Clear Sky Science · it
SPHTRLM: metodo di apprendimento per rinforzo con iperparametri sicuri e a tutela della privacy per la ricerca del percorso dei robot in ambienti dinamici
Robot che possono imparare in movimento
Immaginate un robot da magazzino che deve districarsi tra pile di scatole che si spostano, proteggendo allo stesso tempo i dati dei clienti. Questo articolo presenta un nuovo approccio che permette a tali robot di apprendere percorsi migliori in spazi affollati e in evoluzione, salvaguardando al contempo le informazioni sensibili che incontrano. Il lavoro mostra come combinare apprendimento intelligente, navigazione sicura e forte tutela della privacy in un sistema pratico.
Perché i robot in movimento affrontano scelte difficili
I robot che si muovono nel mondo devono prendere decisioni costanti: dove andare, quale ostacolo evitare e come raggiungere un obiettivo rapidamente senza urtare nulla. I metodi di pianificazione classici funzionano bene se l’ambiente cambia poco ed è mappato in anticipo, ma faticano quando persone, carrelli o altri robot si muovono in modo imprevedibile. L’apprendimento per rinforzo moderno permette a un robot di migliorare per tentativi, ma richiede di solito molta messa a punto e accesso aperto a tutti i dati raccolti. Questo crea due problemi principali per le applicazioni reali: l’apprendimento può diventare instabile in contesti rapidamente mutevoli e i dati possono rivelare dettagli sensibili su luoghi, persone o operazioni.
Un sistema unificato per apprendimento sicuro e privato
Gli autori propongono un framework chiamato SPHTRLM che affronta contemporaneamente qualità della navigazione, stabilità dell’apprendimento e privacy. Nel loro scenario, il robot si muove su una griglia scegliendo semplici passi su, giù, a sinistra o a destra mentre le posizioni di ostacoli e obiettivi cambiano nel tempo. Il sistema ricompensa il robot quando si avvicina all’obiettivo, lo penalizza per gli urti contro gli ostacoli e lo incoraggia moderatamente a esplorare nuove rotte invece di cristallizzarsi in abitudini. Fondamentale è che queste ricompense non sono fisse ma si adattano in base a quanto è affollato lo spazio e a quanto efficacemente il robot si muove, il che lo aiuta a rimanere efficace al variare delle condizioni.
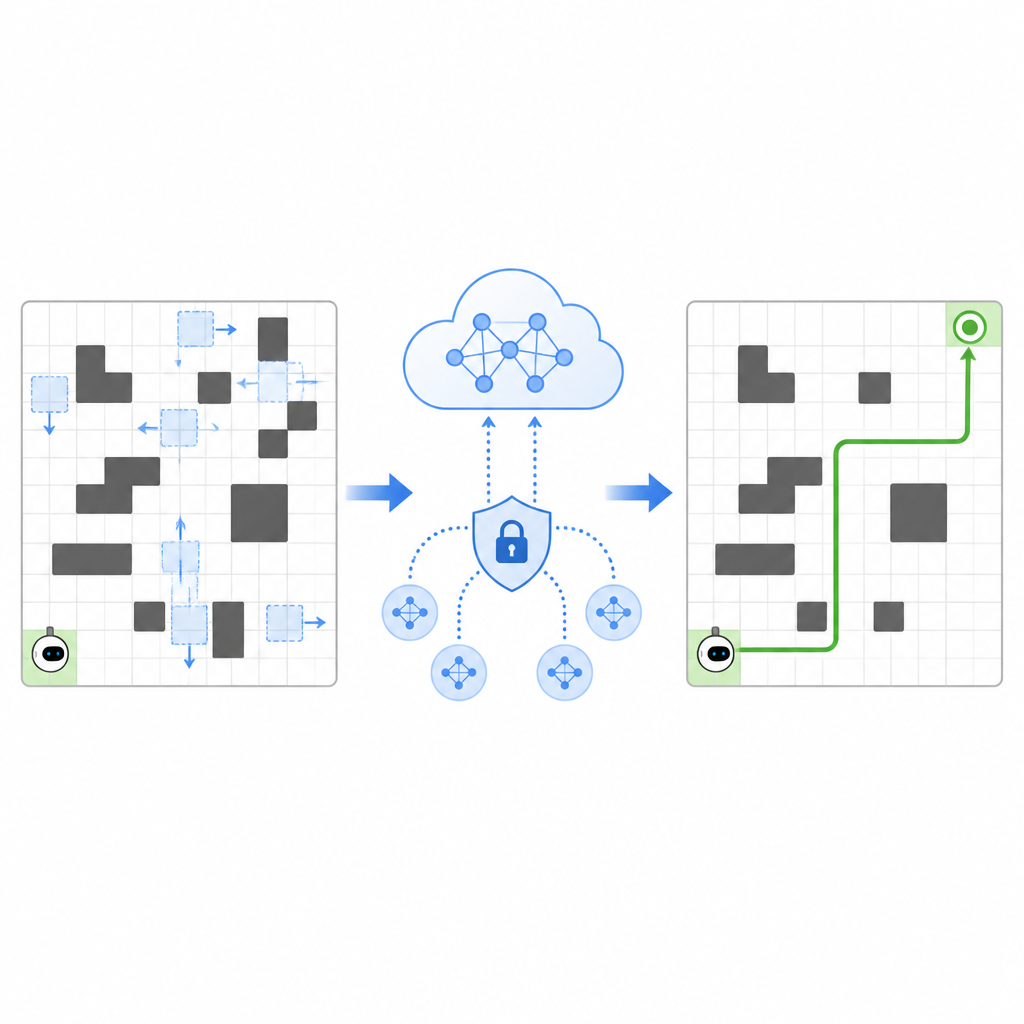
Condividere l’esperienza senza rivelare i segreti
Per accelerare l’apprendimento, SPHTRLM permette a più robot o agenti di imparare in parallelo e di condividere ciò che hanno scoperto. Invece di inviare mappe grezze o percorsi dettagliati a un server centrale, ogni robot conserva la propria esperienza localmente e invia periodicamente sommari compatti e cifrati di quanto appreso. Tecniche derivate dall’apprendimento federato rendono possibile combinare questi sommari in una strategia comune più solida, per poi inviare il piano migliorato ai robot. Viene aggiunto rumore controllato per nascondere dettagli fini e crittografie scelte con cura garantiscono che, anche se qualcuno intercettasse gli aggiornamenti, non possa ricostruire facilmente dove si sono mossi i robot o cosa hanno visto.
Apprendimento più veloce, percorsi più brevi, meno collisioni
In esperimenti al computer su una griglia dieci per dieci piena di ostacoli in movimento, SPHTRLM è stato confrontato con diversi metodi di apprendimento popolari. Ha raggiunto i suoi obiettivi in circa il novantacinque percento delle prove, superando Q-learning standard e baseline di deep reinforcement learning. I percorsi scoperti erano in media circa il venti-venticinque percento più corti, il che significa che il robot perdeva meno tempo a vagare. Ha inoltre convergendo verso comportamenti efficaci circa un terzo più rapidamente, e il tasso di collisione è sceso a un livello molto basso anche quando la griglia era fortemente ingombrata. Nonostante i passaggi aggiuntivi necessari per proteggere i dati, il tempo medio di decisione è rimasto nell’ordine di pochi centesimi di secondo, adatto per il controllo in tempo reale.
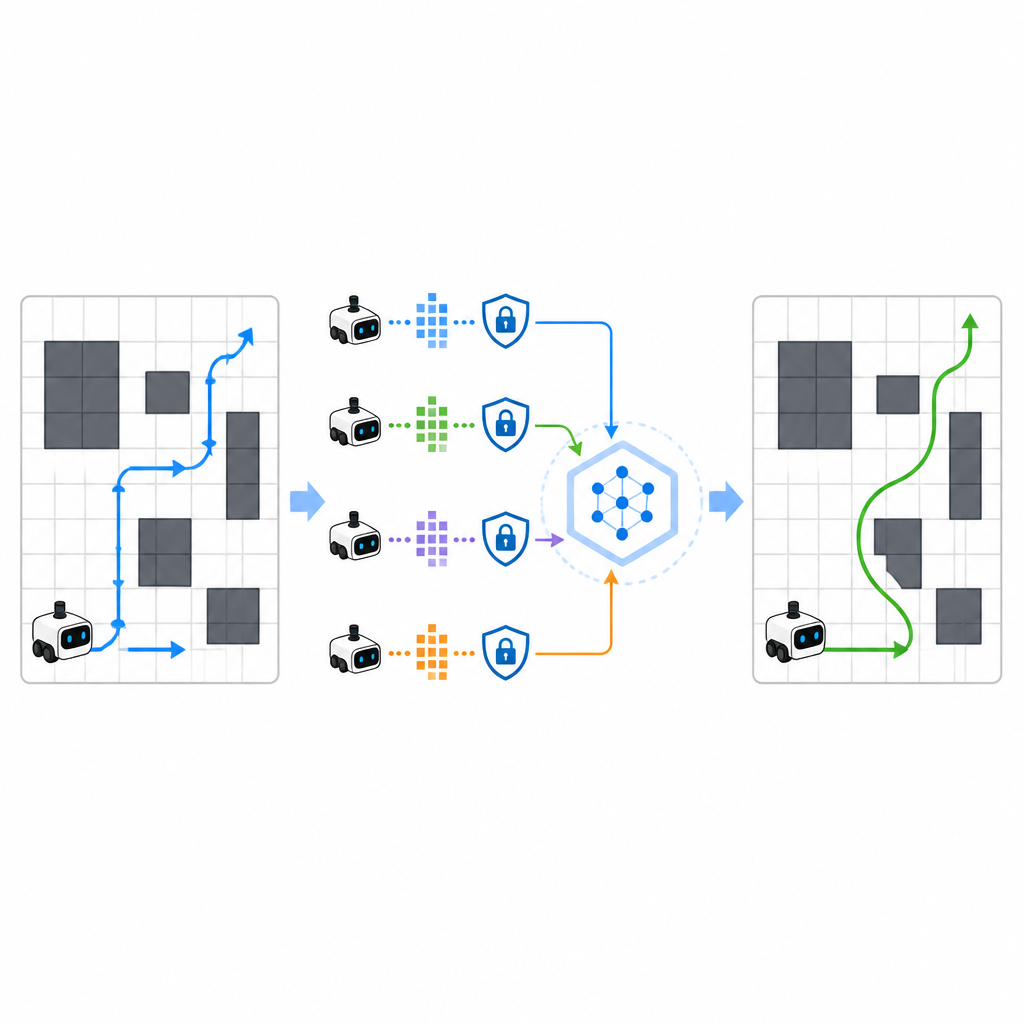
Tenere gli aggressori all’oscuro
Lo studio ha verificato anche quanto il framework resista ad attacchi volti a inferire quali rotte sono state usate durante l’addestramento o a ricostruire traiettorie sensibili. Testando attacchi di privacy standard, gli autori hanno trovato che SPHTRLM manteneva il tasso di successo di tali attacchi sotto il cinque percento, vicino al livello di un’ipotesi casuale. Questa protezione deriva dalla combinazione di aggiornamenti cifrati, condivisione limitata delle informazioni e rumore deliberato nei segnali di apprendimento. Allo stesso tempo, le prestazioni di navigazione sono rimaste solide, suggerendo che è possibile proteggere la privacy senza compromettere la capacità del robot di imparare.
Cosa significa per i robot nel mondo reale
Per i non specialisti, il messaggio chiave è che ora i robot possono essere addestrati a muoversi in modo sicuro ed efficiente in ambienti che cambiano, senza esporre tutto ciò che percepiscono e decidono. SPHTRLM mostra come intrecciare apprendimento, ottimizzazione e privacy in un’unica progettazione compatibile con limiti di calcolo realistici. Questo avvicina robot da magazzino attenti alla privacy, robot di servizio negli ospedali o droni di ispezione in strutture sensibili a una realtà quotidiana in cui possono adattarsi al volo rispettando le informazioni che incontrano.
Citazione: Dewangan, R.R., Thombre, D., Parganiha, V. et al. SPHTRLM: secure and privacy-preserving hyperparameter-tuned reinforcement learning method for robot path finding in dynamic environments. Sci Rep 16, 16114 (2026). https://doi.org/10.1038/s41598-026-48141-x
Parole chiave: navigazione robotica, apprendimento per rinforzo, IA che preserva la privacy, apprendimento federato, ambienti dinamici