Clear Sky Science · zh
SPHTRLM:用于动态环境中机器人路径寻找的安全且隐私保护的超参数调优强化学习方法
能够随行学习的机器人
想象一个需要在不断变化的箱堆中穿行并同时保护客户数据安全的仓储机器人。本文提出了一种新方法,使此类机器人能够在繁忙、变化的空间中学习更优路径,同时保护其在过程中看到的敏感信息。该工作展示了如何将智能学习、安全导航和强隐私保护结合到一个实用的系统中。
移动机器人面临的艰难抉择
在世界中移动的机器人必须不断做出决策:下一步去哪里、避开什么障碍、如何在不发生碰撞的情况下快速到达目标。经典的规划方法在环境几乎不变且事先有地图时表现良好,但在有人、手推车或其他机器人不可预测移动时会遇到困难。现代强化学习让机器人通过试错提升能力,但通常需要大量调优并需开放访问它收集的所有数据。这在实际部署中产生两个大问题:在快速变化的环境中学习可能变得不稳定,而且数据可能暴露有关位置、人员或运营的敏感细节。
一个兼顾安全与隐私的统一系统
作者提出了名为SPHTRLM的框架,同时解决导航质量、学习稳定性和隐私。其设置中,机器人在网格上移动,选择上下左右的简单步法,而障碍物和目标的位置随时间变化。系统通过奖励机器人接近目标、惩罚与障碍物碰撞,并温和地鼓励其探索新路线以避免陷入固有习惯。关键在于,这些奖励并非固定不变,而是根据空间拥挤程度和机器人移动效率进行自适应,这有助于在条件变化时保持有效性。
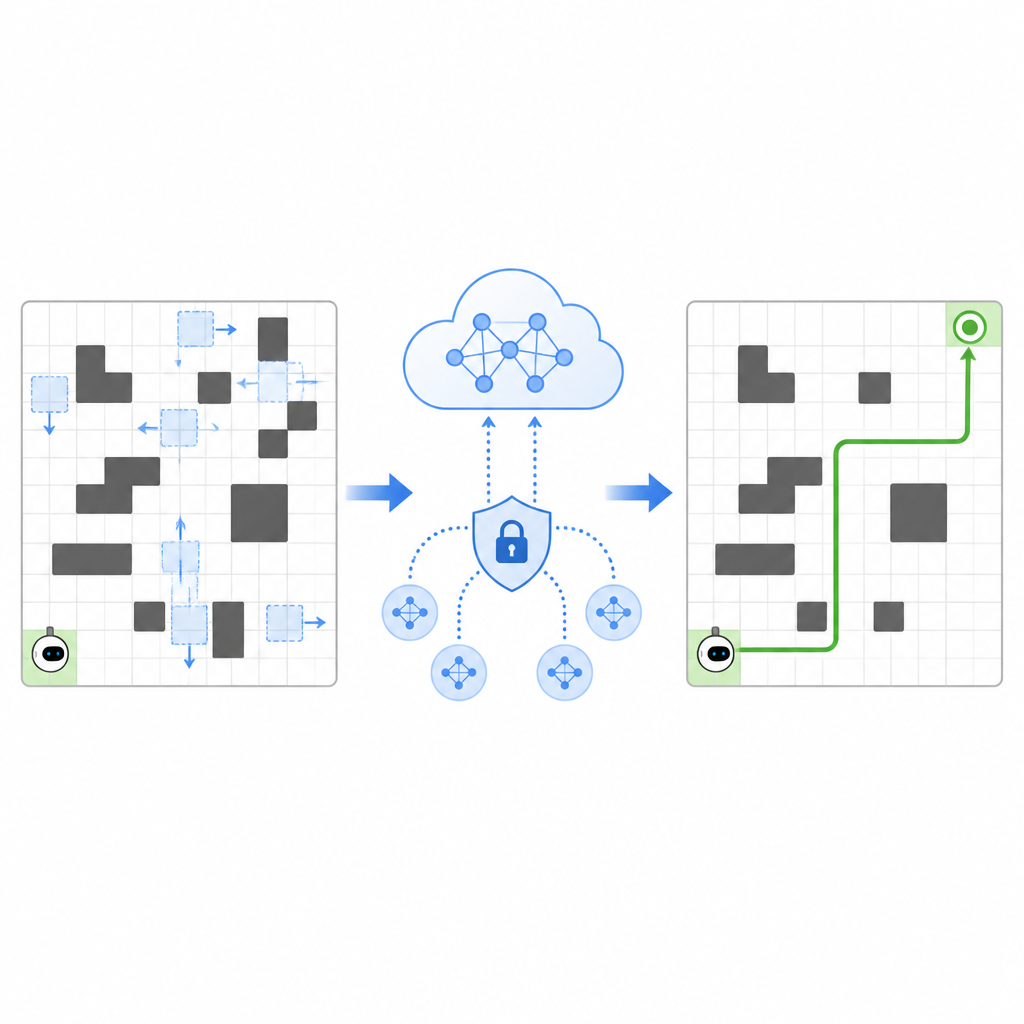
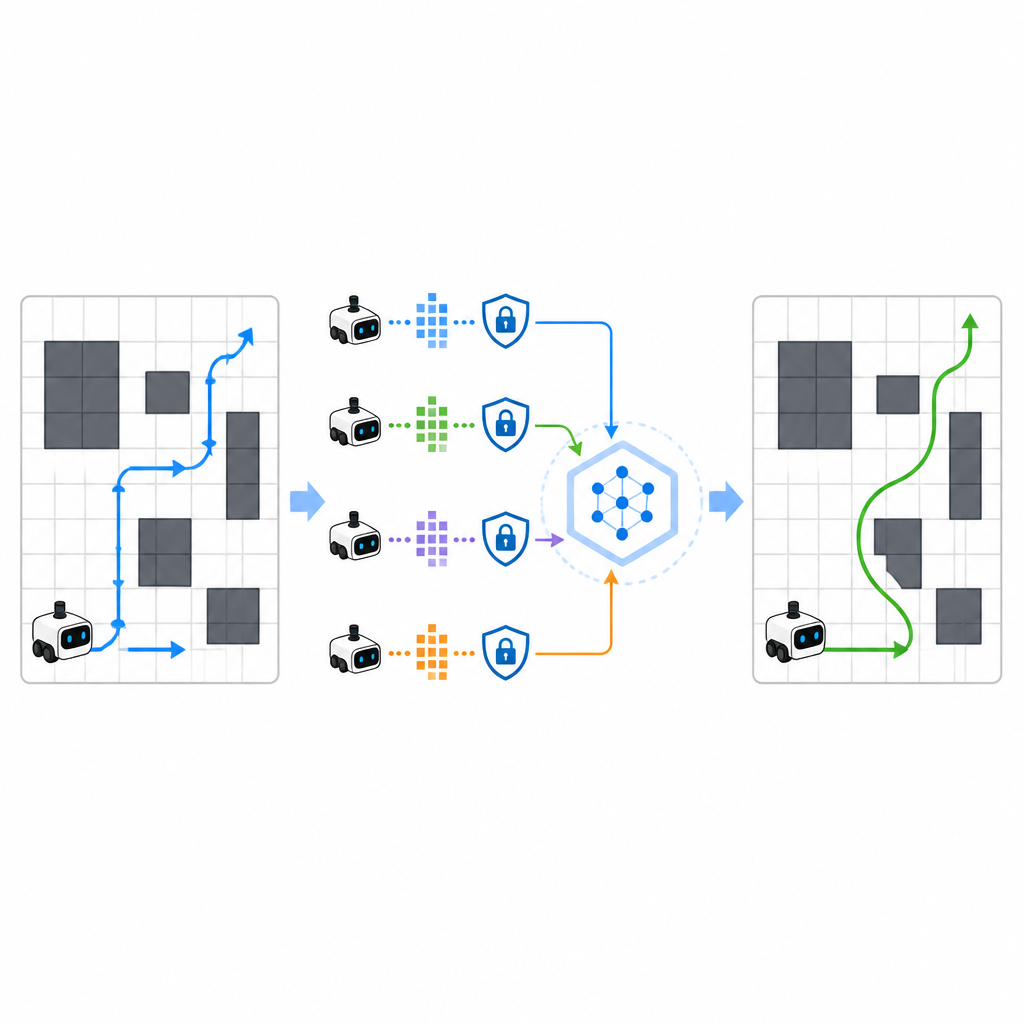
共享经验但不泄露秘密
为加快学习,SPHTRLM允许多个机器人或代理并行学习并共享发现。每个机器人并不将原始地图或详尽路径发送到中央服务器,而是在本地保留经验,并定期发送经过压缩和加密的学习摘要。借鉴联邦学习的技术可以将这些摘要合并成更强的通用策略,然后将改进后的策略发送回机器人。以受控方式添加的额外噪声可隐藏细粒度细节,精心选择的加密确保即便有人截获更新,也无法轻易还原机器人去过的路径或看到的内容。
更快学习、更短路径、更少碰撞
在一个充满移动障碍物的10x10网格的计算实验中,SPHTRLM与几种流行的学习方法进行了比较。它在大约95%的测试运行中成功到达目标,优于标准Q学习和深度强化学习基线。它发现的路径平均缩短了约20%到25%,意味着机器人在游走上浪费的时间更少。它也大约以三分之一更快的速度收敛到良好行为,而且即使在网格高度拥挤时,其碰撞率也降至很低的水平。尽管为保护数据增加了额外步骤,平均决策时间仍保持在几百分之一秒的范围内,适合实时控制。
让攻击者一无所知
研究还评估了该框架在面对试图推断训练期间使用的路径或重构敏感轨迹的攻击者时的表现。通过测试标准隐私攻击,作者发现SPHTRLM使此类攻击的成功率保持在5%以下,接近随机猜测。这种防护来自加密更新、有限的信息共享以及学习信号中的刻意噪声的组合。与此同时,导航性能仍然强劲,表明在不削弱机器人学习能力的前提下可以保护隐私。
对现实世界机器人的意义
对非专业人士而言,关键信息是:现在可以训练机器人在变化的环境中安全高效地移动,同时不暴露其感知和决策的全部内容。SPHTRLM展示了如何将学习、调优和隐私编织到单一设计中,并适配现实的计算限制。这使得隐私感知的仓储机器人、医院服务机器人或敏感设施中的巡检无人机更接近日常应用,它们可以在实时适应的同时尊重所遇到的信息。
引用: Dewangan, R.R., Thombre, D., Parganiha, V. et al. SPHTRLM: secure and privacy-preserving hyperparameter-tuned reinforcement learning method for robot path finding in dynamic environments. Sci Rep 16, 16114 (2026). https://doi.org/10.1038/s41598-026-48141-x
关键词: 机器人导航, 强化学习, 隐私保护人工智能, 联邦学习, 动态环境