Clear Sky Science · de
SPHTRLM: sichere und datenschutzwahrende hyperparameter‑optimierte Verstärkungslern‑Methode für die Pfadsuche von Robotern in dynamischen Umgebungen
Roboter, die unterwegs lernen
Stellen Sie sich einen Lagerroboter vor, der sich durch sich verschiebende Stapel von Kartons manövrieren muss und gleichzeitig Kundendaten schützt. Dieses Papier präsentiert eine neue Methode, mit der solche Roboter in belebten, sich ändernden Räumen bessere Wege erlernen können, während sie sensible Informationen, denen sie begegnen, sichern. Die Arbeit zeigt, wie intelligentes Lernen, sichere Navigation und starker Datenschutz zu einem praktischen System kombiniert werden können.
Warum mobile Roboter schwierige Entscheidungen treffen müssen
Roboter, die sich durch die Welt bewegen, müssen ständig Entscheidungen treffen: wohin sie als Nächstes fahren, welches Hindernis sie umfahren und wie sie ein Ziel schnell erreichen, ohne zu kollidieren. Klassische Planungsmethoden funktionieren gut, wenn die Umgebung kaum verändert und vorab kartiert ist, haben aber Probleme, wenn sich Menschen, Wagen oder andere Roboter unvorhersehbar bewegen. Modernes Verstärkungslernen erlaubt dem Roboter, sich durch Versuch und Irrtum zu verbessern, erfordert jedoch meist viel Feinabstimmung und offenen Zugang zu allen gesammelten Daten. Das schafft zwei große Probleme für reale Einsätze: Das Lernen kann in schnell wechselnden Szenarien instabil werden, und die Daten können sensible Details über Orte, Personen oder Abläufe preisgeben.
Ein einheitliches System für sicheres und privates Lernen
Die Autorinnen und Autoren schlagen ein Framework namens SPHTRLM vor, das gleichzeitig die Navigationsqualität, die Stabilität des Lernens und den Datenschutz adressiert. In ihrem Aufbau bewegt sich der Roboter auf einem Raster und wählt einfache Schritte nach oben, unten, links oder rechts, während sich Positionen von Hindernissen und Zielen über die Zeit ändern. Das System belohnt den Roboter, wenn er seinem Ziel näher kommt, bestraft Zusammenstöße mit Hindernissen und ermuntert ihn sanft, neue Routen zu erkunden, statt in Gewohnheiten stecken zu bleiben. Entscheidend ist, dass diese Belohnungen nicht fest sind, sondern sich anpassen, je nachdem wie dicht der Raum bevölkert ist und wie effizient der Roboter sich bewegt, was ihm hilft, bei wechselnden Bedingungen wirksam zu bleiben.
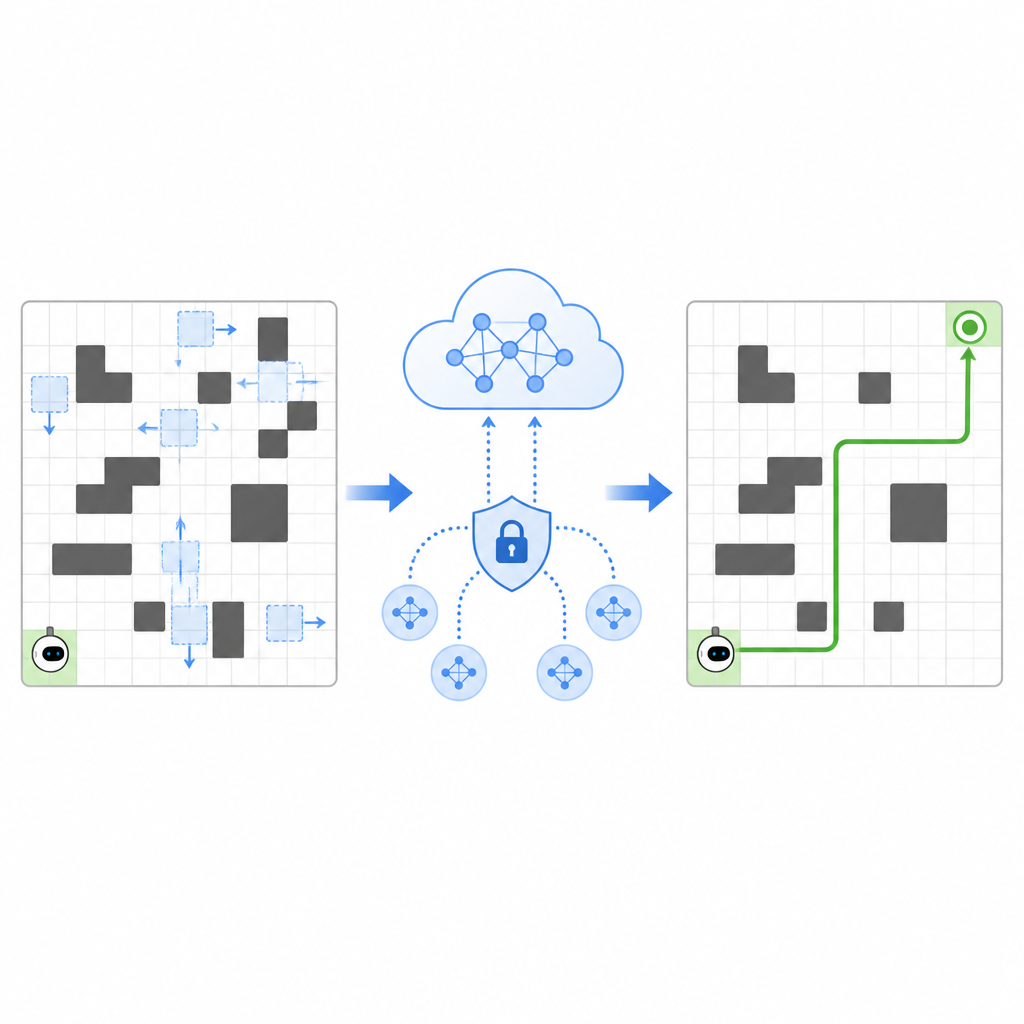
Erfahrungen teilen, ohne Geheimnisse preiszugeben
Um das Lernen zu beschleunigen, erlaubt SPHTRLM mehreren Robotern oder Agenten, parallel zu lernen und ihre Erkenntnisse zu teilen. Anstatt rohe Karten oder detaillierte Pfade an einen zentralen Server zu schicken, behält jeder Roboter seine Erfahrung lokal und sendet periodisch kompakte, verschlüsselte Zusammenfassungen dessen, was er gelernt hat. Techniken aus dem federierten Lernen ermöglichen es, diese Zusammenfassungen zu einem stärkeren gemeinsamen Strategie‑Modell zu kombinieren und den verbesserten Plan an die Roboter zurückzusenden. Kontrolliert hinzugefügtes Rauschen verschleiert feinere Details, und sorgfältig gewählte Verschlüsselung sorgt dafür, dass selbst bei Abfangen der Updates nicht leicht rekonstruiert werden kann, wohin die Roboter gefahren sind oder was sie gesehen haben.
Schnelleres Lernen, kürzere Wege, weniger Kollisionen
In Computersimulationen auf einem zehnmal zehn Feld großen Raster mit sich bewegenden Hindernissen wurde SPHTRLM mit mehreren verbreiteten Lernmethoden verglichen. Es erreichte seine Ziele in etwa 95 Prozent der Testläufe und übertraf damit Standard‑Q‑Learning und Deep‑Reinforcement‑Learning‑Baselines. Die von ihm gefundenen Pfade waren im Durchschnitt etwa 20 bis 25 Prozent kürzer, sodass der Roboter weniger Zeit mit Umherirren verschwendete. Es konvergierte auch ungefähr ein Drittel schneller zu gutem Verhalten, und die Kollisionsrate sank auf ein sehr niedriges Niveau, selbst bei starker Belegung des Rasters. Trotz der zusätzlichen Schritte zum Schutz der Daten blieb die durchschnittliche Entscheidungszeit im Bereich von einigen Hundertstelsekunden, was für Echtzeitsteuerung geeignet ist.
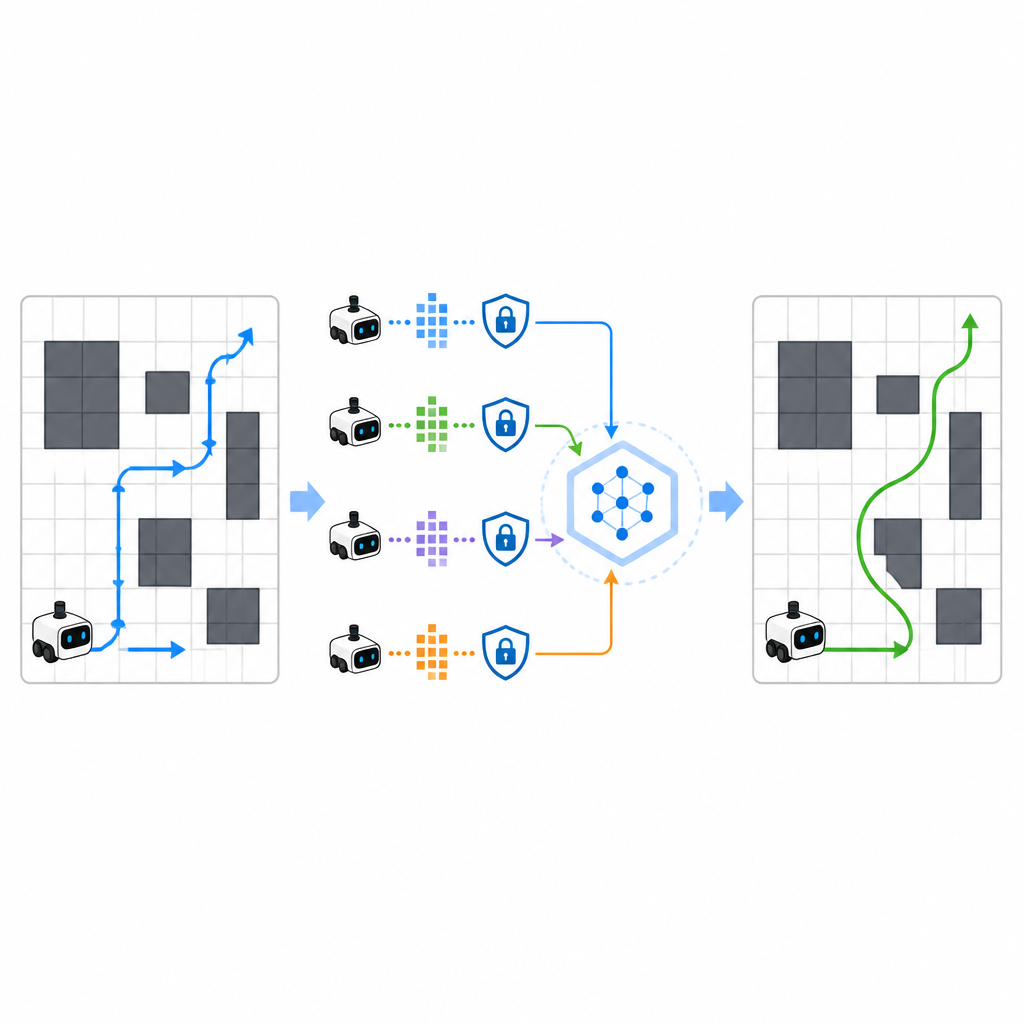
Angreifer im Dunkeln lassen
Die Studie untersuchte außerdem, wie gut das Framework gegen Angreifer standhält, die versuchen, die während des Trainings genutzten Routen zu ermitteln oder sensible Trajektorien zu rekonstruieren. Durch Tests mit standardisierten Privacy‑Angriffen stellten die Autorinnen und Autoren fest, dass SPHTRLM die Erfolgsrate solcher Angriffe unter fünf Prozent hielt, nahe an zufälligem Raten. Dieser Schutz ergab sich aus der Kombination verschlüsselter Updates, begrenzter Informationsweitergabe und gezieltem Rauschen in den Lernsignalen. Gleichzeitig blieb die Navigationsleistung stark, was darauf hindeutet, dass sich Datenschutz schützen lässt, ohne die Lernfähigkeit der Roboter zu lähmen.
Was das für reale Roboter bedeutet
Für Nicht‑Spezialistinnen und Nicht‑Spezialisten ist die Kernbotschaft: Roboter können jetzt so trainiert werden, dass sie sich in sich verändernden Umgebungen sicher und effizient bewegen, ohne alles, was sie wahrnehmen und entscheiden, offenzulegen. SPHTRLM zeigt, wie Lernen, Abstimmung und Datenschutz in ein einziges Design verwoben werden können, das innerhalb realistischer Rechenressourcen funktioniert. Das rückt datenschutzbewusste Lagerroboter, Serviceroboter in Krankenhäusern oder Inspektionsdrohnen in sensiblen Einrichtungen einen Schritt näher an den Alltag, wo sie sich spontan anpassen können und gleichzeitig die Informationen respektieren, denen sie begegnen.
Zitation: Dewangan, R.R., Thombre, D., Parganiha, V. et al. SPHTRLM: secure and privacy-preserving hyperparameter-tuned reinforcement learning method for robot path finding in dynamic environments. Sci Rep 16, 16114 (2026). https://doi.org/10.1038/s41598-026-48141-x
Schlüsselwörter: Roboter‑Navigation, Verstärkungslernen, datenschutzfreundliche KI, federiertes Lernen, dynamische Umgebungen