Clear Sky Science · ar
SPHTRLM: طريقة تعلم تعزيز مضبوطة للمعاملات تحافظ على الأمان والخصوصية لتحديد مسار الروبوت في بيئات ديناميكية
روبوتات تتعلم أثناء الحركة
تخيّل روبوتاً في مستودع يجب أن يتنقل بين أكوام صناديق متحركة مع الحفاظ على سرية بيانات العملاء. يقدم هذا البحث طريقة جديدة لتمكين مثل هذه الروبوتات من تعلم مسارات أفضل في مساحات مزدحمة ومتغيرة مع حماية المعلومات الحساسة التي تواجهها أثناء العمل. يوضح العمل كيفية دمج التعلم الذكي والملاحة الآمنة والخصوصية القوية في نظام عملي واحد.
لماذا تواجه الروبوتات المتحركة اختيارات صعبة
على الروبوتات المتحركة أن تتخذ قرارات باستمرار: إلى أين تتجه بعد ذلك، أي عقبة تتجنب، وكيف تصل إلى الهدف بسرعة دون اصطدام. تعمل أساليب التخطيط التقليدية جيدًا إذا كانت البيئة ثابتة ومُرسمَة مسبقًا، لكنها تواجه صعوبة عندما يتحرّك الناس، أو العربات، أو روبوتات أخرى بشكل غير متوقع. يتيح التعلم التعزيزي الحديث للروبوت التحسّن عن طريق التجربة والخطأ، لكنه عادةً يتطلّب ضبطًا دقيقًا كثيرًا والوصول المفتوح إلى كل البيانات التي يجمعها. هذا يخلق مشكلتين كبيرتين في النشر العملي: قد يصبح التعلم غير مستقر في البيئات سريعة التغير، وقد تكشف البيانات عن تفاصيل حساسة حول المواقع أو الأشخاص أو العمليات.
نظام موحّد للتعلم الآمن والخاص
يقدّم المؤلفون إطار عمل يسمّى SPHTRLM يتعامل مع جودة الملاحة، واستقرار التعلم، والخصوصية في نفس الوقت. في إعدادهم، يتحرك الروبوت على شبكة مكوّنة من خلايا، مختارًا خطوات بسيطة لأعلى أو لأسفل أو لليسار أو لليمين بينما تتغير مواقع العقبات والأهداف مع مرور الزمن. يكافئ النظام الروبوت عند اقترابه من هدفه، ويعاقبه عند الاصطدام بالعقبات، ويشجّعه بلطف على استكشاف مسارات جديدة بدلاً من التعلّق بعادات قديمة. وبشكل أساسي، لا تكون هذه المكافآت ثابتة بل تتكيف تبعًا لمدى ازدحام المساحة وكفاءة حركة الروبوت، مما يساعده على البقاء فعّالًا مع تغير الظروف.
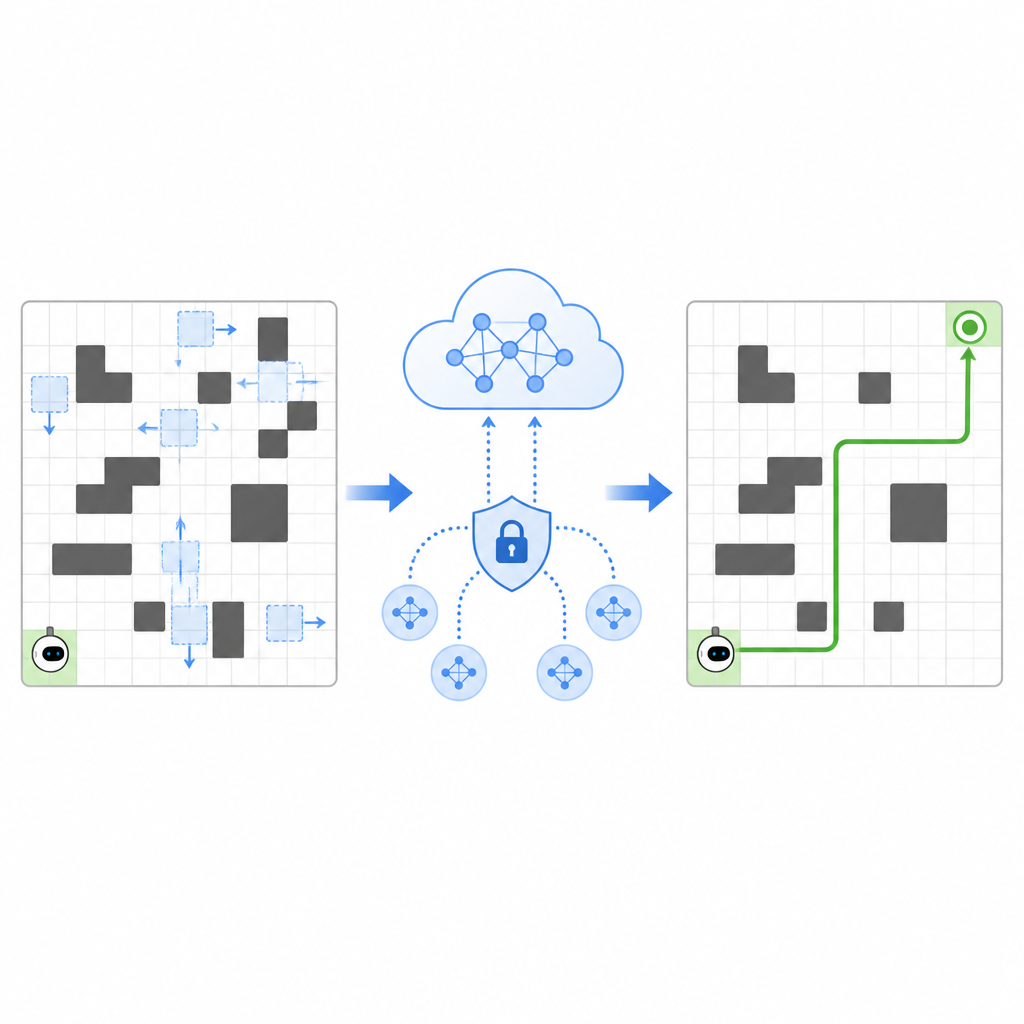
مشاركة الخبرة دون مشاركة الأسرار
لتسريع عملية التعلم، يسمح SPHTRLM لعدة روبوتات أو وكلاء بالتعلم بالتوازي ومشاركة ما اكتشفوه. بدلاً من إرسال خرائط خام أو مسارات تفصيلية إلى خادم مركزي، يحتفظ كل روبوت بتجاربه محليًا ويرسل دورياً ملخصات مضغوطة ومشفرة لما تعلّمه. تقنيات مستعارة من التعلم الموزع تجعل من الممكن دمج هذه الملخصات في استراتيجية مشتركة أقوى، ثم إعادة إرسال الخطة المحسّنة إلى الروبوتات. يُضاف ضوضاء إضافية بطريقة مسيطرة لإخفاء التفاصيل الدقيقة، وتضمن التشفير المختار بعناية أنه حتى لو اعترض أحد التحديثات، فلا يمكنه بسهولة إعادة تكوين الأماكن التي زارها الروبوتات أو ما شاهدوْه.
تعلم أسرع، مسارات أقصر، حوادث أقل
في تجارب حاسوبية على شبكة عشرة في عشرة مليئة بالعقبات المتحركة، قورن SPHTRLM بعدة أساليب تعلم شائعة. وصل إلى أهدافه في حوالي خمسة وتسعين في المئة من تجارب الاختبار، متفوقًا على خوارزميات Q التقليدية ونماذج التعلم التعزيزي العميق. كانت المسارات التي اكتشفها أقصر بحوالي عشرين إلى خمسة وعشرين في المئة في المتوسط، مما يعني أن الروبوت أضاع وقتًا أقل في التجوال. كما تلاقى على سلوك جيد أسرع بنحو ثلث الوقت، وانخفضت نسبة الاصطدامات إلى مستوى منخفض جدًا حتى عندما كانت الشبكة مزدحمة بشدة. وعلى الرغم من الخطوات الإضافية لحماية البيانات، بقي وقت اتخاذ القرار المتوسط في نطاق بضع مئات من الأجزاء من الثانية، وهو مناسب للتحكم في الوقت الحقيقي.
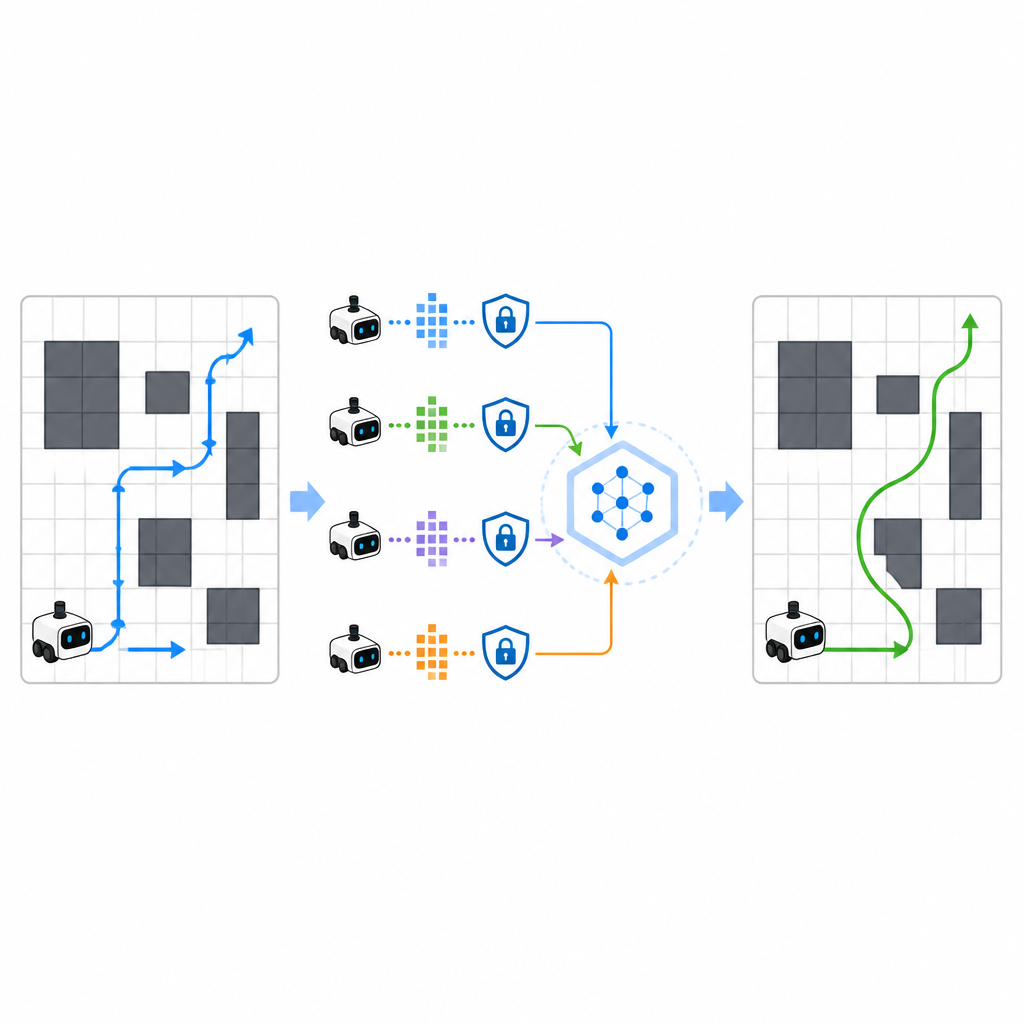
إبقاء المهاجمين في الظلام
سأل البحث أيضًا مدى صمود الإطار أمام مهاجمين يحاولون استنتاج المسارات المستخدمة أثناء التدريب أو إعادة بناء مسارات حساسة. عبر اختبار هجمات خصوصية معيارية، وجد المؤلفون أن SPHTRLM أبقى معدل نجاح مثل هذه الهجمات أقل من خمسة في المئة، قريبًا من التخمين العشوائي. جاءت هذه الحماية من مزيج التحديثات المشفّرة، وتقاسم المعلومات المحدود، والضوضاء المتعمدة في إشارات التعلم. وفي الوقت نفسه، ظلت أداءات الملاحة قوية، مما يشير إلى أنه من الممكن حماية الخصوصية دون تعريض قدرة الروبوت على التعلم للخطر.
ماذا يعني هذا لروبوتات العالم الحقيقي
بالنسبة لغير المتخصصين، الرسالة الأساسية هي أن الروبوتات يمكن تدريبها الآن للتحرك بأمان وكفاءة في بيئات متغيرة دون الكشف عن كل ما تستشعره وتقرّره. يوضح SPHTRLM كيف يمكن نسج التعلم والضبط والخصوصية في تصميم واحد يتناسب مع حدود الحوسبة الواقعية. هذا يقرب من الواقع اليومي روبوتات المستودعات الواعية بالخصوصية، وروبوتات الخدمة في المستشفيات، أو الطائرات بدون طيار التفتيشية في منشآت حساسة، بحيث يمكنها التكيّف بشكل فوري مع المحافظة على احترام المعلومات التي تواجهها.
الاستشهاد: Dewangan, R.R., Thombre, D., Parganiha, V. et al. SPHTRLM: secure and privacy-preserving hyperparameter-tuned reinforcement learning method for robot path finding in dynamic environments. Sci Rep 16, 16114 (2026). https://doi.org/10.1038/s41598-026-48141-x
الكلمات المفتاحية: تنقل الروبوت, التعلم التعزيزي, الذكاء الاصطناعي الحافظ للخصوصية, التعلم الموزع, البيئات الديناميكية