Clear Sky Science · fr
SPHTRLM : méthode d'apprentissage par renforcement réglée pour la confidentialité et la sécurité dans la recherche de trajectoire robotique en environnements dynamiques
Des robots qui apprennent en mouvement
Imaginez un robot d'entrepôt qui doit se faufiler entre des piles de cartons en mouvement tout en protégeant les données des clients. Cet article présente une nouvelle méthode permettant à de tels robots d'apprendre de meilleurs trajets dans des espaces encombrés et changeants, tout en préservant les informations sensibles qu'ils rencontrent. Le travail montre comment combiner apprentissage intelligent, navigation sûre et forte protection de la vie privée dans un système pratique.
Pourquoi les robots mobiles font face à des choix difficiles
Les robots qui se déplacent doivent prendre des décisions en continu : où aller ensuite, quel obstacle éviter, et comment atteindre un objectif rapidement sans heurter quoi que ce soit. Les méthodes de planification classiques fonctionnent bien lorsque l'environnement change peu et est cartographié à l'avance, mais peinent dès que des personnes, des chariots ou d'autres robots se déplacent de façon imprévisible. L'apprentissage par renforcement moderne permet à un robot de s'améliorer par essais et erreurs, mais exige en général beaucoup d'ajustements et un accès ouvert à l'ensemble des données collectées. Cela crée deux problèmes majeurs pour des déploiements réels : l'apprentissage peut devenir instable dans des contextes très changeants, et les données peuvent révéler des informations sensibles sur des lieux, des personnes ou des opérations.
Un système unifié pour un apprentissage sûr et privé
Les auteurs proposent un cadre appelé SPHTRLM qui aborde simultanément la qualité de navigation, la stabilité de l'apprentissage et la confidentialité. Dans leur configuration, le robot évolue sur une grille, choisissant des pas simples vers le haut, le bas, la gauche ou la droite tandis que les positions des obstacles et des objectifs évoluent au fil du temps. Le système récompense le robot lorsqu'il se rapproche de son but, le pénalise en cas de collision, et l'encourage modérément à explorer de nouveaux itinéraires plutôt que de s'enfermer dans des habitudes. De manière cruciale, ces récompenses ne sont pas fixes mais s'adaptent en fonction de l'encombrement de l'espace et de l'efficacité du déplacement du robot, ce qui l'aide à rester performant lorsque les conditions changent.
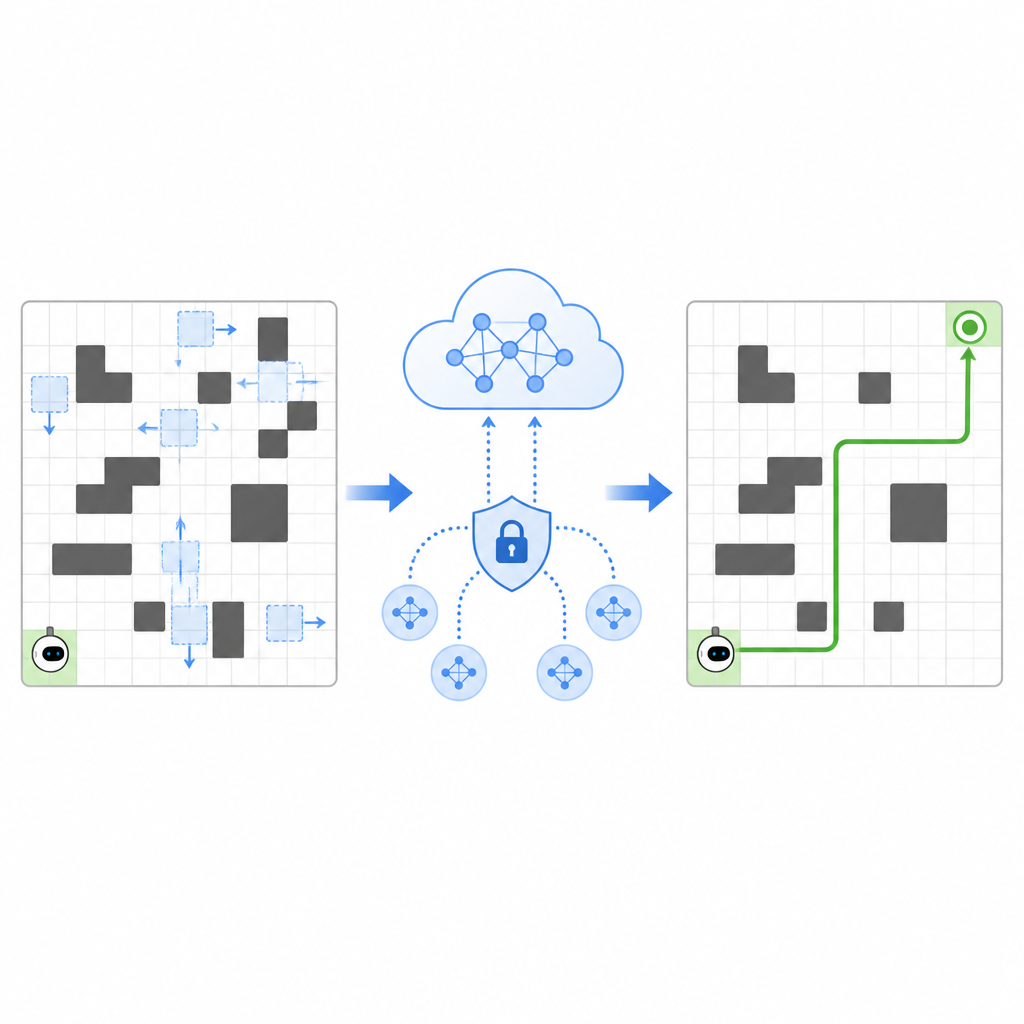
Partager l'expérience sans dévoiler les secrets
Pour accélérer l'apprentissage, SPHTRLM permet à plusieurs robots ou agents d'apprendre en parallèle et de partager leurs découvertes. Plutôt que d'envoyer des cartes brutes ou des trajectoires détaillées vers un serveur central, chaque robot conserve son expérience localement et envoie périodiquement des résumés compacts et chiffrés de ce qu'il a appris. Des techniques empruntées à l'apprentissage fédéré permettent de combiner ces résumés en une stratégie commune plus robuste, puis de renvoyer le plan amélioré aux robots. Un bruit additionnel est introduit de manière contrôlée pour masquer des détails fins, et un chiffrement soigneusement choisi garantit que, même en cas d'interception des mises à jour, il est difficile de reconstruire où les robots sont passés ou ce qu'ils ont observé.
Apprentissage plus rapide, trajets plus courts, moins de collisions
Dans des expériences informatiques sur une grille de dix par dix remplie d'obstacles mobiles, SPHTRLM a été comparé à plusieurs méthodes d'apprentissage populaires. Il a atteint ses objectifs dans environ quatre-vingt-quinze pour cent des essais, dépassant les approches standards de Q-learning et les baselines d'apprentissage profond par renforcement. Les trajets découverts étaient en moyenne environ vingt à vingt-cinq pour cent plus courts, ce qui signifie que le robot perdait moins de temps à errer. Il a également convergé vers un comportement performant environ un tiers plus vite, et son taux de collision est tombé à un niveau très bas même lorsque la grille était fortement encombrée. Malgré les étapes supplémentaires nécessaires pour protéger les données, le temps moyen de décision est resté de l'ordre de quelques centièmes de seconde, ce qui convient au contrôle en temps réel.
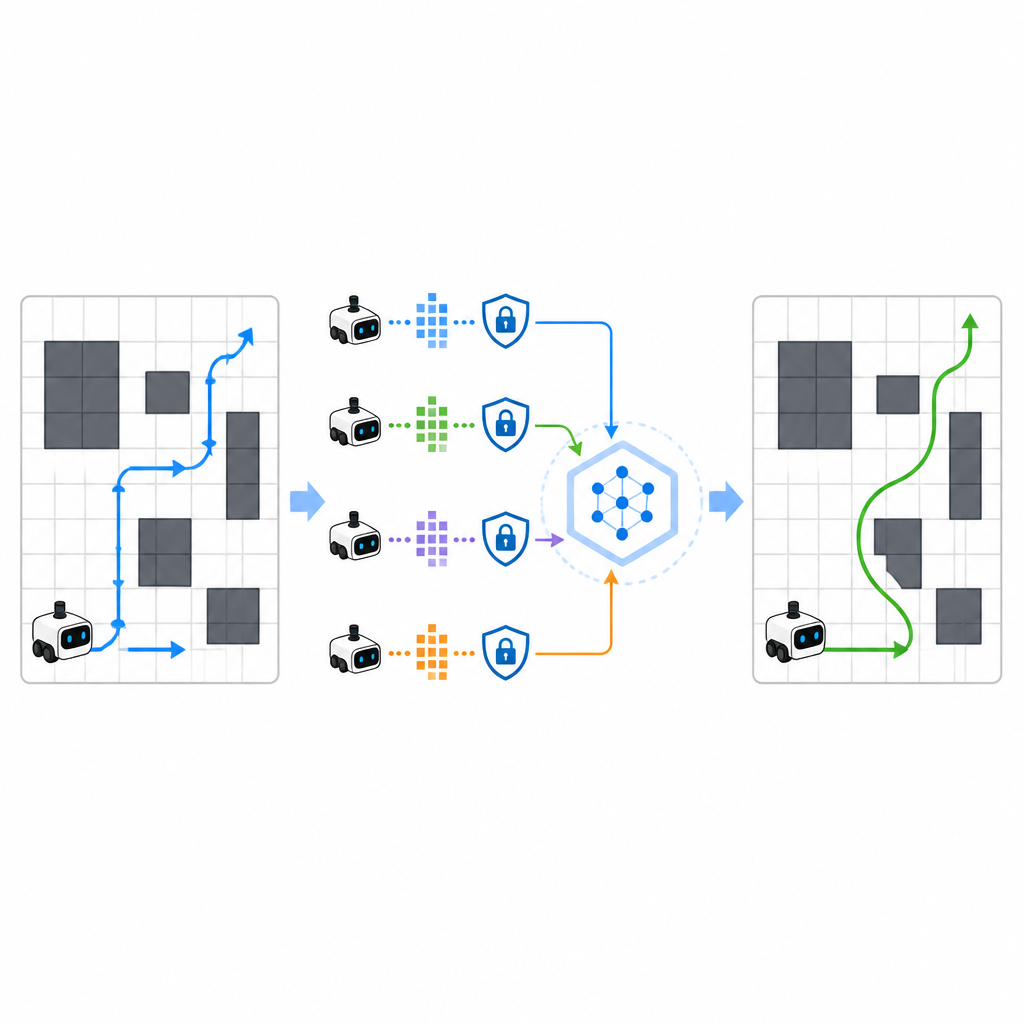
Maintenir les attaquants dans l'ignorance
L'étude a aussi évalué la résistance du cadre face à des attaquants cherchant à inférer quelles routes ont été utilisées durant l'entraînement ou à reconstruire des trajectoires sensibles. En testant des attaques de confidentialité standard, les auteurs ont constaté que SPHTRLM maintenait le taux de succès de telles attaques en dessous de cinq pour cent, proche d'un tirage au sort. Cette protection provient de la combinaison d'updates chiffrés, du partage d'information limité et du bruit délibéré dans les signaux d'apprentissage. Parallèlement, les performances de navigation sont restées élevées, ce qui suggère qu'il est possible de protéger la vie privée sans handicaper la capacité du robot à apprendre.
Ce que cela signifie pour les robots du monde réel
Pour les non-spécialistes, le message clé est que les robots peuvent désormais être entraînés à se déplacer de manière sûre et efficace dans des environnements changeants sans exposer tout ce qu'ils perçoivent et décident. SPHTRLM montre comment tisser ensemble apprentissage, réglage et confidentialité dans une conception unique qui tient dans des limites informatiques réalistes. Cela rapproche des robots d'entrepôt respectueux de la vie privée, des robots de service dans les hôpitaux ou des drones d'inspection dans des installations sensibles d'une adoption quotidienne, où ils peuvent s'adapter sur le vif tout en respectant les informations qu'ils rencontrent.
Citation: Dewangan, R.R., Thombre, D., Parganiha, V. et al. SPHTRLM: secure and privacy-preserving hyperparameter-tuned reinforcement learning method for robot path finding in dynamic environments. Sci Rep 16, 16114 (2026). https://doi.org/10.1038/s41598-026-48141-x
Mots-clés: navigation robotique, apprentissage par renforcement, IA respectueuse de la vie privée, apprentissage fédéré, environnements dynamiques