Clear Sky Science · zh
在交通环境中比较 U-Net 与 DeepLabV3+ 语义分割性能的分析
为何更清晰的街景很重要
现代汽车与城市摄像头越来越依赖数字视觉来理解道路上的情况。然而真实街道远非实验室中那些清晰照片:图像可能昏暗、模糊、噪声多或分辨率低。本研究探讨如何清理这些粗糙的交通图像,并教会计算机可靠地识别道路、车辆与行人,从而帮助未来的驾驶辅助系统与交通监测工具在复杂的现实环境中做出更安全的决策。

从粗糙快照到更清晰的场景
研究者关注一种称为场景理解的任务,即为图像中的每个像素分配类别,使路面、人行道、汽车、公交车与行人等被划分为有意义的区域。普通系统在图像昏暗、抖动或颗粒感强时常常失灵,而这恰恰是做出安全决策时最关键的时刻。为了解决这一问题,团队提出了一个先增强图像再进行详细分析的流程,目标是在摄像源远非完美时仍能保持高性能。
图像处理的三步路径
该流程有三个主要阶段:锐化、像素标注与目标识别。首先,基于先进增强方法的超分辨率模块提升每帧的分辨率与对比度,使车道线等细纹理和小型车辆的轮廓更清晰。接着,两个专门工具 U-Net 与 DeepLabV3+ 对增强后的图像生成像素级地图,将每个点着色为道路、行人、车辆或背景。最后,名为 YOLOv8x 的目标检测器使用边界框验证标注区域是否对应可信的汽车、行人和交通元素,并衡量系统在实践中的效果。
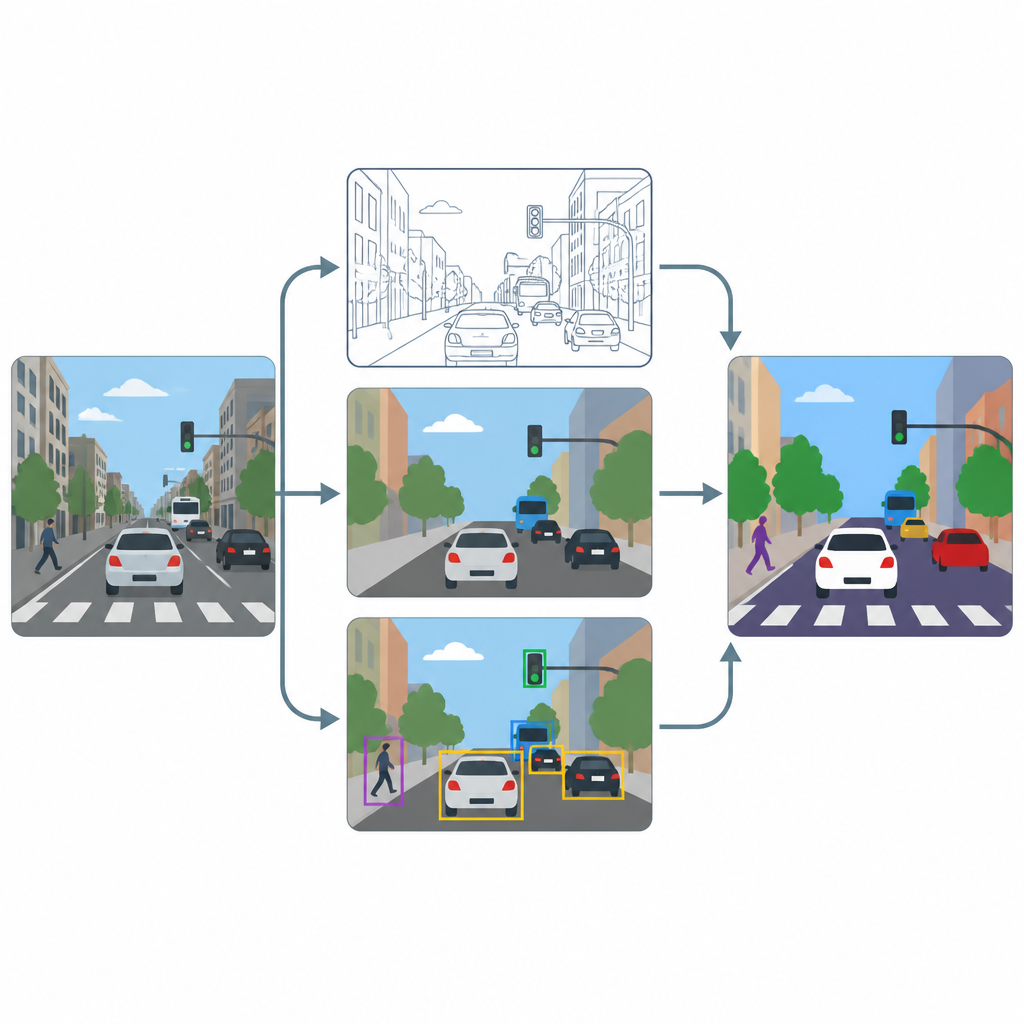
在拥挤城市场景上的测试
为评估该方法的效果,作者在广泛使用的 COCO 图像集合的一个子集中进行训练与测试,重点是包含街道、车辆、交通信号与行人的场景。他们有意将图像调整为常见摄像头帧的中等分辨率 640 x 640 像素,并采用强数据增强,使模型见到光照、模糊与视角的多种变化。作者比较了有无锐化步骤时的表现,并同时跟踪像素级评分(反映区域轮廓的准确性)与目标级评分(反映单个道路使用者的检测效果)。
两种视觉工具的比较
U-Net 与 DeepLabV3+ 在任务中各有优势。U-Net 借助不同尺度间的强连接,倾向于保留物体清晰的边界,在图像质量指标上表现尤为突出,包括若干样本的峰值信噪比超过 40 dB 以及结构相似性接近 1.0。DeepLabV3+ 更善于捕捉宏观上下文,例如车辆簇与路面的关系,在某些场景上往往取得略高的像素重叠率与检测分数。在多次试验中,增强步骤持续提升了这两类指标,表明更清晰的输入能带来更可靠的交通场景理解。
在恶劣路况下的局限与未来方向
作者也指出了系统的局限性。系统是在静态图像上测试的,而非实时视频;在条件极端恶劣时(如浓雾或严重运动模糊),即便是超分辨率也无法恢复足够细节。额外的锐化阶段还会增加计算负担,这对车载低功耗设备来说可能是个挑战。未来的工作将着眼于更轻量的模型、更好地处理夜间与天气影响,并扩展到包含跟踪的完整视频流,力求将这种细粒度的场景理解带到实时智能交通的需求中。
这对日常出行意味着什么
简单来说,研究表明在要求计算机进行解读之前先让它看到更清晰的道路,会让其判断更可靠。通过将图像增强与两种互补的像素标注工具以及一个目标检测器相结合,所提框架改善了系统在繁忙交通场景中区分道路、车辆与行人的能力。尽管尚无法应对所有恶劣条件或硬件限制,这一方法仍使机器视觉更接近处理真实街道所提供的不完美图像的能力。
引用: Ramyashree, Utsavi, S.R., Raghavendra, S. et al. Comparative performance analysis of U-Net and DeepLabV3+ for semantic segmentation in traffic environments. Sci Rep 16, 15614 (2026). https://doi.org/10.1038/s41598-026-46740-2
关键词: 语义分割, 交通场景, 超分辨率, U-Net, DeepLabV3+