Clear Sky Science · ja
SPHTRLM: 動的環境におけるロボット経路探索のための安全かつプライバシー保護されたハイパーパラメータ調整済み強化学習手法
移動しながら学習するロボット
倉庫内で積み重ねられた箱の間を縫うように動きながら顧客データを守らなければならないロボットを想像してください。本稿は、そのようなロボットが混雑して変化する空間でより良い経路を学習しつつ、通過中に得た機微な情報を保護する新しい方法を提示します。本研究は、賢い学習、安全なナビゲーション、強力なプライバシー保護を一つの実用的なシステムに統合するやり方を示しています。
移動するロボットが直面する難しい選択
移動するロボットは常に決定を下さなければなりません:次にどこへ行くか、どの障害物を避けるか、衝突せずに素早く目的地へ到達するにはどうするか。環境がほとんど変わらず事前にマッピングされている場合は従来の計画手法が有効ですが、人や台車、他のロボットが予測不能に動く状況では頼りになりません。現代の強化学習は試行錯誤によりロボットを改善できますが、通常は大量のチューニングと収集データへの開放的なアクセスを必要とします。これが実運用で問題となるのは二点です:変化の速い設定では学習が不安定になり得ること、そしてデータが位置情報や人物、業務の機微を露呈してしまう可能性があることです。
安全かつプライベートな学習の統合システム
著者らは、ナビゲーションの質、学習の安定性、プライバシー保護を同時に扱う枠組み「SPHTRLM」を提案します。設定ではロボットが格子上を移動し、上下左右の単純な一歩を選択します。障害物や目標の位置は時間とともに変化します。システムは目的地に近づくことに報酬を与え、障害物にぶつかればペナルティを課し、習慣に陥らないように新しい経路の探索を穏やかに促します。重要なのは、これらの報酬が固定ではなく、空間の混雑度やロボットの移動効率に応じて適応する点で、条件が変わっても有効性を保てるようになっています。
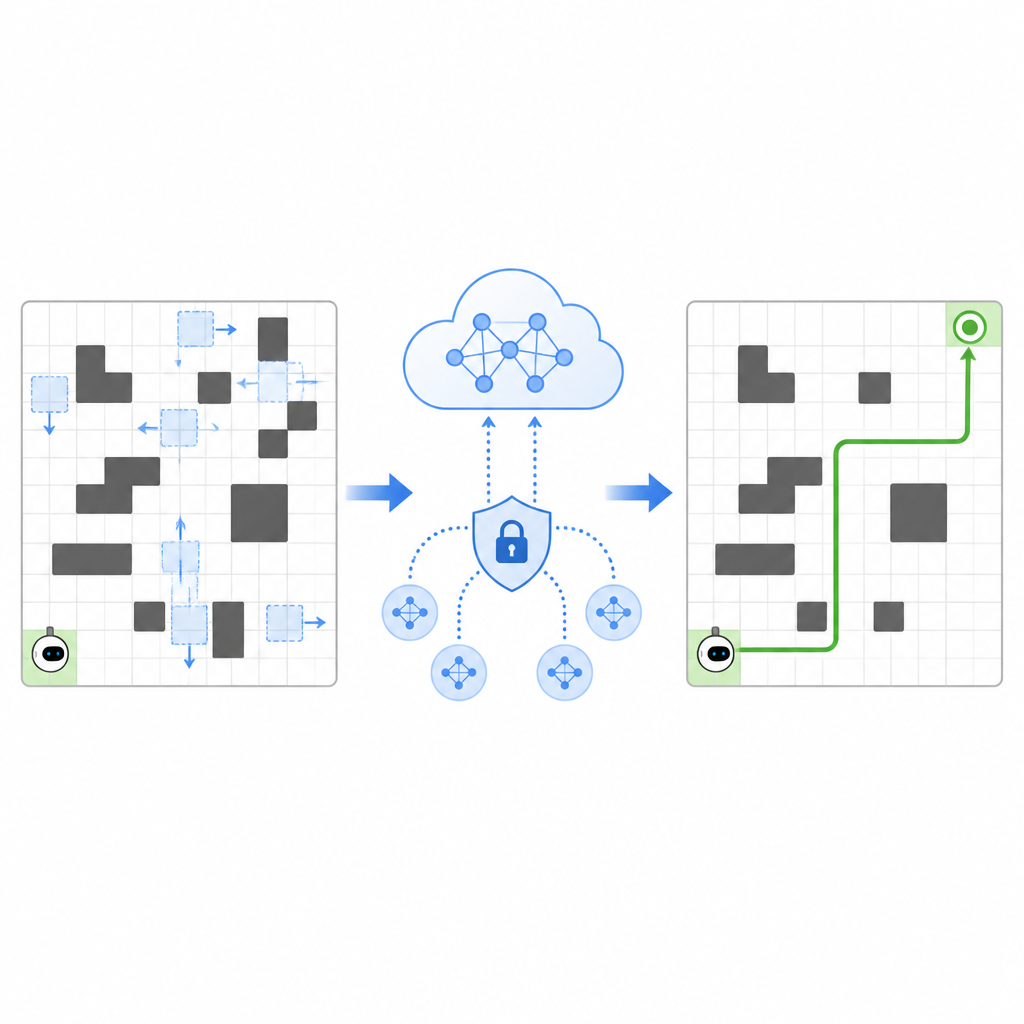
秘密を明かさずに経験を共有する
学習を加速するために、SPHTRLMは複数のロボットやエージェントが並行して学習し、発見したことを共有できるようにします。生の地図や詳細な経路を中央サーバに送る代わりに、各ロボットは自分の経験をローカルに保ち、定期的に学習内容の簡潔で暗号化された要約を送信します。フェデレーテッドラーニングから借用した手法により、これらの要約を統合してより強力な共通戦略を構築し、その改良版をロボットに戻すことが可能です。微細な情報を隠すために制御されたノイズが追加され、慎重に選ばれた暗号化により、たとえ更新が傍受されてもロボットの移動経路や観測内容を容易に復元できないようにしています。
より速い学習、短い経路、衝突の減少
移動する障害物で満たされた10×10の格子を用いた計算機実験で、SPHTRLMは複数の既存の学習手法と比較されました。テスト実行の約95%で目的に到達し、標準的なQ学習や深層強化学習のベースラインを上回りました。発見された経路は平均で約20〜25%短く、ロボットが無駄にさまよう時間が減りました。また良好な行動への収束はおよそ3分の1早まり、格子が非常に混雑している場合でも衝突率は非常に低い水準に落ちました。データ保護のための追加処理があっても、平均意思決定時間は数百分の一秒の範囲に収まり、リアルタイム制御に適しています。
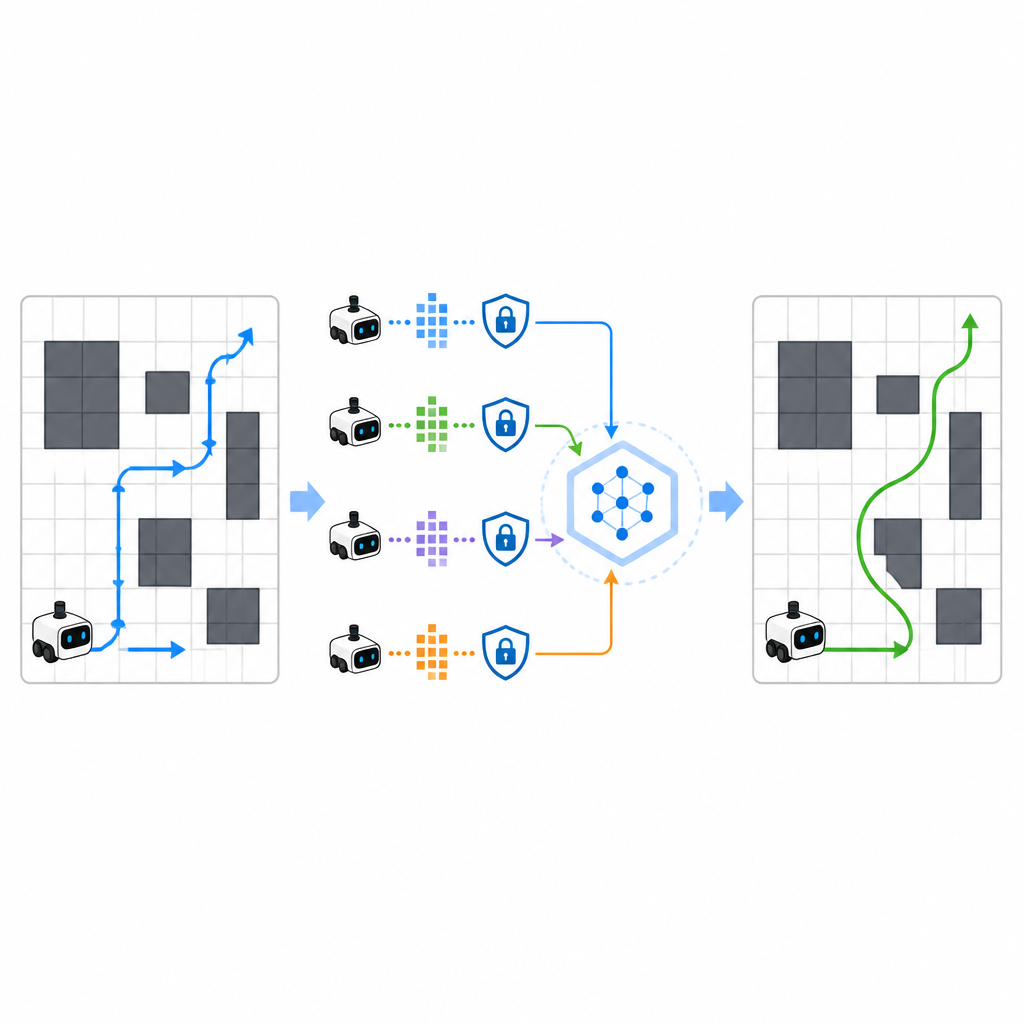
攻撃者を暗闇に置く
研究では、訓練中に使われた経路を推測したり機微な軌跡を復元しようとする攻撃者に対して枠組みがどれほど耐えられるかも検証しました。標準的なプライバシー攻撃を試した結果、SPHTRLMはそのような攻撃の成功率を約5%未満に抑え、ほぼランダム推測と同等のレベルに達しました。この保護は、暗号化された更新、情報共有の制限、学習信号への意図的なノイズの組合せによってもたらされました。同時にナビゲーション性能は堅調に維持されており、ロボットの学習能力を損なうことなくプライバシーを守ることが可能であることを示唆しています。
実世界のロボットにとっての意義
非専門家向けの要点は、ロボットは今や、変化する環境で安全かつ効率的に動くよう訓練でき、その際にセンシティブな観測や意思決定をすべて公開する必要はない、ということです。SPHTRLMは学習、調整、プライバシー保護を現実的な計算制約の範囲で組み合わせる方法を示します。これにより、プライバシーに配慮した倉庫ロボット、病院でのサービスロボット、あるいは機密性の高い施設での点検ドローンが、現場で即応的に適応しつつ遭遇する情報を尊重する日常へ一歩近づきます。
引用: Dewangan, R.R., Thombre, D., Parganiha, V. et al. SPHTRLM: secure and privacy-preserving hyperparameter-tuned reinforcement learning method for robot path finding in dynamic environments. Sci Rep 16, 16114 (2026). https://doi.org/10.1038/s41598-026-48141-x
キーワード: ロボットナビゲーション, 強化学習, プライバシー保護AI, フェデレーテッドラーニング, 動的環境