Clear Sky Science · he
SPHTRLM: שיטת חיזוק מכוּנָה לפרמטרים המאבטחת ושומרת על פרטיות למציאת מסלולים לרובוטים בסביבות דינמיות
רובוטים שיכולים ללמוד בתנועה
דמיינו רובוט מחסן שצריך להתלבט בין ערימות קופסאות משתנות תוך שמירה על נתוני לקוחות חסויים. מאמר זה מציג דרך חדשה לרובוטים כאלה ללמוד מסלולים טובים יותר במרחבים עמוסים ומשתנים, ובו־זמנית להגן על המידע הרגיש שהם נתקלים בו. העבודה מראה כיצד לשלב למידה מתוחכמת, ניווט בטוח ופרטיות חזקה במערכת מעשית אחת.
מדוע רובוטים ניידים ניצבים בפני בחירות קשות
רובוטים שנעים בעולם צריכים באופן מתמיד לקבל החלטות: לאן ללכת עכשיו, איזה מכשול להימנע ממנו ואיך להגיע ליעד במהירות בלי להיתקל. שיטות תכנון קלאסיות עובדות היטב אם הסביבה משתנה מעט וממופה מראש, אך מתקשות כאשר אנשים, עגלות או רובוטים אחרים נעים באופן בלתי צפוי. למידת חיזוק מודרנית מאפשרת לרובוט להשתפר בניסיון וטעייה, אך בדרך כלל דורשת הרבה כוונון מדוקדק וגישה פתוחה לכל הנתונים שנאספו. זה יוצר שתי בעיות עיקריות לפריסה במציאות: הלמידה עלולה להפוך לבלתי יציבה בסביבות משתנות במהירות, והנתונים עלולים לחשוף פרטים רגישים על מקומות, אנשים או תהליכים.
מערכת מאוחדת ללמידה בטוחה ופרטית
המחברים מציעים מסגרת בשם SPHTRLM שמתמודדת בבת אחת עם איכות הניווט, יציבות הלמידה והפרטיות. בסביבתם, הרובוט נע על רשת מרובעת, בוחר צעדים פשוטים למעלה, למטה, שמאלה או ימינה בעוד מיקומי המכשולים והיעדים משתנים עם הזמן. המערכת מעניקה תגמול על התקרבות ליעד, מענישה על התנגשות במכשולים ומעודדת בעדינות חקירה של מסלולים חדשים במקום להישאר בנהלים קבועים. באופן מהותי, התגמולים אינם קבועים אלא מתאימים עצמם בהתאם לעומס במקום וליעילות התנועה של הרובוט, מה שעוזר לו להישאר יעיל ככל שהתנאים משתנים.
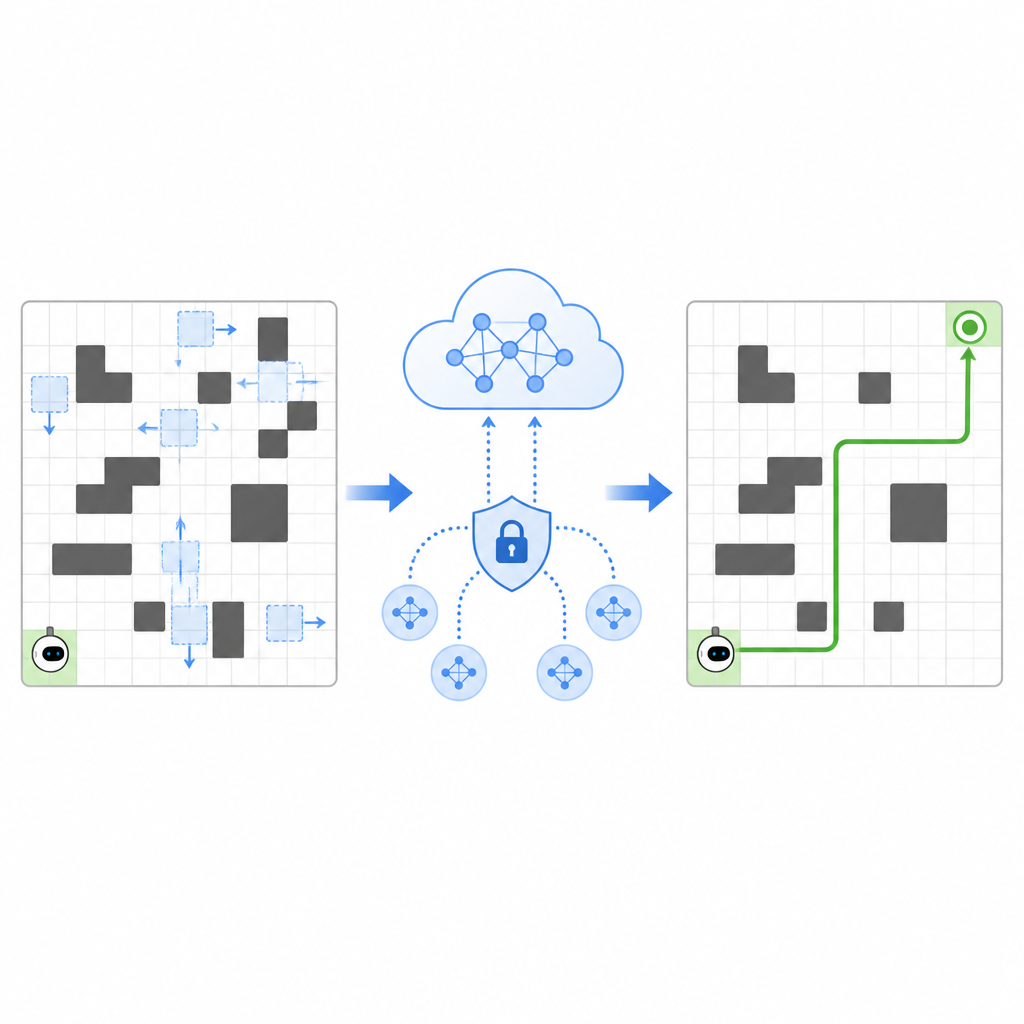
לשתף ניסיון בלי לשתף סודות
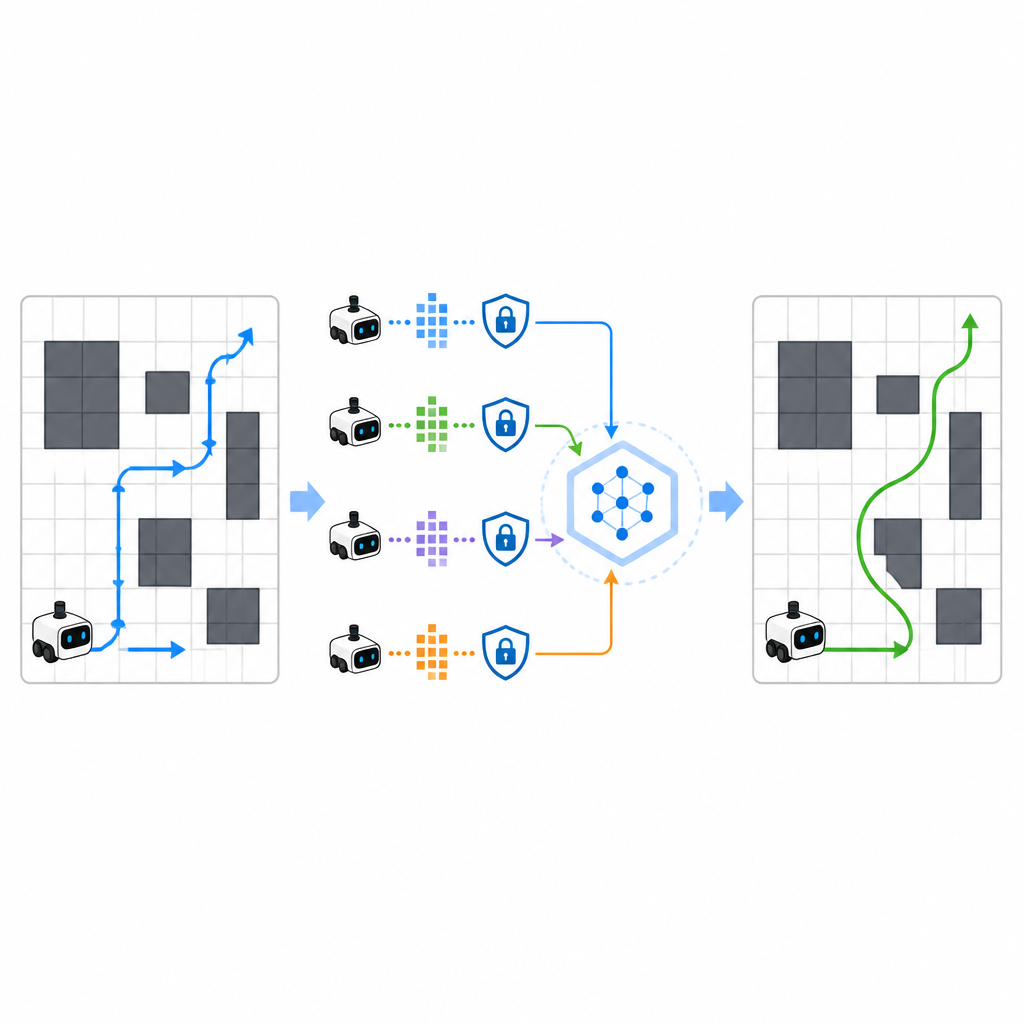
כדי להאיץ את הלמידה, SPHTRLM מאפשרת למספר רובוטים או סוכנים ללמוד במקביל ולשתף את ממצאיהם. במקום לשלוח מפות גולמיות או מסלולים מפורטים לשרת מרכזי, כל רובוט שומר את ניסיונו באופן מקומי ושולח периодית סיכומים דחוסים ומוצפנים של מה שלמד. טכניקות שנלקחו מלמידה פדרטיבית מאפשרות לשלב סיכומים אלה לאסטרטגיה משותפת חזקה יותר, ואז לשלוח את התוכנית המשופרת חזרה לרובוטים. נוסף לכך, מתווספת רעש מבוקר כדי להסתיר פרטים עדינים, והצפנה נבחרת בקפידה מבטיחה שגם אם מישהו יירט את העדכונים, לא יוכל בקלות לשחזר לאן הרובוטים הלכו או מה ראו.
למידה מהירה יותר, מסלולים קצרים יותר, פחות התנגשות
בניסויים ממוחשבים על רשת בגודל עשר על עשר מלאה במכשולים נעים, השוו את SPHTRLM למספר שיטות למידה נפוצות. המערכת הגיעה ליעדיה בכ-95% מריצות המבחן, והתגברה על שיטות Q learning סטנדרטיות ובסיסי למידת חיזוק עמוקה. המסלולים שגילתה היו קצרים בכ-20–25% בממוצע, כלומר הרובוט בזבז פחות זמן בתנועה סיבובית. היא גם התכנס́ה להתנהגות טובה בערך שליש מהר יותר, ושיעור ההתנגשויות ירד לרמה נמוכה מאוד גם כאשר הרשת הייתה צפופה מאוד. למרות הצעדים הנוספים להגנת נתונים, זמן ההחלטה הממוצע נשאר בטווח של כמה מאיות השנייה, מה שמתאים לבקרה בזמן אמת.
להשאיר את התוקפים בחושך
המחקר בדק גם עד כמה המסגרת עומדת בפני תוקפים שמנסים להסיק אילו מסלולים שומשו בזמן האימון או לשחזר מסלולים רגישים. באמצעות בדיקת התקפות פרטיות סטנדרטיות, המחברים מצאו ש-SPHTRLM שמרה על שיעור הצלחת התקפות כאלה מתחת ל-5%, קרוב להנחתה אקראית. ההגנה נבעה משילוב של עדכונים מוצפנים, שיתוף מידע מוגבל ורעש מכוון באותות הלמידה. יחד עם זאת, ביצועי הניווט נשארו חזקים, מה שמעיד שניתן להגן על פרטיות ללא פגיעה מהותית ביכולת הלמידה של הרובוט.
מה המשמעות עבור רובוטים בעולם האמיתי
ללא מומחים, המסר המרכזי הוא שרובוטים יכולים כיום להתאמן לנוע בבטחה וביעילות בסביבות משתנות מבלי לחשוף את כל מה שהם חשים ומחליטים. SPHTRLM מראה כיצד לשזור יחד למידה, כוונון ופרטיות בעיצוב יחיד שמתאים למגבלות חישוביות ריאליות. הדבר מקרב רובוטי מחסן שמודעים לפרטיות, רובוטי שירות בבתי חולים או רחפני בדיקה במתקנים רגישים למציאות היומיומית, שבה הם יכולים להסתגל בזמן אמת ועדיין לכבד את המידע שהם נתקלים בו.
ציטוט: Dewangan, R.R., Thombre, D., Parganiha, V. et al. SPHTRLM: secure and privacy-preserving hyperparameter-tuned reinforcement learning method for robot path finding in dynamic environments. Sci Rep 16, 16114 (2026). https://doi.org/10.1038/s41598-026-48141-x
מילות מפתח: ניווט רובוטי, למידת חיזוק, בינה מלאכותית שומרת פרטיות, למידה פדרטיבית, סביבות דינמיות