Clear Sky Science · pl
SPHTRLM: bezpieczna i zachowująca prywatność metoda uczenia ze wzmocnieniem z dostrajanymi hiperparametrami do znajdowania tras robotów w dynamicznych środowiskach
Roboty, które uczą się w ruchu
Wyobraźmy sobie robota magazynowego, który musi przemykać między przesuwającymi się stosami pudeł, jednocześnie chroniąc dane klientów. W artykule zaprezentowano nowy sposób, dzięki któremu takie roboty mogą uczyć się lepszych tras w zatłoczonych, zmieniających się przestrzeniach, a przy tym zabezpieczać wrażliwe informacje, z którymi się stykają. Praca pokazuje, jak połączyć inteligentne uczenie, bezpieczną nawigację i silną ochronę prywatności w jednym praktycznym systemie.
Dlaczego poruszające się roboty stoją przed trudnymi wyborami
Roboty przemieszczające się w świecie muszą nieustannie podejmować decyzje: dokąd iść dalej, jak ominąć przeszkodę i jak szybko osiągnąć cel bez kolizji. Klasyczne metody planowania sprawdzają się, gdy otoczenie zmienia się niewiele i jest zmapowane z góry, ale zawodzą, gdy ludzie, wózki lub inne roboty poruszają się nieprzewidywalnie. Nowoczesne uczenie ze wzmocnieniem pozwala robotowi poprawiać się metodą prób i błędów, lecz zwykle wymaga dużego dostrajania i otwartego dostępu do wszystkich zebranych danych. To rodzi dwa poważne problemy w zastosowaniach: uczenie może stać się niestabilne w szybko zmieniających się warunkach, a dane mogą ujawniać wrażliwe informacje o lokalizacjach, osobach czy operacjach.
Zunifikowany system dla bezpiecznego i prywatnego uczenia
Autorzy proponują ramy nazwane SPHTRLM, które jednocześnie radzą sobie z jakością nawigacji, stabilnością uczenia i ochroną prywatności. W ich ustawieniu robot porusza się po siatce, wybierając proste kroki w górę, dół, w lewo lub w prawo, podczas gdy pozycje przeszkód i celów zmieniają się w czasie. System nagradza robota za zbliżanie się do celu, karze za zderzenia z przeszkodami i delikatnie zachęca do eksploracji nowych tras zamiast utknięcia w nawykach. Co istotne, te nagrody nie są stałe, lecz dostosowują się w oparciu o zatłoczenie przestrzeni i efektywność poruszania się robota, co pomaga mu zachować skuteczność w zmieniających się warunkach.
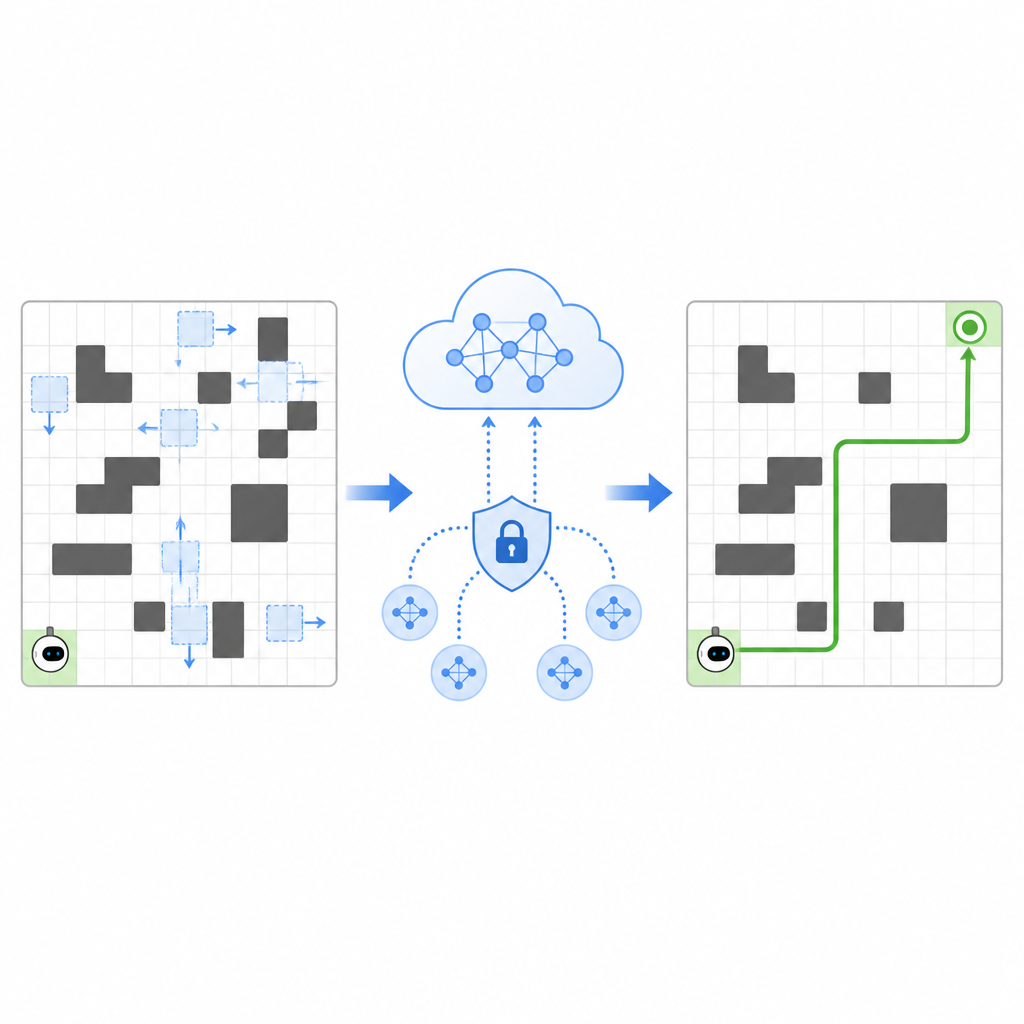
Wymiana doświadczeń bez ujawniania sekretów
Aby przyspieszyć uczenie, SPHTRLM pozwala kilku robotom lub agentom uczyć się równolegle i wymieniać odkryciami. Zamiast przesyłać surowe mapy czy szczegółowe ścieżki do centralnego serwera, każdy robot przechowuje własne doświadczenia lokalnie i okresowo wysyła zwarty, zaszyfrowany skrót tego, czego się nauczył. Techniki zapożyczone z uczenia federacyjnego umożliwiają połączenie tych skrótów w silniejszą wspólną strategię, którą następnie rozsyła się z powrotem do robotów. Dodatkowy szum jest wprowadzany w kontrolowany sposób, by ukryć szczegółowe dane, a starannie dobrane szyfrowanie sprawia, że nawet jeśli ktoś przechwyci aktualizacje, nie będzie mógł łatwo odtworzyć, gdzie roboty się poruszały ani co widziały.
Szybsze uczenie, krótsze trasy, mniej kolizji
W eksperymentach komputerowych na siatce dziesięć na dziesięć pełnej poruszających się przeszkód SPHTRLM porównano z kilkoma popularnymi metodami uczenia. Osiągał cele w około dziewięćdziesięciu pięciu procentach testów, przewyższając standardowe Q-learning i bazowe metody głębokiego uczenia ze wzmocnieniem. Odkrywane trasy były średnio krótsze o około dwadzieścia do dwudziestu pięciu procent, co oznacza, że robot marnował mniej czasu na błądzenie. System zbiegał do dobrego zachowania około jedną trzecią szybciej, a wskaźnik kolizji spadł do bardzo niskiego poziomu nawet przy dużym natężeniu przeszkód. Pomimo dodatkowych kroków potrzebnych do ochrony danych, średni czas podejmowania decyzji pozostał w granicach kilku setnych sekundy, co jest odpowiednie dla sterowania w czasie rzeczywistym.
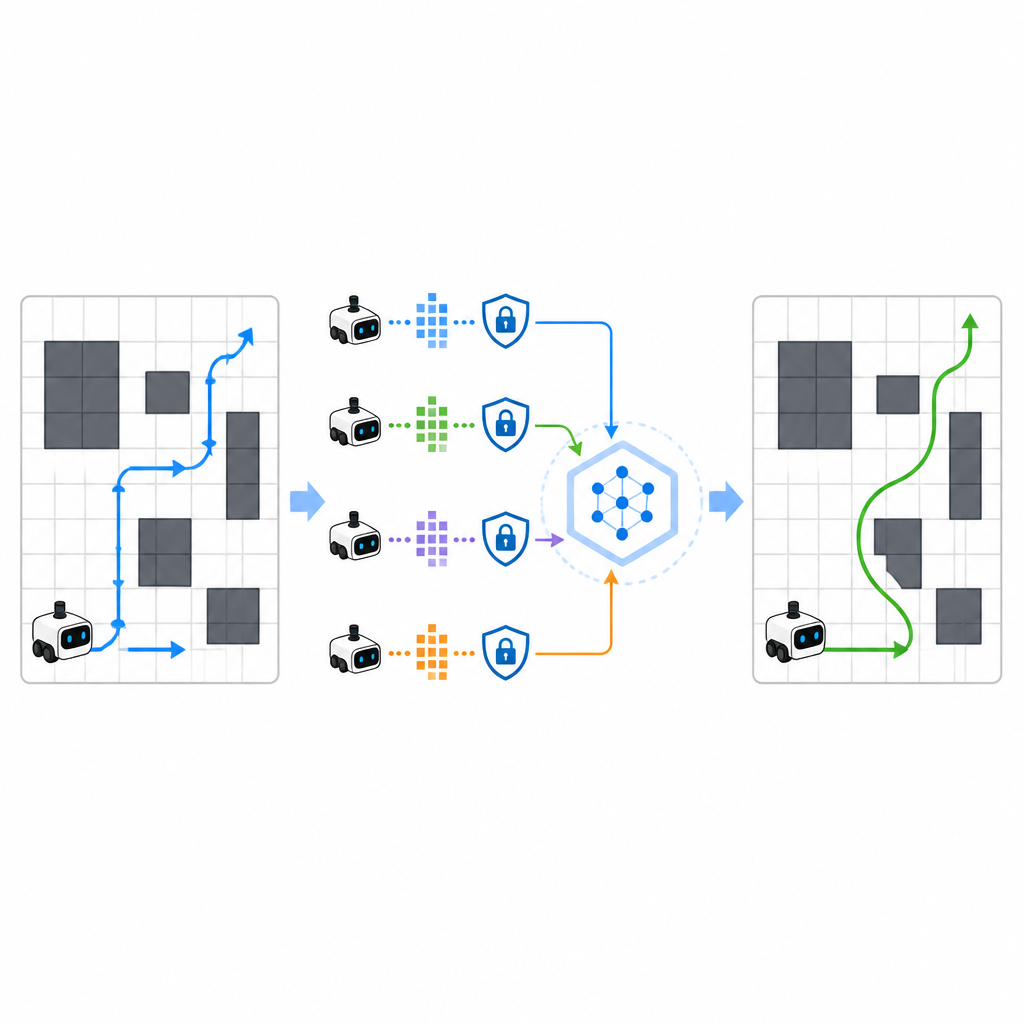
Trzymanie atakujących w nieświadomości
Badanie sprawdziło również, jak dobrze ramy wytrzymują próby atakujących, którzy starają się odgadnąć, jakie trasy były używane podczas treningu, lub odtworzyć wrażliwe trajektorie. Testując standardowe ataki prywatności, autorzy stwierdzili, że SPHTRLM utrzymywał skuteczność takich ataków poniżej pięciu procent, blisko losowego zgadywania. Ochrona ta wynikała z połączenia zaszyfrowanych aktualizacji, ograniczonego udostępniania informacji i celowego szumu w sygnałach uczących. Jednocześnie wydajność nawigacji pozostała wysoka, co sugeruje, że można chronić prywatność bez paraliżowania zdolności robotów do uczenia się.
Co to oznacza dla robotów w rzeczywistym świecie
Dla niereperów kluczowym przesłaniem jest to, że roboty można teraz szkolić do poruszania się bezpiecznie i efektywnie w zmieniających się środowiskach, nie ujawniając wszystkiego, co wykrywają i jak podejmują decyzje. SPHTRLM pokazuje, jak spleść ze sobą uczenie, strojenie i prywatność w jednym projekcie mieszczącym się w realistycznych ograniczeniach obliczeniowych. Zbliża to do codziennej rzeczywistości prywatnościowo świadome roboty magazynowe, roboty usługowe w szpitalach czy drony inspekcyjne w obiektach o podwyższonej wrażliwości, które potrafią adaptować się w locie, jednocześnie szanując informacje, na które natrafiają.
Cytowanie: Dewangan, R.R., Thombre, D., Parganiha, V. et al. SPHTRLM: secure and privacy-preserving hyperparameter-tuned reinforcement learning method for robot path finding in dynamic environments. Sci Rep 16, 16114 (2026). https://doi.org/10.1038/s41598-026-48141-x
Słowa kluczowe: nawigacja robotów, uczenie ze wzmocnieniem, Sztuczna inteligencja zachowująca prywatność, uczenie federacyjne, środowiska dynamiczne