Clear Sky Science · tr
SPHTRLM: dinamik ortamlarda robot yol bulma için güvenli ve gizliliği koruyan hiperparametre ayarlı pekiştirmeli öğrenme yöntemi
Hareket Halindeki Öğrenebilen Robotlar
Şöyle bir depo robotu hayal edin: müşteri verilerini güvende tutarken yığılan kutuların arasında dolaşmak zorunda. Bu makale, böyle robotların yoğun ve değişen ortamlarda daha iyi yollar öğrenmesini sağlarken gördükleri hassas bilgileri de koruyan yeni bir yaklaşımı tanıtıyor. Çalışma, akıllı öğrenmeyi, güvenli gezinmeyi ve güçlü gizliliği tek bir pratik sistemde nasıl birleştirebileceğini gösteriyor.
Hareketli Robotların Zor Seçimleri
Dünyada hareket eden robotlar sürekli karar vermek zorunda: sırada nereye gitmeli, hangi engelden kaçınmalı ve çarpmadan hedefe nasıl hızlıca ulaşmalı. Klasik planlama yöntemleri ortam sabit ve önceden haritalıysa iyi çalışır, ancak insanlar, arabalar veya diğer robotlar öngörülemez şekilde hareket ettiğinde zorlanır. Modern pekiştirmeli öğrenme bir robotun deneme yanılma yoluyla gelişmesini sağlar, ama genellikle çok fazla ince ayar ve toplanan tüm verilere açık erişim gerektirir. Bu, gerçek uygulamalarda iki büyük sorun yaratır: hızlı değişen koşullarda öğrenme kararsız hale gelebilir ve veriler konumlar, insanlar veya operasyonlar hakkında hassas ayrıntıları açığa çıkarabilir.
Güvenli ve Gizli Öğrenme için Birleşik Sistem
Yazarlar, navigasyon kalitesi, öğrenme kararlılığı ve gizliliği aynı anda ele alan SPHTRLM adlı bir çerçeve öneriyor. Kurulumlarında robot bir ızgarada hareket ediyor, engellerin ve hedeflerin konumları zamanla değişirken yukarı, aşağı, sola veya sağa basit adımlar seçiyor. Sistem, robota hedefe yaklaşması için ödül veriyor, engellere çarpması durumunda ceza uyguluyor ve aynı rutine takılmak yerine yeni yollar keşfetmesini nazikçe teşvik ediyor. Kritik olarak, bu ödüller sabit değil; alanın ne kadar yoğun olduğu ve robotun ne kadar verimli hareket ettiği temelinde uyarlanıyor, bu da koşullar değiştikçe etkin kalmasına yardımcı oluyor.
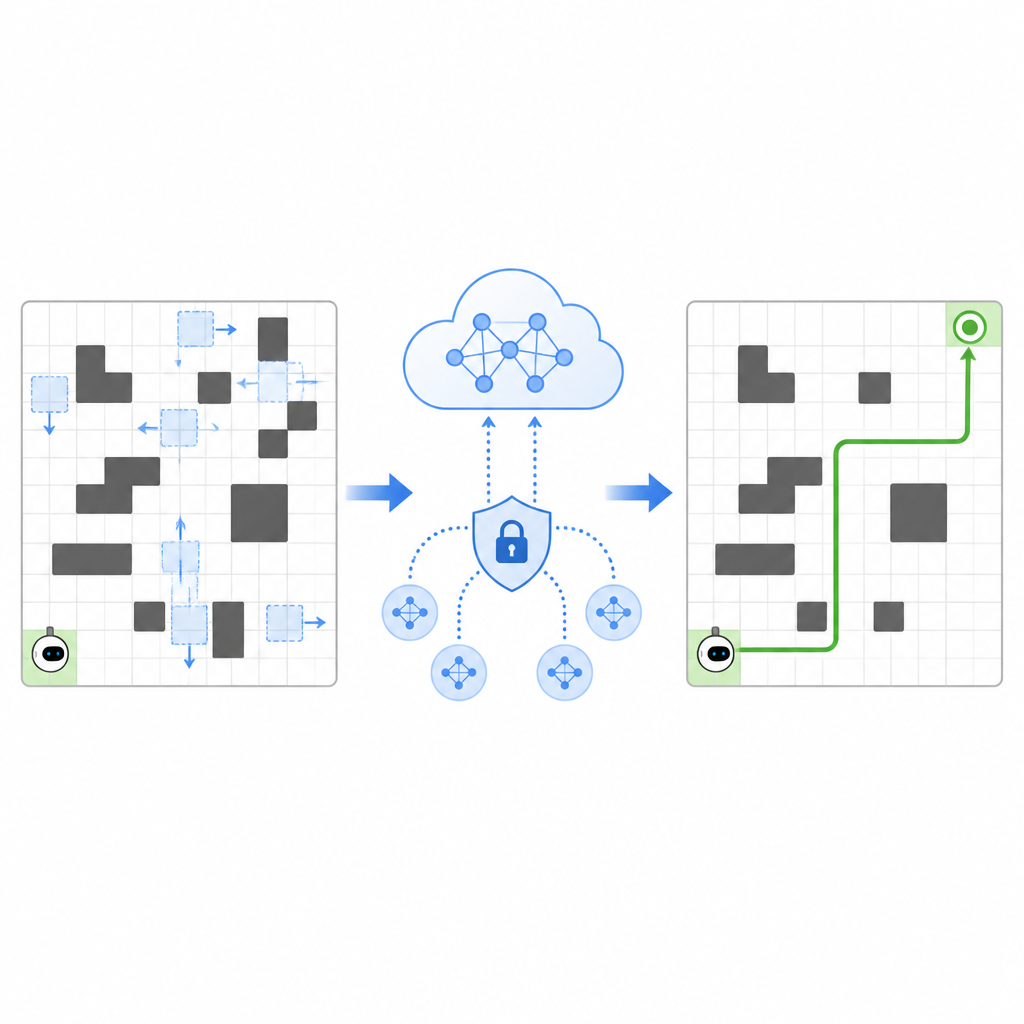
Sırları Paylaşmadan Deneyimi Paylaşmak
Öğrenmeyi hızlandırmak için SPHTRLM birden çok robotun veya ajanın paralel olarak öğrenmesine ve keşfettiklerini paylaşmasına izin veriyor. Ham haritaları veya ayrıntılı yolları merkezi sunucuya göndermek yerine her robot kendi deneyimini yerel olarak tutuyor ve periyodik olarak öğrendiklerinin kompakt, şifrelenmiş özetlerini iletiyor. Federe öğrenmeden ödünç alınan teknikler bu özetleri daha güçlü ortak bir stratejiye dönüştürmeyi mümkün kılıyor ve geliştirilmiş plan robotlara geri gönderiliyor. İnce ayrıntıları gizlemek için kontrollü şekilde ek gürültü ekleniyor ve dikkatle seçilmiş şifreleme, güncellemeler ele geçirilse bile robotların nereye gittiğini veya ne gördüğünü kolayca yeniden inşa etmeyi engelliyor.
Daha Hızlı Öğrenme, Daha Kısa Yollar, Daha Az Çarpışma
Hareketli engellerle dolu on çarpı on ızgarada yapılan bilgisayar deneylerinde SPHTRLM birkaç popüler öğrenme yöntemiyle karşılaştırıldı. Test koşularının yaklaşık yüzde doksan beşinde hedeflerine ulaştı ve standart Q-öğrenme ile derin pekiştirmeli öğrenme sınırlarını geride bıraktı. Keşfettiği yollar ortalamada yaklaşık yüzde yirmi ila yirmi beş daha kısaydı; bu da robotun dolaşarak daha az zaman kaybettiği anlamına geliyor. Ayrıca iyi davranışa yaklaşık üçte bir daha hızlı yakınsadı ve ızgara yoğun olarak dağınık olduğunda bile çarpışma oranı çok düşük seviyelere düştü. Verileri korumak için gereken ek adımlara rağmen ortalama karar süresi birkaç yüzde bir saniye aralığında kaldı; bu da gerçek zamanlı kontrol için uygun.
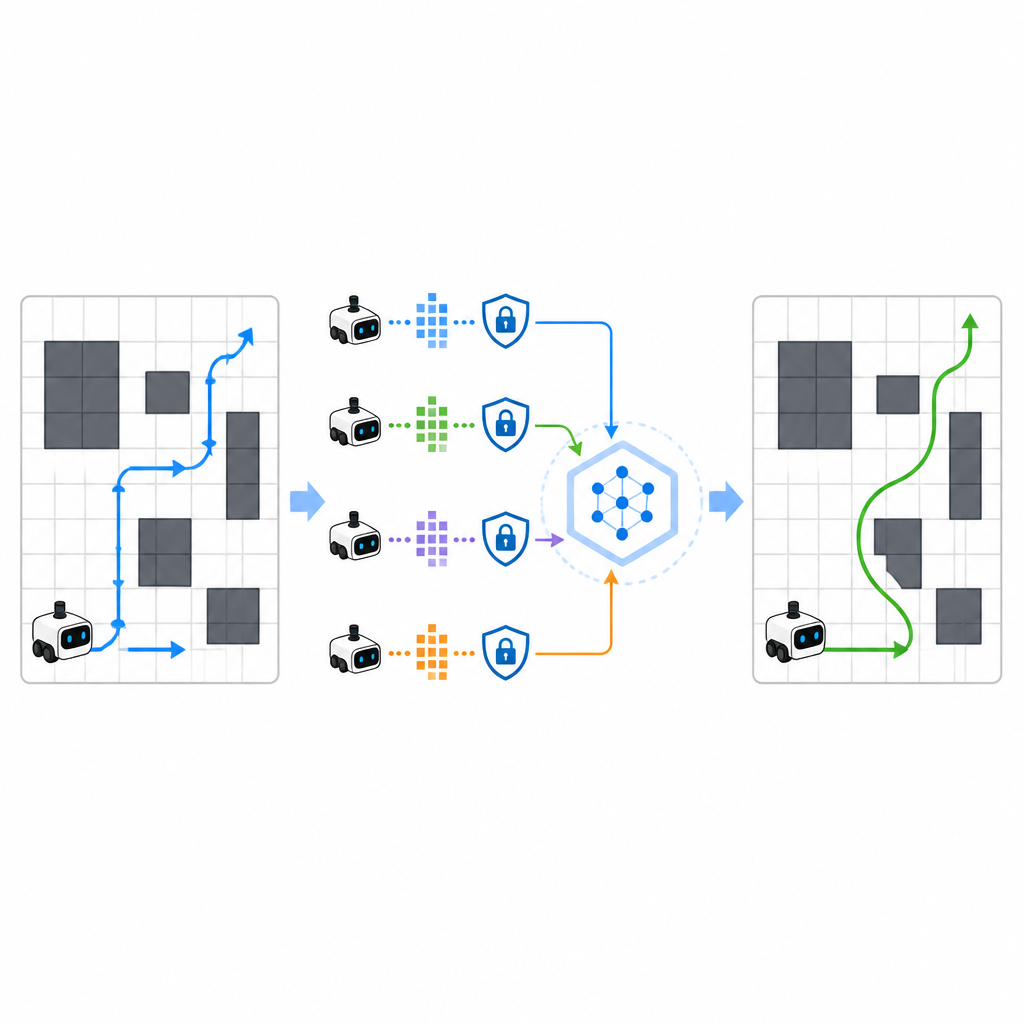
Saldırganları Bilgi Eksikliğinde Bırakmak
Çalışma ayrıca çerçevedeki yaklaşımın eğitim sırasında hangi yolların kullanıldığını çıkarım yapmaya veya hassas trajeleri yeniden oluşturmak isteyen saldırganlara karşı ne kadar dayanıklı olduğunu da inceledi. Standart gizlilik saldırılarını test ederek yazarlar, SPHTRLM’nin bu tür saldırıların başarı oranını yaklaşık yüzde beşin altında, yani rasgele tahmine yakın bir seviyede tuttuğunu buldu. Bu koruma, şifrelenmiş güncellemelerin, sınırlı bilgi paylaşımının ve öğrenme sinyallerine kasıtlı olarak eklenen gürültünün kombinasyonundan kaynaklandı. Aynı zamanda navigasyon performansı güçlü kaldı, bu da robotun öğrenme yeteneğini sakatlamadan gizliliğin korunmasının mümkün olduğunu gösteriyor.
Gerçek Dünyadaki Robotlar İçin Anlamı
Uzman olmayanlar için ana mesaj şudur: Robotlar artık değişen ortamlarda güvenli ve verimli hareket edecek şekilde eğitilebilir ve aynı zamanda algıladıkları ve karar verdikleri her şeyi açığa çıkarmak zorunda kalmazlar. SPHTRLM, öğrenmeyi, ayarlamayı ve gizliliği gerçekçi hesaplama sınırları içinde birleştiren tek bir tasarımda nasıl örülebileceğini gösteriyor. Bu, gizliliğe duyarlı depo robotlarını, hastanelerdeki servis robotlarını veya hassas tesislerdeki denetim dronlarını, karşılaştıkları bilgileri koruyarak anında uyum sağlama yeteneğine bir adım daha yaklaştırıyor.
Atıf: Dewangan, R.R., Thombre, D., Parganiha, V. et al. SPHTRLM: secure and privacy-preserving hyperparameter-tuned reinforcement learning method for robot path finding in dynamic environments. Sci Rep 16, 16114 (2026). https://doi.org/10.1038/s41598-026-48141-x
Anahtar kelimeler: robot navigasyonu, pekiştirmeli öğrenme, gizliliği koruyan yapay zeka, federe öğrenme, dinamik ortamlar