Clear Sky Science · pt
SPHTRLM: método de aprendizado por reforço sintonizado por hiperparâmetros com segurança e preservação de privacidade para localização de caminhos robóticos em ambientes dinâmicos
Robôs que Podem Aprender em Movimento
Imagine um robô de depósito que precisa navegar entre pilhas de caixas em constante mudança enquanto protege dados de clientes. Este artigo apresenta uma nova maneira para esses robôs aprenderem melhores trajetos em espaços movimentados e mutáveis, ao mesmo tempo em que protegem informações sensíveis observadas durante o percurso. O trabalho mostra como combinar aprendizado inteligente, navegação segura e forte privacidade em um sistema prático.
Por que Robôs em Movimento Enfrentam Escolhas Difíceis
Robôs que se movem pelo mundo precisam tomar decisões constantemente: para onde ir a seguir, qual obstáculo evitar e como alcançar um objetivo rapidamente sem colidir. Métodos clássicos de planejamento funcionam bem se o ambiente muda pouco e está mapeado com antecedência, mas têm dificuldades quando pessoas, carrinhos ou outros robôs se movem de forma imprevisível. O aprendizado por reforço moderno permite que um robô melhore por tentativa e erro, mas normalmente exige muito ajuste fino e acesso aberto a todos os dados coletados. Isso gera dois grandes problemas em implantações reais: o aprendizado pode ficar instável em cenários de rápida mudança, e os dados podem expor detalhes sensíveis sobre locais, pessoas ou operações.
Um Sistema Unificado para Aprendizado Seguro e Privado
Os autores propõem uma estrutura chamada SPHTRLM que aborda qualidade de navegação, estabilidade do aprendizado e privacidade ao mesmo tempo. Em seu setup, o robô se move sobre uma grade, escolhendo passos simples para cima, baixo, esquerda ou direita enquanto as posições de obstáculos e objetivos mudam ao longo do tempo. O sistema recompensa o robô por se aproximar do objetivo, penaliza por bater em obstáculos e o incentiva levemente a explorar novas rotas em vez de ficar preso a hábitos. Crucialmente, essas recompensas não são fixas, mas se adaptam com base em quão congestionado o espaço está e em quão eficientemente o robô se desloca, o que ajuda a manter a eficácia conforme as condições mudam.
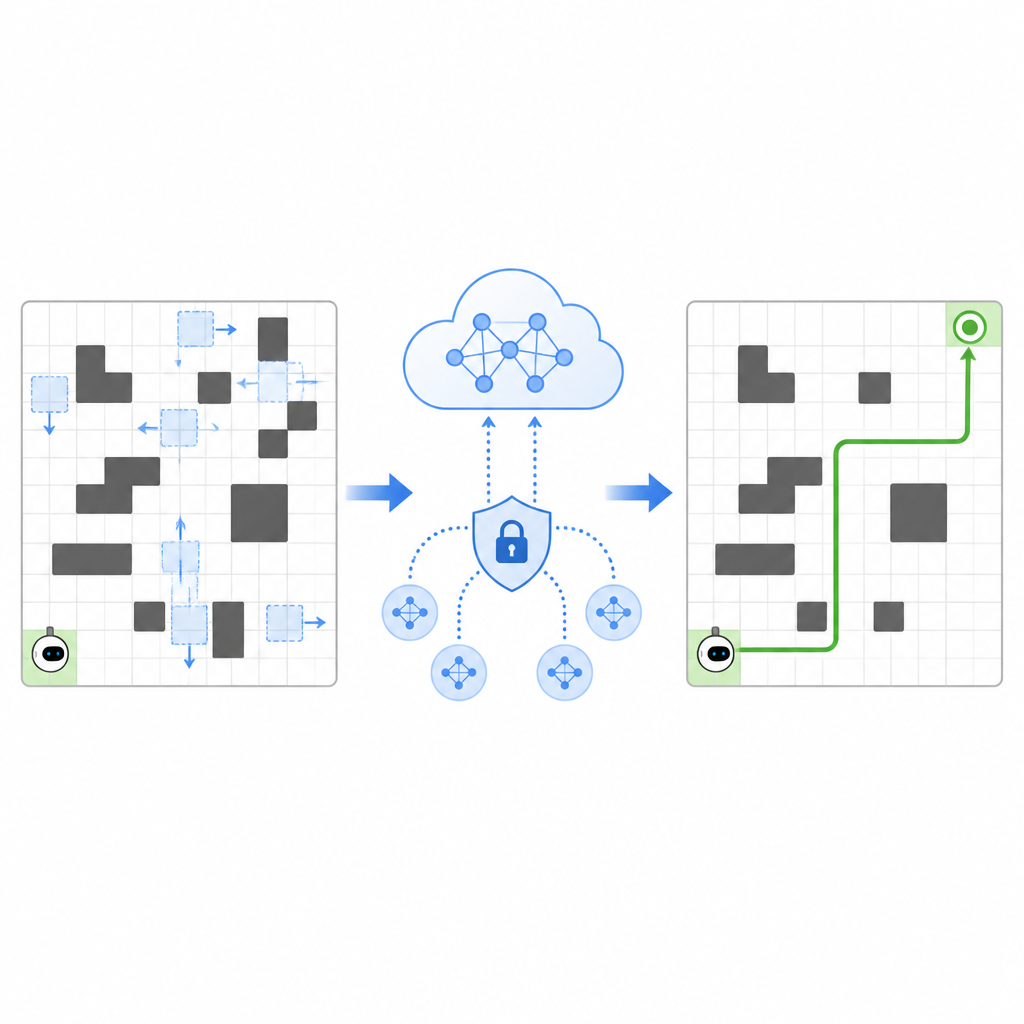
Compartilhando Experiência Sem Divulgar Segredos
Para acelerar o aprendizado, o SPHTRLM permite que vários robôs ou agentes aprendam em paralelo e compartilhem o que descobriram. Em vez de enviar mapas brutos ou trajetórias detalhadas a um servidor central, cada robô mantém sua própria experiência localmente e periodicamente envia resumos compactos e criptografados do que aprendeu. Técnicas emprestadas do aprendizado federado permitem combinar esses resumos em uma estratégia comum mais robusta e então retornar o plano melhorado aos robôs. Ruído extra é adicionado de forma controlada para ocultar detalhes finos, e criptografia cuidadosamente escolhida garante que, mesmo se alguém interceptar as atualizações, não possa reconstruir facilmente por onde os robôs passaram ou o que viram.
Aprendizado Mais Rápido, Rotas Mais Curtas, Menos Colisões
Em experimentos computacionais com uma grade dez por dez cheia de obstáculos móveis, o SPHTRLM foi comparado a vários métodos de aprendizado populares. Ele alcançou seus objetivos em cerca de noventa e cinco por cento das execuções de teste, superando as linhas de base de Q-learning padrão e de aprendizado profundo por reforço. As trajetórias descobertas foram em média cerca de vinte a vinte e cinco por cento mais curtas, o que significa que o robô perdeu menos tempo vagando. Também convergiu para um bom comportamento aproximadamente um terço mais rápido, e sua taxa de colisão caiu para um nível muito baixo mesmo quando a grade estava fortemente congestionada. Apesar das etapas extras necessárias para proteger os dados, o tempo médio de decisão permaneceu na faixa de alguns centésimos de segundo, adequado para controle em tempo real.
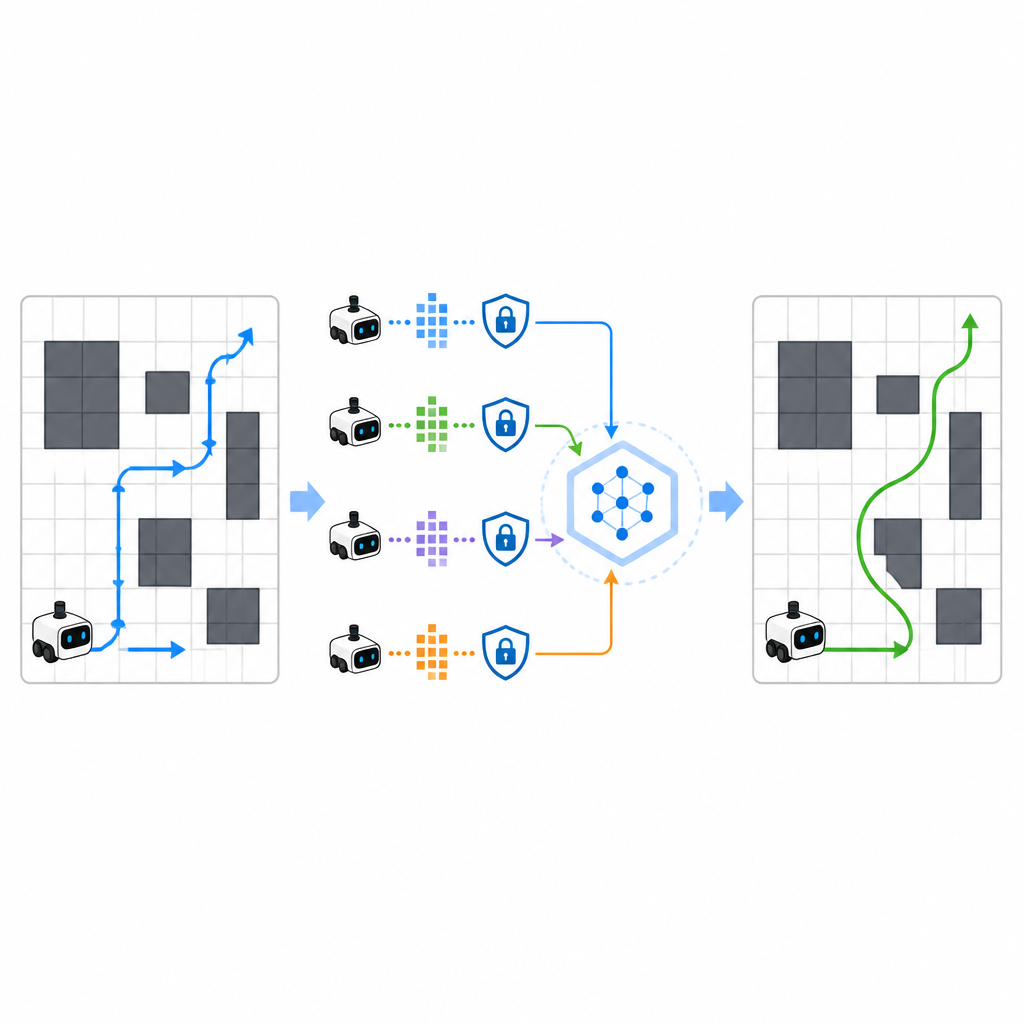
Deixando Invasores no Escuro
O estudo também avaliou quão bem a estrutura resiste a atacantes que tentam inferir quais rotas foram usadas durante o treinamento ou reconstruir trajetórias sensíveis. Testando ataques de privacidade padrão, os autores descobriram que o SPHTRLM manteve a taxa de sucesso desses ataques abaixo de cinco por cento, próxima ao palpite aleatório. Essa proteção veio da combinação de atualizações criptografadas, compartilhamento limitado de informações e ruído deliberado nos sinais de aprendizado. Ao mesmo tempo, o desempenho de navegação permaneceu forte, sugerindo que é possível proteger a privacidade sem prejudicar a capacidade de aprendizado do robô.
O Que Isso Significa para Robôs no Mundo Real
Para não especialistas, a mensagem principal é que agora os robôs podem ser treinados para se mover de forma segura e eficiente em ambientes mutáveis sem expor tudo o que detectam e decidem. O SPHTRLM mostra como entrelaçar aprendizado, ajuste e privacidade em um único projeto que cabe nos limites computacionais realistas. Isso aproxima robôs de depósito conscientes da privacidade, robôs de serviço em hospitais ou drones de inspeção em instalações sensíveis de uma realidade cotidiana, em que podem se adaptar em tempo real sem deixar de respeitar as informações que encontram.
Citação: Dewangan, R.R., Thombre, D., Parganiha, V. et al. SPHTRLM: secure and privacy-preserving hyperparameter-tuned reinforcement learning method for robot path finding in dynamic environments. Sci Rep 16, 16114 (2026). https://doi.org/10.1038/s41598-026-48141-x
Palavras-chave: navegação robótica, aprendizado por reforço, IA que preserva a privacidade, aprendizado federado, ambientes dinâmicos