Clear Sky Science · ru
Извлечение визуальной информации из документов с помощью крупных визуально-языковых моделей, управляемых классификацией
Помочь компьютерам читать беспорядочные документы
Современные офисы тонут в цифровой документации — лицензии, удостоверения личности, сертификаты, квитанции — часто хранящиеся в виде отсканированных изображений или фотографий. В этих изображениях скрыты ключевые данные — имена, даты, номера документов — которые необходимо проверить и внести в базы данных. Ручной ввод этой информации медленный и подвержен ошибкам, а существующие автоматические системы всё ещё испытывают трудности с запутанными макетами, печатями, размытостью и множеством форматов документов. В этой работе предлагается новый способ позволить ИИ «читать» такие документы точнее при меньших затратах на разметку и настройку.
Почему традиционные инструменты недостаточны
Большинство существующих систем рассматривают понимание документов как конвейерный процесс. Сначала движок оптического распознавания символов (OCR) пытается обнаружить и прочитать весь текст на изображении. Затем вторая модель анализирует этот текст, чтобы определить, какие фрагменты важны — например, название компании или номер сертификата. Это работает достаточно хорошо для чистых, стандартных форм, но даёт сбои, когда документы различаются по макету, содержат таблицы или закрыты печатями, водяными знаками либо сняты при плохом освещении. Улучшение таких систем обычно требует сбора множества размеченных примеров для каждого нового типа документа и тщательной разработки правил или моделей для каждого случая, что дорого и трудно масштабируется.
Более умный способ направлять визуально-языковые модели
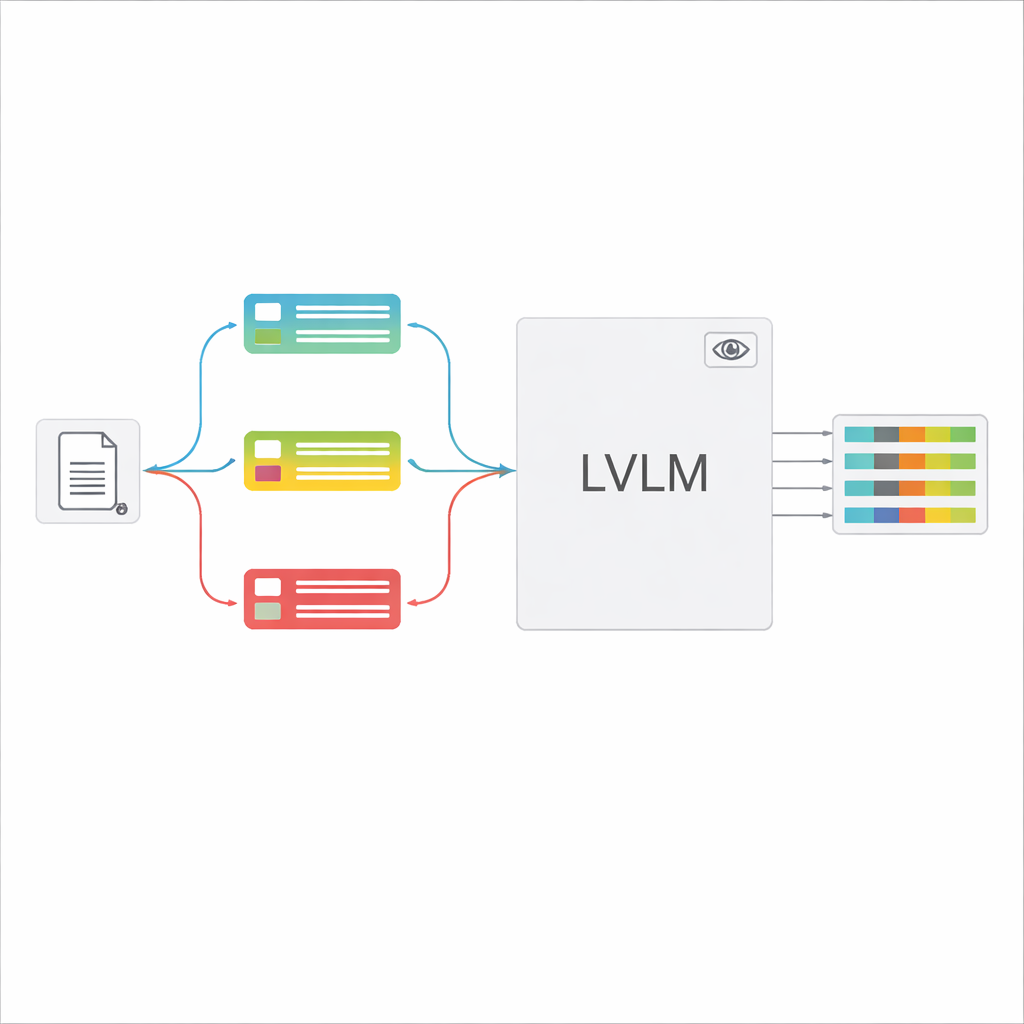
Крупные визуально‑языковые модели (LVLM) могут смотреть на изображение и генерировать текст, как мощные помощники, которые «видят». В принципе, они могли бы читать документы напрямую, без отдельного OCR. Однако при обработке множества разных типов документов с одной общей инструкцией такие модели часто путаются, порождают вымышленные значения, которых на самом деле нет, или пропускают тонкие детали. Авторы предлагают «руководящую классификацией» схему, которая разбивает задачу на два шага: сначала быстро определить, к какому типу относится изображение; затем на основе этого решения сформировать индивидуальную подсказку, которая точно указывает LVLM, какие поля извлечь и как оформить ответы. Такая архитектура позволяет модели каждый раз сосредотачиваться на более узкой и ясной задаче, вместо того чтобы угадывать среди всех возможных форм сразу.
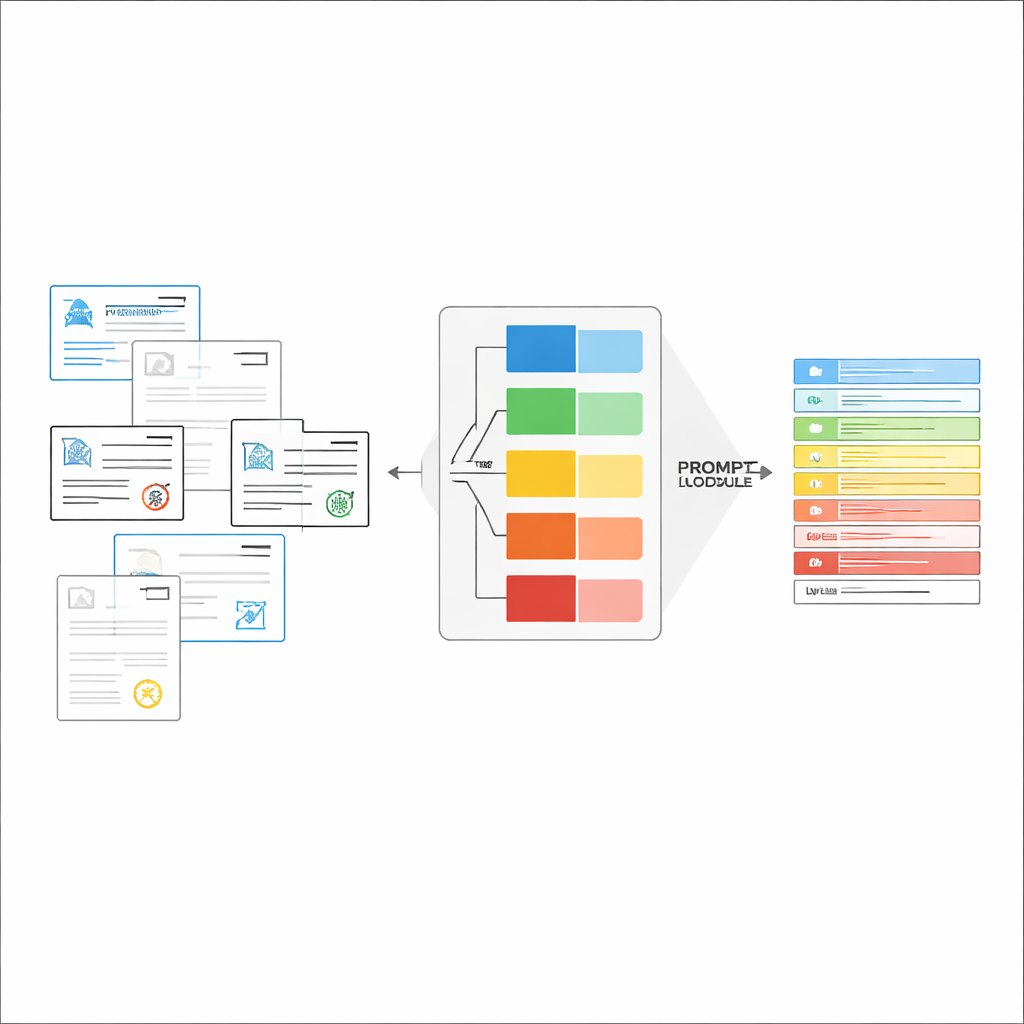
Динамическая сборка «в меру» точных инструкций
После распознавания типа документа система собирает короткую, настроенную инструкцию для LVLM. Общая часть подсказки объясняет основную задачу — извлечь конкретные элементы, соблюдать строгую JSON‑структуру, использовать единообразные форматы дат и помечать нечитаемые поля как «невыявлено». Сверху добавляются элементы, специфичные для типа: точный перечень полей, необходимых для данного сертификата, и несколько примеров входных данных и ожидаемых выходов, показывающих, как выглядит корректное извлечение. Такое обучение в контексте (in‑context learning) даёт LVLM конкретные демонстрации для каждого типа документа без изменения внутренних параметров модели. Авторы показывают, используя идеи из теории информации, что подобные целевые подсказки действуют как «условное вычисление»: они отбрасывают нерелевантные инструкции, уменьшают разброс внимания модели и повышают эффективность каждого сгенерированного токена.
Тесты в реальных условиях на документах для торгов
Чтобы оценить практическую эффективность, исследователи собрали большую реалистичную выборку с электронной торговой площадки, включающую почти 100 000 изображений 16 типов сертификатов — от бизнес‑лицензий и записей соцстраха до сертификатов безопасности и качества. Эти документы сильно различаются по сложности макета, объёму текста и визуальному шуму. Новую схему протестировали в двух режимах: полностью zero‑shot с использованием готовой LVLM и новой стратегией подсказок, и в варианте с дообучением, адаптированным к домену с помощью лёгкой техники обучения. В обоих случаях её сравнивали с сильной базовой системой, комбинирующей современный OCR и современную модель извлечения информации.
Большой прирост точности при меньших ручных усилиях
Результаты впечатляют. Даже без дообучения классификационно управляемая LVLM превосходит контролируемый OCR‑конвейер более чем на 18 процентных пунктов по F1‑мере (распространённой метрике точности) и улучшает совпадение извлечённого текста с эталоном. При дополнительном доменно‑специфическом дообучении фреймворк LVLM достигает более 93% F1, значительно лучше справляясь со сложными случаями, такими как сильные водяные знаки, плохой контраст и плотные таблицы, чем традиционный подход. Тщательные эксперименты показывают, что классификатор типа документа и примеры в подсказке особенно важны: их удаление приводит к крупным падениям точности, что подтверждает идею о том, что таргетированные подсказки, зависящие от входа, — ключ к успеху.
Что это значит для повседневной работы с документами
Проще говоря, это исследование показывает, как превратить универсальный ИИ, который «видит и говорит», в надёжного офисного помощника, способного читать многие виды официальных документов при минимальной индивидуальной настройке. Сначала спросив: «Что это за форма?», а затем дав модели короткий настроенный набор примеров и инструкций, систему можно сделать одновременно более точной и проще в развертывании в масштабе. Этот подход может упростить такие задачи, как проверки на соответствие, обзоры тендеров и ввод данных в бэк‑офисе, и указывает на более общий вывод: умное направление больших моделей с помощью подходящего контекста может быть столь же эффективно, как их увеличение в размерах или тренировка с нуля.
Цитирование: Li, H., Chen, G., Xia, J. et al. Visual information extraction from documents via classification-guided large vision-language models. Sci Rep 16, 14158 (2026). https://doi.org/10.1038/s41598-026-49319-z
Ключевые слова: понимание документов, извлечение информации, визуально-языковые модели, офисная автоматизация, инженерия подсказок