Clear Sky Science · sv
SPHTRLM: säker och integritetsbevarande hyperparametertunad förstärkningsinlärningsmetod för robotvägplanering i dynamiska miljöer
Robotar som kan lära sig i rörelse
Föreställ dig en lagerrobot som måste slingra sig mellan förskjutna högar av kartonger samtidigt som den skyddar kunddata. Denna artikel presenterar ett nytt sätt för sådana robotar att lära sig bättre rutter i trånga, föränderliga miljöer samtidigt som den känsliga information de möter bevaras. Arbetet visar hur smart inlärning, säker navigering och stark integritet kan kombineras i ett praktiskt system.
Varför rörliga robotar ställs inför svåra val
Robotar som rör sig i världen måste ständigt fatta beslut: vart ska de gå härnäst, vilket hinder ska de undvika och hur når de målet snabbt utan att krocka. Klassiska planeringsmetoder fungerar bra om miljön förändras lite och är kartlagd i förväg, men de får svårt när människor, vagnar eller andra robotar rör sig oförutsägbart. Modern förstärkningsinlärning låter en robot förbättra sig genom försök och fel, men kräver vanligtvis mycket finjustering och öppen åtkomst till all insamlad data. Det skapar två stora problem för verkliga implementationer: inlärningen kan bli instabil i snabbt föränderlig miljö, och datan kan avslöja känsliga detaljer om platser, personer eller verksamheter.
Ett enhetligt system för säker och privat inlärning
Författarna föreslår en ram kallad SPHTRLM som tar itu med navigationskvalitet, inlärningsstabilitet och integritet samtidigt. I deras uppställning rör sig roboten på ett rutnät och väljer enkla steg upp, ner, vänster eller höger medan hinder och mål förändrar sina positioner över tid. Systemet belönar roboten för att den kommer närmare målet, straffar den för att den kolliderar med hinder och uppmuntrar den försiktigt att utforska nya vägar istället för att fastna i vanor. Avgörande är att dessa belöningar inte är fasta utan anpassas efter hur trångt det är och hur effektivt roboten rör sig, vilket hjälper den att förbli effektiv när förhållandena skiftar.
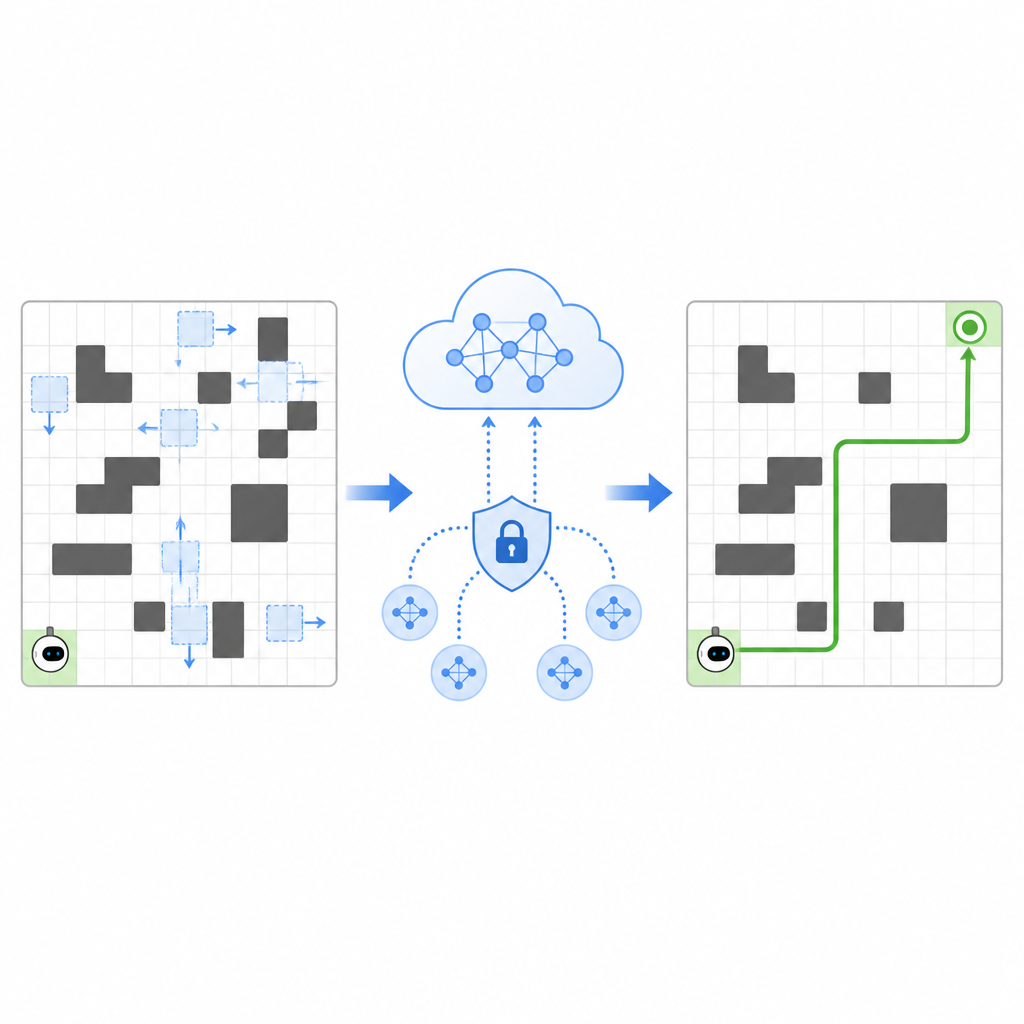
Dela erfarenhet utan att dela hemligheter
För att snabba upp inlärningen tillåter SPHTRLM flera robotar eller agenter att lära sig parallellt och dela vad de upptäckt. Istället för att skicka råa kartor eller detaljerade rutter till en central server behåller varje robot sin egen erfarenhet lokalt och skickar periodiskt kompakta, krypterade sammanfattningar av vad den lärt sig. Tekniker hämtade från federated learning gör det möjligt att kombinera dessa sammanfattningar till en starkare gemensam strategi, som sedan skickas tillbaka till robotarna. Extra brus läggs till på ett kontrollerat sätt för att dölja detaljer, och noggrant utvald kryptering säkerställer att även om någon avlyssnar uppdateringarna kan de inte enkelt återskapa var robotarna varit eller vad de sett.
Bättre inlärning, kortare vägar, färre krascher
I datorexperiment på ett tio gånger tio-rutnät fullt av rörliga hinder jämfördes SPHTRLM med flera populära inlärningsmetoder. Det nådde sina mål i cirka 95 procent av testkörningarna och slog standard Q-learning och djupa förstärkningsinlärningsbaslinjer. De rutter som upptäcktes var i genomsnitt cirka 20–25 procent kortare, vilket innebar att roboten slösade mindre tid på att irra runt. Den konvergerade också till gott beteende ungefär en tredjedel snabbare, och dess kollisionstal sjönk till en mycket låg nivå även när rutnätet var starkt stökigt. Trots de extra stegen för att skydda data hölls genomsnittsbeslutstiden i intervallet några hundradelar av en sekund, vilket är lämpligt för realtidsstyrning.
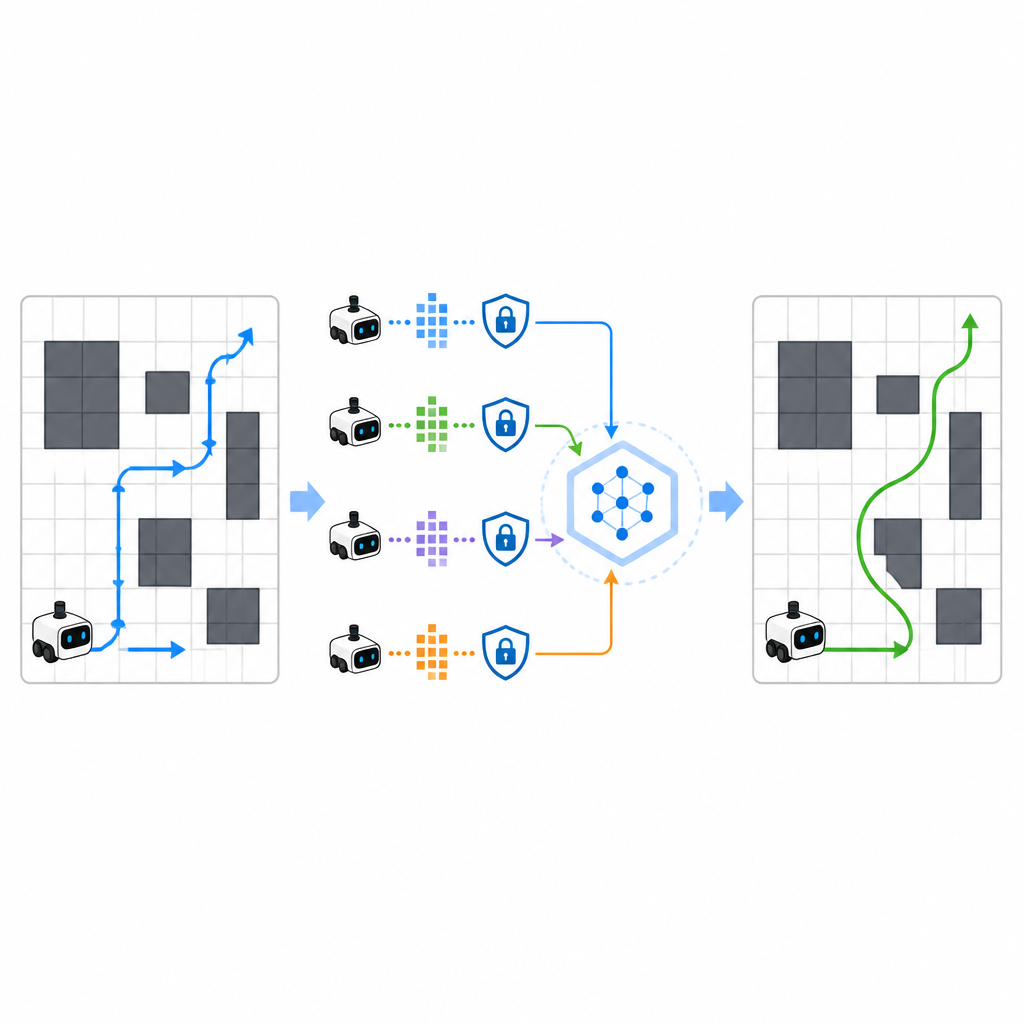
Hålla angripare i mörkret
Studien undersökte också hur väl ramen står emot angripare som försöker sluta sig till vilka rutter som användes under träning eller återskapa känsliga banor. Genom att testa standardintegritetsattacker fann författarna att SPHTRLM höll framgångsgraden för sådana attacker under fem procent, nära slumpmässig gissning. Det skyddet kom från kombinationen av krypterade uppdateringar, begränsad informationsdelning och avsiktligt brus i inlärningssignalerna. Samtidigt förblev navigationsprestandan stark, vilket tyder på att det är möjligt att skydda integritet utan att förlama robotens förmåga att lära.
Vad detta innebär för robotar i verkliga världen
För icke-specialister är huvudbudskapet att robotar nu kan tränas att röra sig säkert och effektivt i föränderliga miljöer utan att exponera allt de uppfattar och beslutar. SPHTRLM visar hur man väver samman inlärning, fininställning och integritet i en enda design som passar inom realistiska beräkningsbegränsningar. Detta för robotar med integritetsmedvetenhet i lagerlokaler, servicerobotar på sjukhus eller inspektionsdronor i känsliga anläggningar ett steg närmare vardagsbruk, där de kan anpassa sig i farten samtidigt som de respekterar den information de möter.
Citering: Dewangan, R.R., Thombre, D., Parganiha, V. et al. SPHTRLM: secure and privacy-preserving hyperparameter-tuned reinforcement learning method for robot path finding in dynamic environments. Sci Rep 16, 16114 (2026). https://doi.org/10.1038/s41598-026-48141-x
Nyckelord: robotnavigering, förstärkningsinlärning, integritetsbevarande AI, federated learning, dynamiska miljöer