Clear Sky Science · nl
SPHTRLM: veilige en privacybeschermende hyperparameter-afgestemde reinforcement learning-methode voor robotpadplanning in dynamische omgevingen
Robots die onderweg kunnen leren
Stel je een magazijnrobot voor die zich een weg moet banen tussen verschuivende stapels dozen terwijl hij klantgegevens veilig houdt. Dit artikel presenteert een nieuwe manier waarop zulke robots betere paden kunnen leren in drukke, veranderende ruimtes terwijl ze ook de gevoelige informatie die ze onderweg zien beschermen. Het werk laat zien hoe je slim leren, veilige navigatie en sterke privacy in één praktische system integreert.
Waarom bewegende robots moeilijke keuzes hebben
Robots die zich door de wereld bewegen moeten voortdurend beslissingen nemen: waar ze hierna heen gaan, welk obstakel ze moeten vermijden en hoe ze snel een doel bereiken zonder te botsen. Klassieke planningsmethoden werken goed als de omgeving nauwelijks verandert en van tevoren in kaart is gebracht, maar hebben moeite wanneer mensen, karren of andere robots zich onvoorspelbaar verplaatsen. Moderne reinforcement learning laat een robot door proef en fout verbeteren, maar vereist doorgaans veel afstemming en open toegang tot alle verzamelde gegevens. Dat creëert twee grote problemen voor echte toepassingen: het leerproces kan onstabiel worden in snel veranderende situaties en de gegevens kunnen gevoelige details over locaties, mensen of operaties blootleggen.
Een geïntegreerd systeem voor veilig en privé leren
De auteurs stellen een raamwerk voor genaamd SPHTRLM dat tegelijk de kwaliteit van navigatie, leerstabiliteit en privacy aanpakt. In hun opzet beweegt de robot zich op een raster en kiest eenvoudige stappen omhoog, omlaag, links of rechts terwijl de posities van obstakels en doelen in de loop van de tijd veranderen. Het systeem beloont de robot voor het dichterbij komen van zijn doel, straft hem voor botsingen met obstakels en moedigt hem subtiel aan nieuwe routes te verkennen in plaats van vastgeroeste gewoonten te ontwikkelen. Cruciaal is dat deze beloningen niet vaststaan maar zich aanpassen op basis van hoe druk de ruimte is en hoe efficiënt de robot zich beweegt, wat helpt effectief te blijven naarmate de omstandigheden verschuiven.
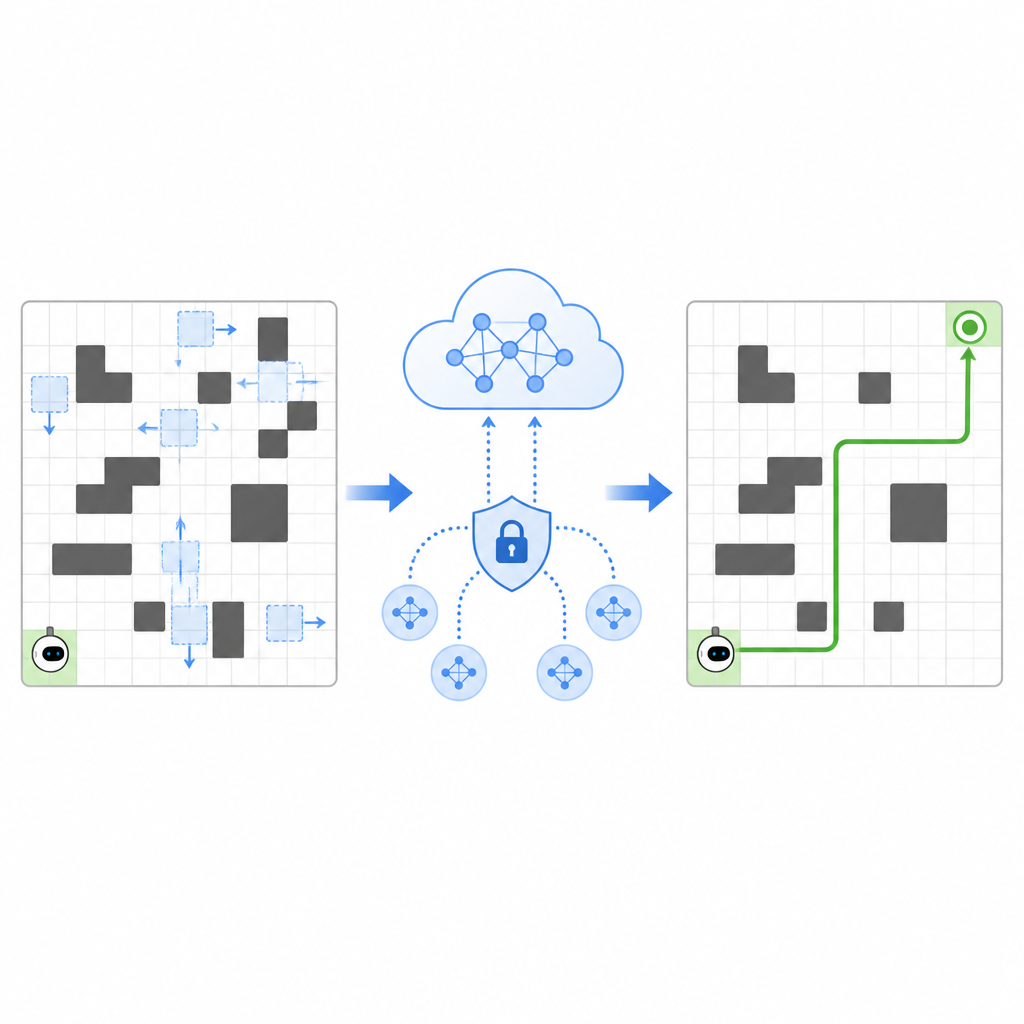
Ervaring delen zonder geheimen prijs te geven
Om het leren te versnellen laat SPHTRLM meerdere robots of agenten parallel leren en delen wat ze hebben ontdekt. In plaats van ruwe kaarten of gedetailleerde paden naar een centrale server te sturen, bewaart elke robot zijn eigen ervaring lokaal en stuurt periodiek compacte, versleutelde samenvattingen van wat hij geleerd heeft. Technieken uit het gefedereerd leren maken het mogelijk deze samenvattingen te combineren tot een sterkere gemeenschappelijke strategie, die vervolgens terug naar de robots wordt gestuurd. Extra ruis wordt op gecontroleerde wijze toegevoegd om fijnmazige details te verbergen, en zorgvuldig gekozen versleuteling zorgt ervoor dat zelfs als iemand de updates onderschept, diegene niet gemakkelijk kan reconstrueren waar de robots zijn geweest of wat ze hebben gezien.
Sneller leren, kortere paden, minder botsingen
In computerexperimenten met een tien bij tien raster vol bewegende obstakels werd SPHTRLM vergeleken met verschillende gangbare leermethoden. Het bereikte zijn doelen in ongeveer vijfennegentig procent van de testruns en versloeg daarmee standaard Q-learning en deep reinforcement learning-baselines. De paden die het ontdekte waren gemiddeld ongeveer twintig tot vijfentwintig procent korter, wat betekent dat de robot minder tijd verloor met rondzwerven. Het convergeerde ook ongeveer een derde sneller naar goed gedrag en het botsingspercentage daalde naar een zeer laag niveau, zelfs wanneer het raster zwaar gevuld was. Ondanks de extra stappen die nodig zijn om gegevens te beschermen, bleef de gemiddelde besluitvormingstijd in het bereik van enkele honderdsten van een seconde, wat geschikt is voor realtimebesturing.
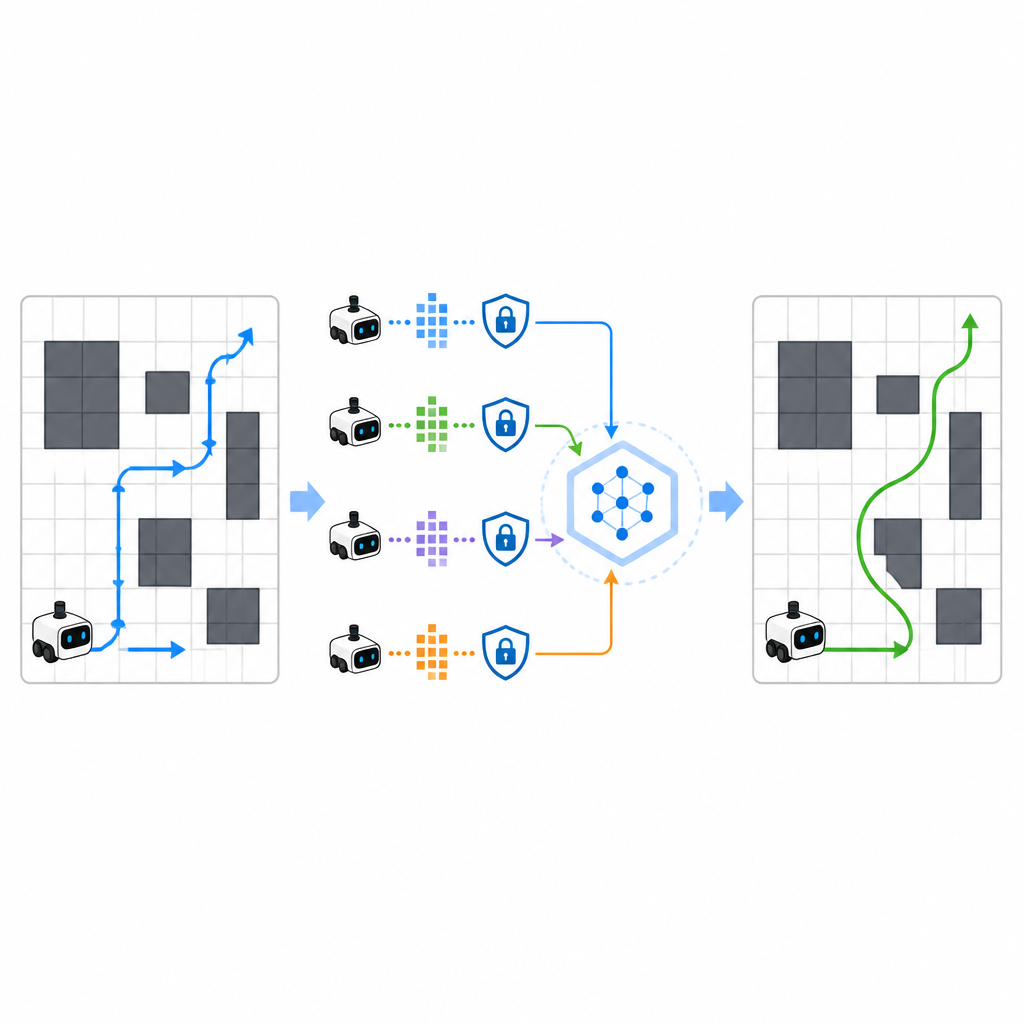
Aanvallers in het ongewisse houden
De studie onderzocht ook hoe goed het raamwerk standhoudt tegen aanvallers die proberen af te leiden welke routes tijdens het trainen zijn gebruikt of die gevoelige trajecten willen reconstrueren. Door gangbare privacy-aanvallen te testen, vonden de auteurs dat SPHTRLM het succespercentage van dergelijke aanvallen onder de vijf procent hield, dicht bij willekeurig raden. Die bescherming kwam van de combinatie van versleutelde updates, beperkte informatie-uitwisseling en doelbewuste ruis in de leersignalen. Tegelijk bleef de navigatieprestaties sterk, wat suggereert dat het mogelijk is privacy te beschermen zonder het leervermogen van de robot te belemmeren.
Wat dit betekent voor robots in de echte wereld
Voor niet-specialisten is de kernboodschap dat robots nu kunnen worden getraind om veilig en efficiënt te bewegen in veranderende omgevingen zonder alles wat ze waarnemen en beslissen bloot te geven. SPHTRLM toont hoe leren, afstemming en privacy in één ontwerp kunnen worden verweven dat binnen realistische rekenlimieten past. Dit brengt privacybewuste magazijnrobots, servicerobots in ziekenhuizen of inspectiedrones in gevoelige faciliteiten een stap dichter bij de dagelijkse praktijk, waar ze zich ter plekke kunnen aanpassen en toch respect tonen voor de informatie die ze tegenkomen.
Bronvermelding: Dewangan, R.R., Thombre, D., Parganiha, V. et al. SPHTRLM: secure and privacy-preserving hyperparameter-tuned reinforcement learning method for robot path finding in dynamic environments. Sci Rep 16, 16114 (2026). https://doi.org/10.1038/s41598-026-48141-x
Trefwoorden: robotnavigatie, reinforcement learning, privacybeschermende AI, gefedereerd leren, dynamische omgevingen