Clear Sky Science · es
SPHTRLM: método de aprendizaje por refuerzo con ajuste de hiperparámetros, seguro y que preserva la privacidad para la búsqueda de rutas de robots en entornos dinámicos
Robots que pueden aprender en movimiento
Imagine un robot de almacén que debe sortear pilas de cajas que cambian constantemente mientras protege los datos de los clientes. Este artículo presenta una nueva forma para que esos robots aprendan mejores trayectorias en espacios concurridos y cambiantes a la vez que resguardan la información sensible que encuentran. El trabajo muestra cómo combinar aprendizaje inteligente, navegación segura y fuerte privacidad en un sistema práctico.
Por qué los robots móviles afrontan decisiones difíciles
Los robots que se desplazan por el mundo deben tomar decisiones continuamente: a dónde ir, qué obstáculo evitar y cómo alcanzar un objetivo rápidamente sin chocar. Los métodos de planificación clásicos funcionan bien si el entorno apenas cambia y está mapeado de antemano, pero fallan cuando personas, carros u otros robots se mueven de forma impredecible. El aprendizaje por refuerzo moderno permite que un robot mejore mediante prueba y error, pero normalmente exige mucho ajuste fino y acceso abierto a todos los datos recopilados. Eso crea dos problemas importantes para implementaciones reales: el aprendizaje puede volverse inestable en escenarios de cambio rápido, y los datos pueden exponer detalles sensibles sobre ubicaciones, personas u operaciones.
Un sistema unificado para aprendizaje seguro y privado
Los autores proponen un marco llamado SPHTRLM que aborda la calidad de la navegación, la estabilidad del aprendizaje y la privacidad al mismo tiempo. En su configuración, el robot se mueve en una cuadrícula, eligiendo pasos simples hacia arriba, abajo, izquierda o derecha mientras las posiciones de obstáculos y objetivos cambian con el tiempo. El sistema recompensa al robot por acercarse a su meta, lo penaliza por chocar con obstáculos y lo incentiva suavemente a explorar rutas nuevas en lugar de quedar atrapado en hábitos. Crucialmente, estas recompensas no son fijas sino que se adaptan según lo concurrido del espacio y la eficiencia del robot, lo que le ayuda a seguir siendo efectivo conforme cambian las condiciones.
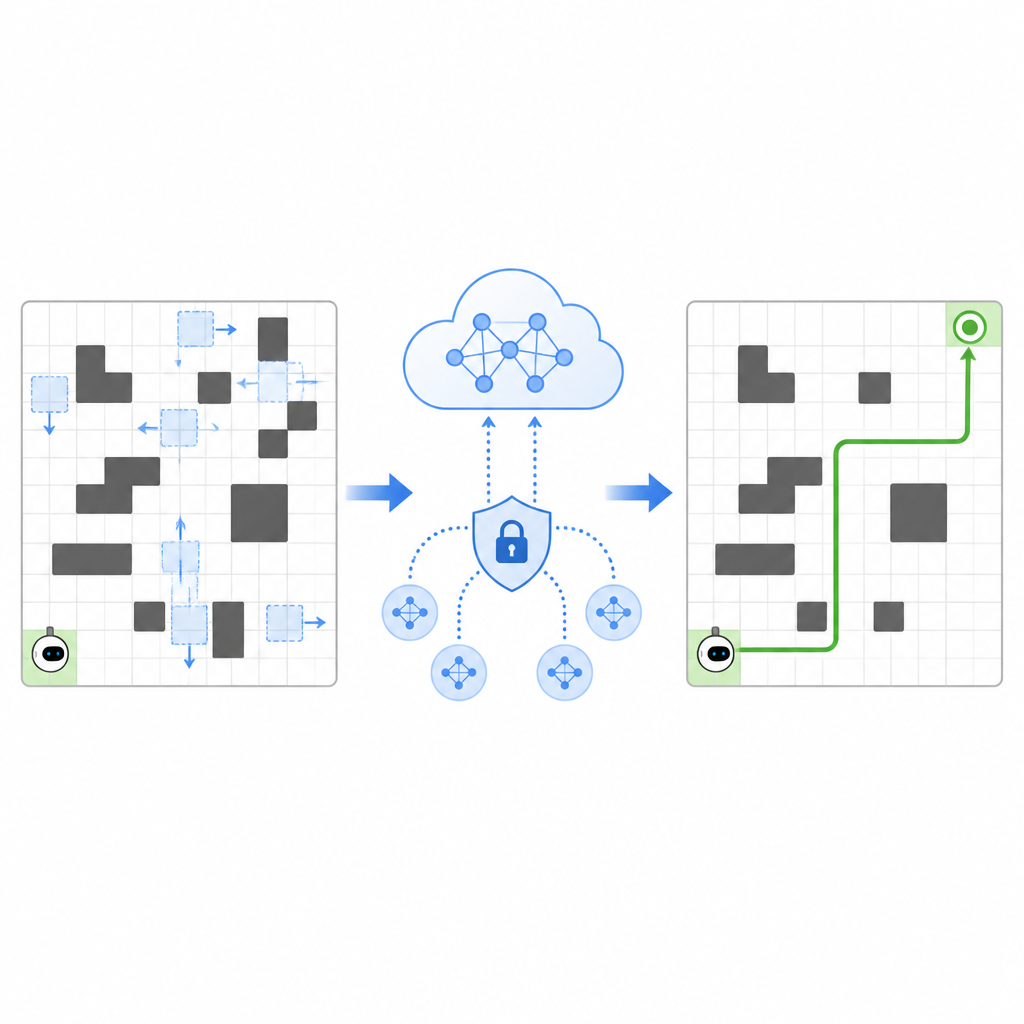
Compartir experiencia sin revelar secretos
Para acelerar el aprendizaje, SPHTRLM permite que varios robots o agentes aprendan en paralelo y compartan lo que han descubierto. En lugar de enviar mapas en crudo o trayectorias detalladas a un servidor central, cada robot mantiene su experiencia localmente y periódicamente envía resúmenes compactos y cifrados de lo aprendido. Técnicas tomadas del aprendizaje federado permiten combinar esos resúmenes en una estrategia común más robusta y luego enviar el plan mejorado de vuelta a los robots. Se añade ruido adicional de forma controlada para ocultar detalles finos, y un cifrado cuidadosamente elegido asegura que, incluso si alguien intercepta las actualizaciones, no pueda reconstruir fácilmente por dónde fueron los robots ni qué vieron.
Aprendizaje más rápido, rutas más cortas, menos choques
En experimentos por ordenador con una cuadrícula de diez por diez llena de obstáculos en movimiento, SPHTRLM se comparó con varios métodos de aprendizaje populares. Alcanzó sus objetivos en aproximadamente el noventa y cinco por ciento de las pruebas, superando las líneas base de Q learning estándar y de aprendizaje por refuerzo profundo. Las rutas que descubrió fueron entre un veinte y un veinticinco por ciento más cortas en promedio, lo que significa que el robot desperdiciaba menos tiempo deambulando. También convergió hacia un buen comportamiento aproximadamente un tercio más rápido, y su tasa de colisiones descendió a un nivel muy bajo incluso cuando la cuadrícula estaba fuertemente congestionada. A pesar de los pasos adicionales necesarios para proteger los datos, el tiempo medio de decisión se mantuvo en el rango de unas pocas centésimas de segundo, adecuado para control en tiempo real.
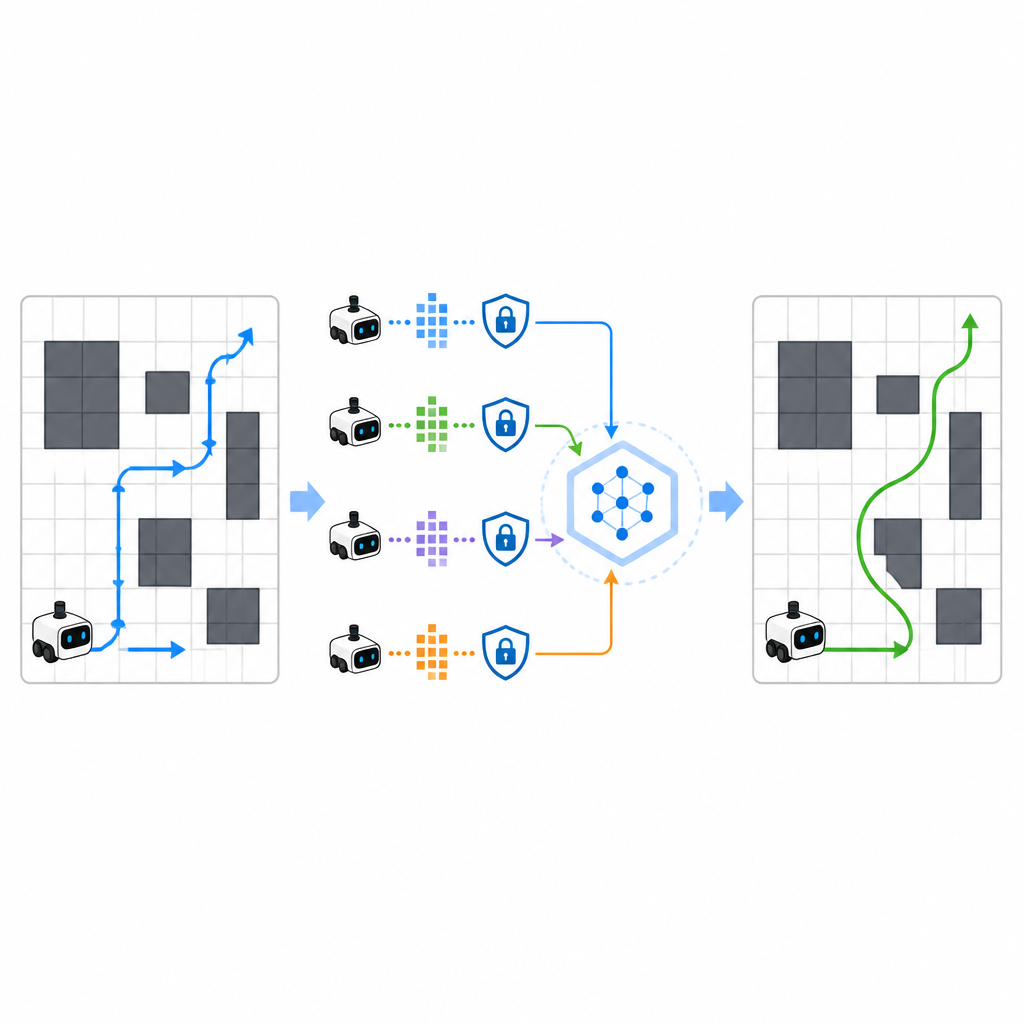
Manteniendo a los atacantes en la oscuridad
El estudio también evaluó cómo resiste el marco a atacantes que intentan inferir qué rutas se usaron durante el entrenamiento o reconstruir trayectorias sensibles. Al probar ataques de privacidad estándar, los autores encontraron que SPHTRLM mantuvo la tasa de éxito de esos ataques por debajo del cinco por ciento, cercana a una conjetura aleatoria. Esa protección provino de la combinación de actualizaciones cifradas, intercambio limitado de información y ruido deliberado en las señales de aprendizaje. Al mismo tiempo, el rendimiento de navegación se mantuvo sólido, lo que sugiere que es posible proteger la privacidad sin paralizar la capacidad del robot para aprender.
Qué significa esto para robots en el mundo real
Para quienes no son especialistas, el mensaje clave es que ahora los robots pueden entrenarse para moverse de forma segura y eficiente en entornos cambiantes sin exponer todo lo que perciben y deciden. SPHTRLM muestra cómo entrelazar aprendizaje, ajuste y privacidad en un único diseño que encaja dentro de límites informáticos realistas. Esto acerca un paso más la realidad cotidiana de robots de almacén con conciencia de la privacidad, robots de servicio en hospitales o drones de inspección en instalaciones sensibles, que pueden adaptarse sobre la marcha respetando la información que encuentran.
Cita: Dewangan, R.R., Thombre, D., Parganiha, V. et al. SPHTRLM: secure and privacy-preserving hyperparameter-tuned reinforcement learning method for robot path finding in dynamic environments. Sci Rep 16, 16114 (2026). https://doi.org/10.1038/s41598-026-48141-x
Palabras clave: navegación de robots, aprendizaje por refuerzo, IA que preserva la privacidad, aprendizaje federado, entornos dinámicos