Clear Sky Science · fr
Analyse comparative des performances de U-Net et DeepLabV3+ pour la segmentation sémantique en environnement routier
Pourquoi des vues de rue plus nettes sont importantes
Les voitures modernes et les caméras urbaines s’appuient de plus en plus sur la vision numérique pour comprendre ce qui se passe sur la route. Pourtant, les rues réelles ressemblent rarement aux photos nettes des laboratoires : les images peuvent être sombres, floues, bruitées ou de faible résolution. Cette étude explore comment nettoyer ces images de trafic abîmées puis apprendre aux ordinateurs à repérer de manière fiable routes, véhicules et piétons, afin d’aider les futurs systèmes d’assistance à la conduite et les outils de surveillance du trafic à prendre des décisions plus sûres dans des conditions réelles et désordonnées.

Des instantanés bruts à des scènes plus nettes
Les chercheurs se concentrent sur une tâche appelée compréhension de scène, où un ordinateur attribue une catégorie à chaque pixel d’une image afin que chaussées, trottoirs, voitures, bus et piétons soient séparés en régions signifiantes. Les systèmes ordinaires échouent souvent lorsque l’image est sombre, tremblante ou granuleuse, c’est précisément dans ces situations que des décisions sûres sont les plus cruciales. Pour y remédier, l’équipe propose un pipeline qui améliore d’abord l’image puis réalise une analyse détaillée de son contenu, visant à maintenir des performances élevées même lorsque le flux caméra est loin d’être parfait.
Un parcours en trois étapes à travers l’image
Le pipeline comporte trois étapes principales : amélioration, étiquetage pixel par pixel et détection d’objets. D’abord, un module de super-résolution basé sur une méthode d’amélioration avancée augmente la résolution et le contraste de chaque image afin que les textures fines, comme les marquages au sol ou les contours de petits véhicules, deviennent plus lisibles. Ensuite, deux outils spécialisés, U-Net et DeepLabV3+, prennent l’image améliorée et produisent des cartes au niveau pixel colorant chaque point comme route, piéton, véhicule ou arrière-plan. Enfin, un détecteur d’objets nommé YOLOv8x utilise des boîtes englobantes pour vérifier que les régions étiquetées correspondent bien à des voitures, des personnes et des éléments de trafic plausibles et pour mesurer l’efficacité du système en pratique.
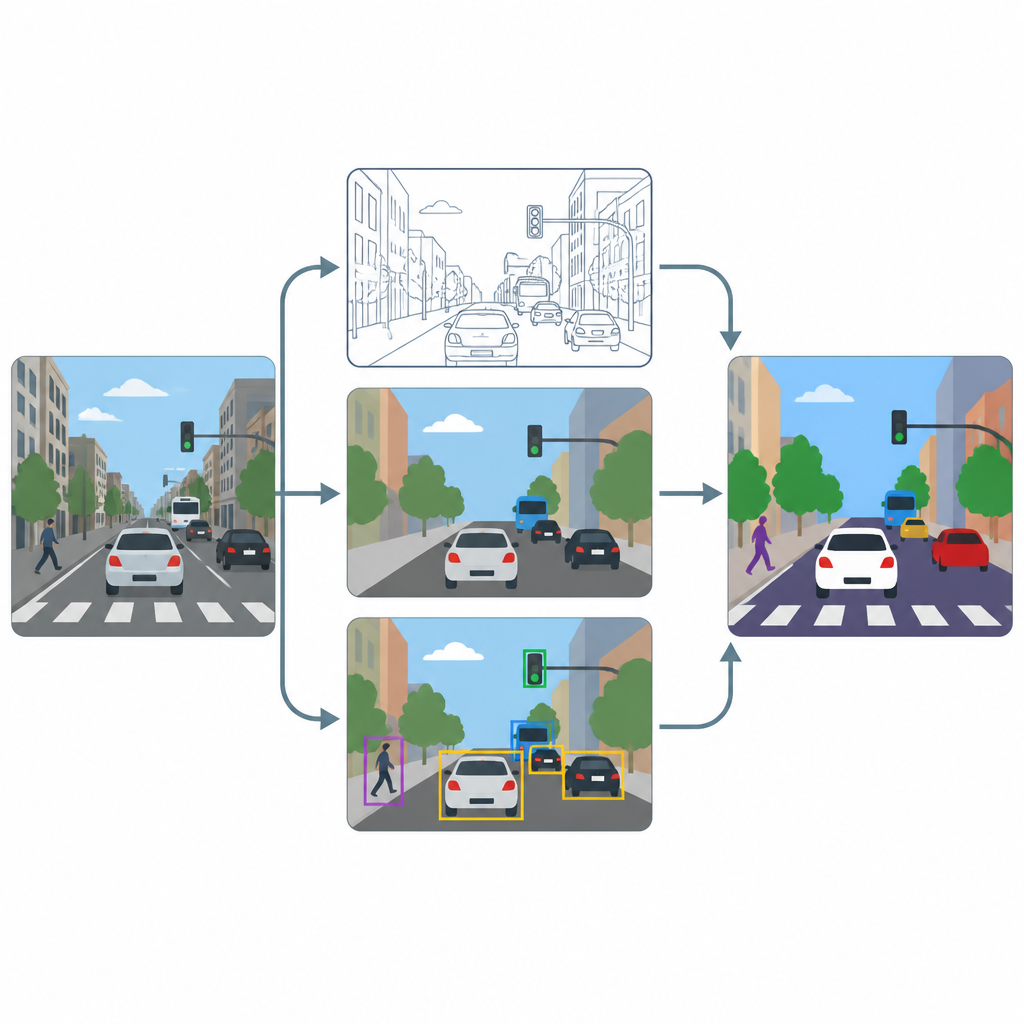
Tests sur des scènes urbaines encombrées
Pour évaluer l’efficacité de ce dispositif, les auteurs l’entraînent et le testent sur un sous-ensemble de la collection d’images COCO largement utilisée, en se concentrant sur des scènes comportant rues, véhicules, signaux et piétons. Ils redimensionnent volontairement les images à un format modeste de 640 sur 640 pixels pour imiter les flux de caméras courants, puis appliquent une forte augmentation de données afin que les modèles voient de nombreuses variations d’éclairage, de flou et de point de vue. Ils comparent les performances avec et sans l’étape d’amélioration et suivent à la fois des scores basés sur les pixels, qui reflètent la qualité du délimitation des régions, et des scores basés sur les objets, qui mesurent la détection des usagers individuels.
Comment les deux outils de vision se comparent
U-Net et DeepLabV3+ apportent des forces différentes à la tâche. U-Net, avec ses fortes connexions entre détails d’image à différentes échelles, a tendance à préserver des bordures nettes autour des objets et obtient des mesures de qualité d’image très élevées, notamment des rapports signal sur bruit de crête supérieurs à 40 décibels et des valeurs de similarité structurelle proches de 1,0 sur plusieurs échantillons. DeepLabV3+ est plus performant pour saisir le contexte large, par exemple la relation entre des groupes de véhicules et les routes, et obtient souvent des scores d’intersection pixelique et de détection légèrement supérieurs sur certaines scènes. Sur de nombreuses expériences, l’étape d’amélioration augmente systématiquement ces deux familles de mesures, indiquant que des entrées plus nettes se traduisent par une compréhension du trafic plus fiable.
Limites sur les conditions extrêmes et voies futures
Les auteurs notent aussi des limites. Leur système est testé sur des images fixes, pas sur de la vidéo en direct, et il peine lorsque les conditions sont extrêmement mauvaises, comme un brouillard dense ou un flou de mouvement sévère, où même la super-résolution ne peut pas récupérer suffisamment de détails. L’étape d’amélioration supplémentaire augmente aussi la charge de calcul, ce qui peut poser problème pour les dispositifs à faible consommation embarqués dans les véhicules. Les travaux futurs viseront des modèles plus légers, une meilleure gestion de la nuit et des effets météorologiques, et une extension aux flux vidéo complets avec suivi, pour rapprocher ce type de compréhension fine des exigences du transport intelligent en temps réel.
Ce que cela signifie pour les déplacements quotidiens
En termes simples, l’étude montre que donner aux ordinateurs une vue plus propre de la route avant de leur demander de l’interpréter peut rendre leurs jugements plus fiables. En combinant l’amélioration d’image avec deux outils complémentaires d’étiquetage pixel et un détecteur d’objets, le cadre proposé améliore la capacité d’un système à séparer routes, voitures et personnes dans des scènes de trafic chargées. Bien que la méthode ne soit pas encore prête à gérer toutes les conditions extrêmes ou contraintes matérielles, elle rapproche la vision machine de la capacité à traiter les images imparfaites que délivrent les rues réelles.
Citation: Ramyashree, Utsavi, S.R., Raghavendra, S. et al. Comparative performance analysis of U-Net and DeepLabV3+ for semantic segmentation in traffic environments. Sci Rep 16, 15614 (2026). https://doi.org/10.1038/s41598-026-46740-2
Mots-clés: segmentation sémantique, scènes de trafic, super-résolution, U-Net, DeepLabV3+