Clear Sky Science · en
SPHTRLM: secure and privacy-preserving hyperparameter-tuned reinforcement learning method for robot path finding in dynamic environments
Robots That Can Learn on the Move
Imagine a warehouse robot that must weave through shifting stacks of boxes while keeping customer data safe. This paper presents a new way for such robots to learn better paths in busy, changing spaces while also guarding the sensitive information they see along the way. The work shows how to combine smart learning, safe navigation, and strong privacy into one practical system.
Why Moving Robots Face Tough Choices
Robots that move through the world must constantly make decisions: where to go next, which obstacle to avoid, and how to reach a goal quickly without crashing. Classic planning methods work well if the environment barely changes and is mapped in advance, but struggle when people, carts, or other robots move around unpredictably. Modern reinforcement learning lets a robot improve by trial and error, but normally demands lots of fine tuning and open access to all the data it collects. That creates two big problems for real deployments: the learning can become unstable in fast changing settings, and the data can expose sensitive details about locations, people, or operations.
A Unified System for Safe and Private Learning
The authors propose a framework called SPHTRLM that tackles navigation quality, learning stability, and privacy at the same time. In their setup, the robot moves on a grid, choosing simple steps up, down, left, or right while the positions of obstacles and goals change over time. The system rewards the robot for getting closer to its goal, penalizes it for bumping into obstacles, and gently encourages it to explore new routes instead of getting stuck in habits. Crucially, these rewards are not fixed but adapt based on how crowded the space is and how efficiently the robot is moving, which helps it stay effective as conditions shift.
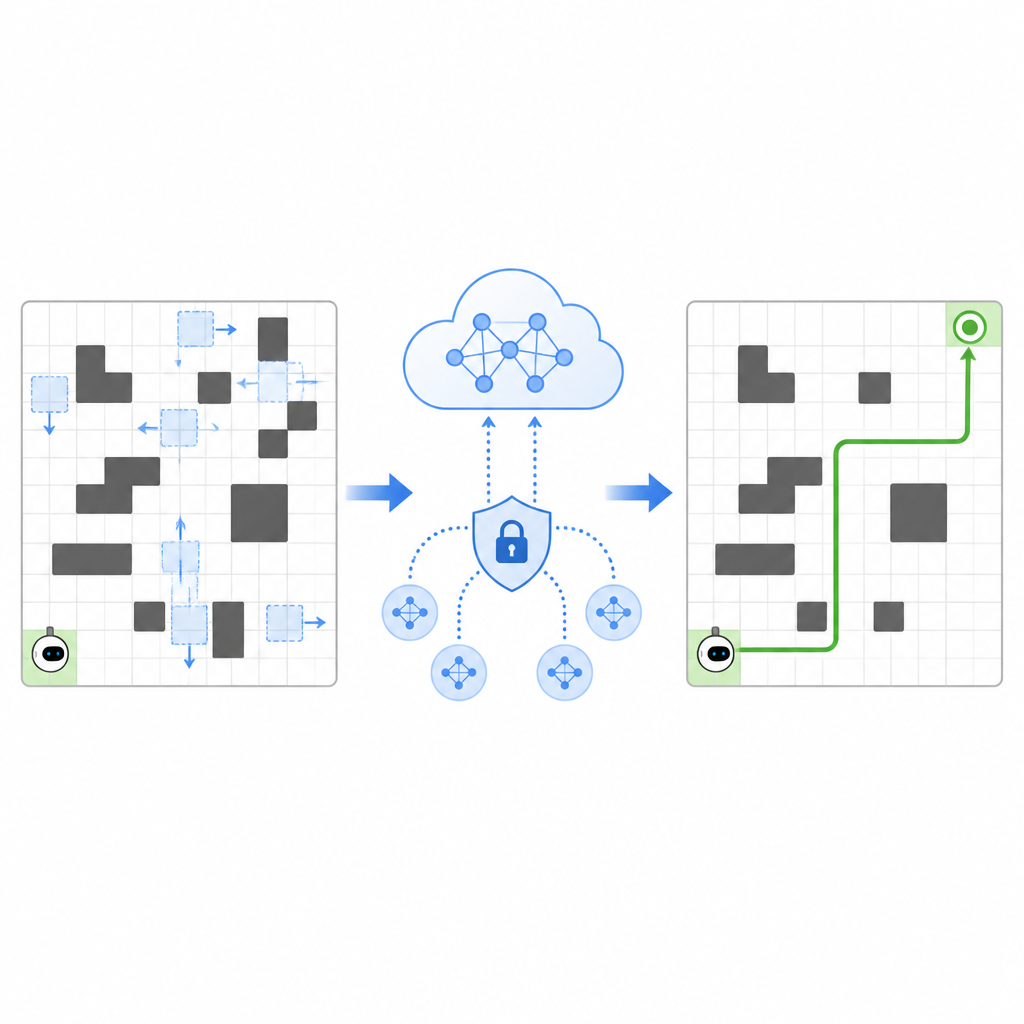
Sharing Experience Without Sharing Secrets
To speed up learning, SPHTRLM allows several robots or agents to learn in parallel and share what they have discovered. Instead of shipping raw maps or detailed paths to a central server, each robot keeps its own experience locally and periodically sends compact, encrypted summaries of what it has learned. Techniques borrowed from federated learning make it possible to combine these summaries into a stronger common strategy, then send the improved plan back to the robots. Extra noise is added in a controlled way to hide fine grained details, and carefully chosen encryption ensures that even if someone intercepts the updates, they cannot easily reconstruct where the robots went or what they saw.
Faster Learning, Shorter Paths, Fewer Crashes
In computer experiments with a ten by ten grid full of moving obstacles, SPHTRLM was compared to several popular learning methods. It reached its goals in about ninety five percent of test runs, beating standard Q learning and deep reinforcement learning baselines. The paths it discovered were about twenty to twenty five percent shorter on average, meaning the robot wasted less time wandering. It also converged on good behavior roughly one third faster, and its collision rate dropped to a very low level even when the grid was heavily cluttered. Despite the extra steps needed to protect data, the average decision time stayed in the range of a few hundredths of a second, which is suitable for real time control.
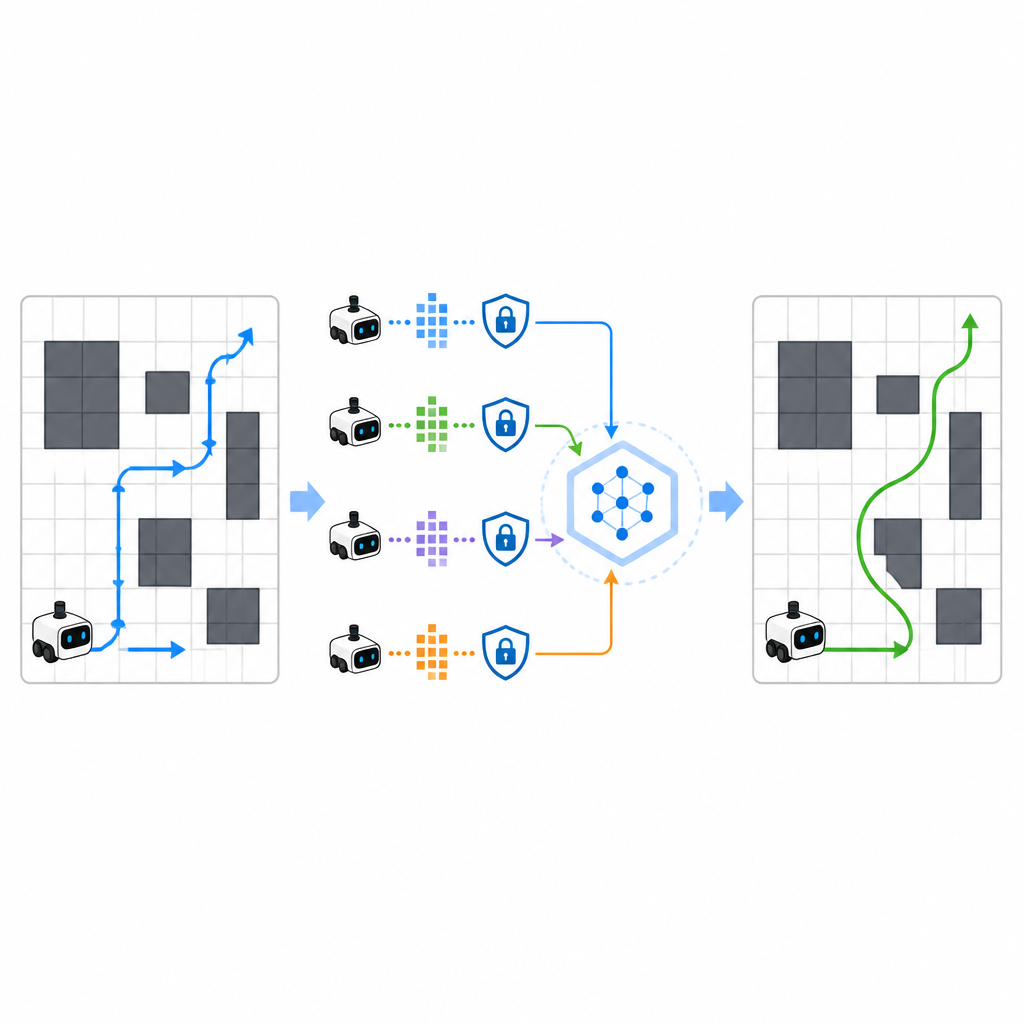
Keeping Attackers in the Dark
The study also asked how well the framework stands up to attackers who try to infer which routes were used during training or to reconstruct sensitive trajectories. By testing standard privacy attacks, the authors found that SPHTRLM kept the success rate of such attacks below five percent, close to random guessing. That protection came from the combination of encrypted updates, limited sharing of information, and deliberate noise in the learning signals. At the same time, the navigation performance remained strong, suggesting that it is possible to protect privacy without crippling the robot’s ability to learn.
What This Means for Real World Robots
For non specialists, the key message is that robots can now be trained to move safely and efficiently in changing environments without exposing everything they sense and decide. SPHTRLM shows how to weave together learning, tuning, and privacy into a single design that fits within realistic computing limits. This brings privacy aware warehouse robots, service robots in hospitals, or inspection drones in sensitive facilities a step closer to everyday reality, where they can adapt on the fly while still respecting the information they encounter.
Citation: Dewangan, R.R., Thombre, D., Parganiha, V. et al. SPHTRLM: secure and privacy-preserving hyperparameter-tuned reinforcement learning method for robot path finding in dynamic environments. Sci Rep 16, 16114 (2026). https://doi.org/10.1038/s41598-026-48141-x
Keywords: robot navigation, reinforcement learning, privacy preserving AI, federated learning, dynamic environments