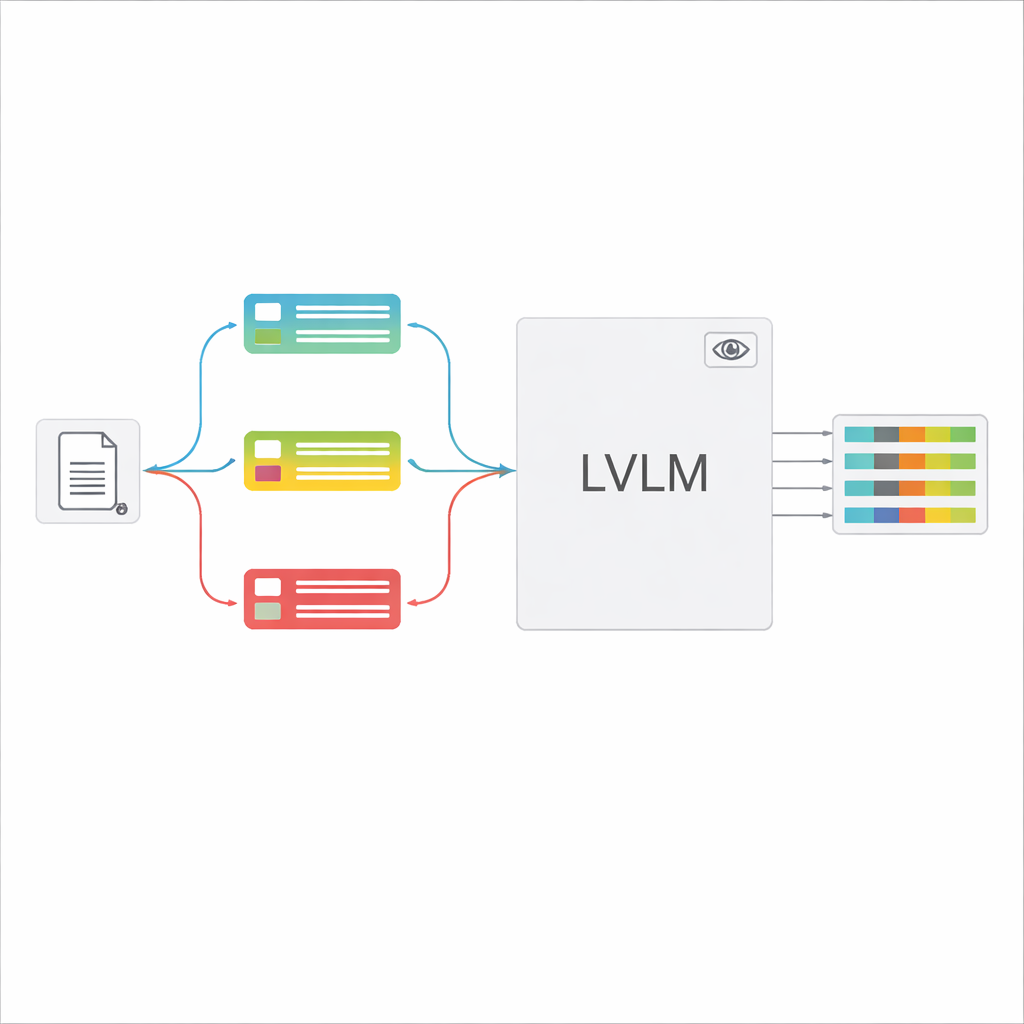
עליות דיוק משמעותיות עם פחות מאמץ ידני
התוצאות בולטות. גם ללא כוונון עדין, ה-LVLM המונחה בסיווג גובר על צינור מבוסס-תווית ו-OCR מפוקח ביותר מ-18 נקודות אחוז במדד F1 (מדד דיוק נפוץ) ומשפר את התאימות של הטקסט החילוץ לאמת השדה. עם כוונון נוסף המותאם לתחום, מסגרת ה-LVLM מגיעה ליותר מ-93% F1, ומתמודדת עם מקרים מאתגרים כמו סימני מים כבדים, ניגודיות נמוכה וטבלאות צפופות טוב בהרבה מהגישה המסורתית. ניסויים זהירים מראים שמחלקת הסיווג של סוג המסמך ודוגמאות הפרומפט חשובים במיוחד: הסרתם גורמת לירידות גדולות בדיוק, ותומכת ברעיון שפרומפטים ממוקדי-קלט הם המפתח.
מה זה אומר לעבודה יומיומית עם מסמכים
במונחים יומיומיים, המחקר הזה מראה איך להפוך AI כללי שיכול «לראות ולדבר» לעוזר משרד מהימן שיכול לקרוא סוגים רבים של מסמכים רשמיים עם התאמה צנועה מראש. על ידי שאילת השאלה הראשונה, "מה סוג הטופס הזה?" ואז מתן סט קצר ומותאם של דוגמאות והוראות, המערכת נהיית גם מדויקת יותר וגם קלה יותר לפריסה בקנה מידה. גישה זו יכולה לייעל משימות כמו בדיקות תאימות, בדיקות מכרזים והזנת נתונים למשרד האחורי, ומרמזת על לקח רחב יותר: הנחיה חכמה של מודלים גדולים עם ההקשר הנכון יכולה להיות כה חזקה כמו הגדלתם או אימונם מאפס.
ציטוט: Li, H., Chen, G., Xia, J. et al. Visual information extraction from documents via classification-guided large vision-language models. Sci Rep 16, 14158 (2026). https://doi.org/10.1038/s41598-026-49319-z
מילות מפתח: הבנת מסמכים, חילוץ מידע, מודלי חזון-שפה, אוטומציה משרדית, הנדסת פרומפטים