Clear Sky Science · pt
Análise comparativa de desempenho do U-Net e DeepLabV3+ para segmentação semântica em ambientes de tráfego
Por que vistas de rua mais nítidas importam
Carros modernos e câmeras urbanas dependem cada vez mais da visão digital para entender o que acontece na via. No entanto, ruas reais raramente se parecem com as fotos nítidas dos laboratórios: as imagens podem estar escuras, borradas, ruidosas ou de baixa resolução. Este estudo explora como limpar essas imagens de tráfego degradadas e depois ensinar computadores a identificar de forma confiável vias, veículos e pedestres, ajudando futuros sistemas de assistência ao motorista e ferramentas de monitoramento de tráfego a tomar decisões mais seguras em condições reais e desafiadoras.

De instantâneos ruins a cenas mais claras
Os pesquisadores focam em uma tarefa chamada entendimento de cena, em que um computador atribui uma categoria a cada pixel da imagem para que superfícies de estrada, calçadas, carros, ônibus e pessoas fiquem separados em regiões significativas. Sistemas comuns frequentemente falham quando a imagem está escura, tremida ou granulada — exatamente quando decisões seguras são mais críticas. Para enfrentar isso, a equipe propõe um pipeline que primeiro melhora a imagem e depois realiza uma análise detalhada de seu conteúdo, buscando manter alto desempenho mesmo quando o fluxo de câmera está longe do ideal.
Caminho em três etapas pela imagem
O pipeline tem três estágios principais: nitidez, rotulagem por pixel e detecção de objetos. Primeiro, um módulo de super-resolução baseado em um método avançado de realce aumenta a resolução e o contraste de cada quadro para que texturas finas, como marcações de faixa ou contornos de pequenos veículos, fiquem mais claras. Em seguida, duas ferramentas especializadas, U-Net e DeepLabV3+, recebem a imagem aprimorada e produzem mapas ao nível de pixel que colorizam cada ponto como via, pedestre, veículo ou fundo. Por fim, um detector de objetos chamado YOLOv8x usa caixas delimitadoras para verificar se as regiões rotuladas correspondem a carros, pessoas e elementos de trânsito plausíveis e para medir quão bem o sistema funcionaria na prática.
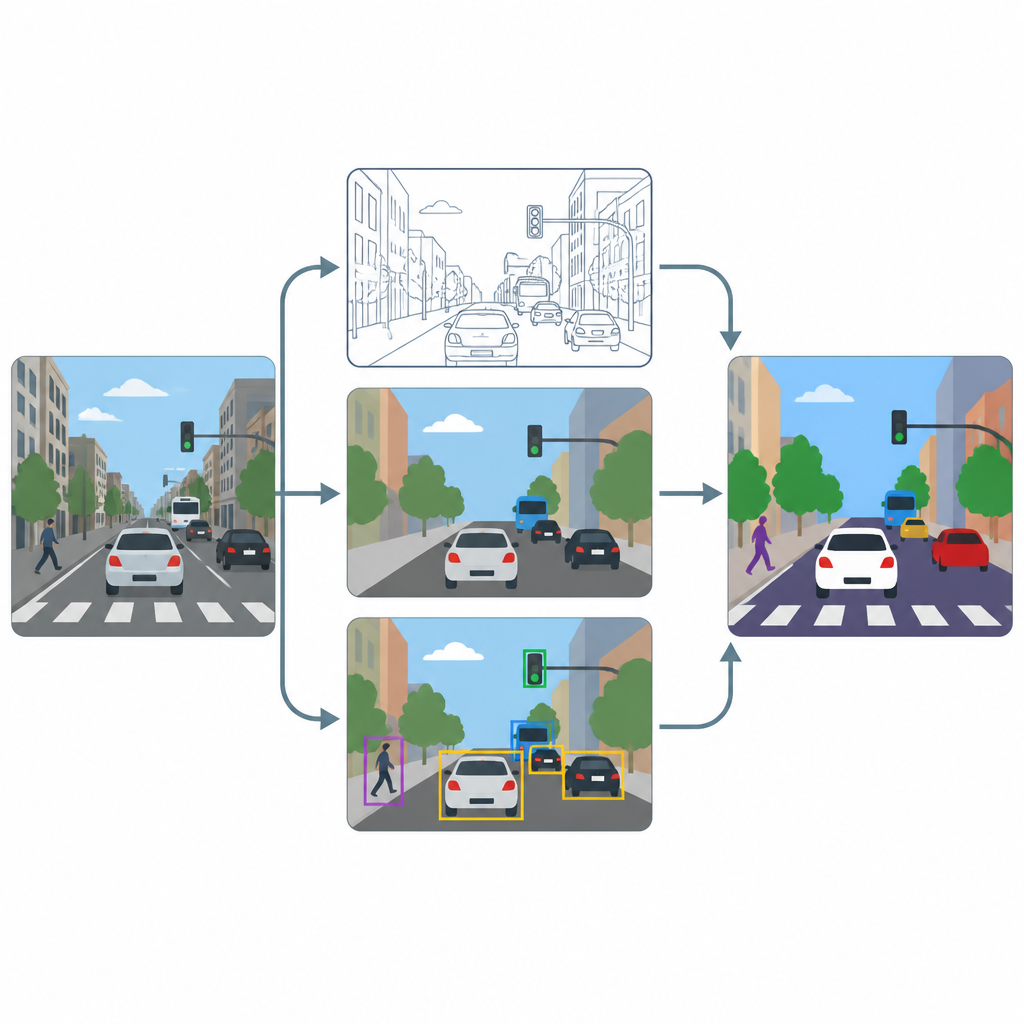
Testando em cenas urbanas lotadas
Para avaliar o desempenho dessa configuração, os autores treinam e testam o sistema em um subconjunto da amplamente utilizada coleção de imagens COCO, focando em cenas com ruas, veículos, sinais e pedestres. Eles redimensionam propositalmente as imagens para um modesto 640 por 640 pixels para mimetizar feeds de câmeras comuns, então usam forte aumento de dados para que os modelos vejam muitas variações de iluminação, desfoque e ponto de vista. Comparam o desempenho com e sem a etapa de realce e acompanham tanto métricas baseadas em pixels, que refletem a precisão do contorno das regiões, quanto métricas baseadas em objetos, que refletem quão bem usuários da via individuais são detectados.
Como as duas ferramentas de visão se comparam
U-Net e DeepLabV3+ trazem forças diferentes para a tarefa. U-Net, com suas conexões robustas entre detalhes da imagem em diferentes escalas, tende a preservar bordas nítidas ao redor dos objetos e alcança medidas de qualidade de imagem muito altas, incluindo razão sinal-ruído de pico acima de 40 decibéis e valores de similaridade estrutural próximos de 1,0 em várias amostras. DeepLabV3+ é melhor em capturar contexto amplo, como a relação entre aglomerados de veículos e vias, e frequentemente obtém sobreposições de pixels e pontuações de detecção ligeiramente maiores em algumas cenas. Em muitos experimentos, a etapa de realce eleva consistentemente ambos os conjuntos de métricas, indicando que entradas mais claras se traduzem em um entendimento de tráfego mais confiável.
Limites em estradas severas e próximos passos
Os autores também observam limites. O sistema foi testado em imagens estáticas, não em vídeo ao vivo, e sofre quando as condições são extremamente ruins, como neblina densa ou desfoque de movimento severo, onde mesmo a super-resolução não consegue recuperar detalhes suficientes. A etapa extra de realce também aumenta a carga computacional, o que pode ser um desafio para dispositivos de baixa potência dentro de veículos. Trabalhos futuros devem buscar modelos mais leves, melhor tratamento de efeitos noturnos e climáticos e extensão para fluxos de vídeo completos com rastreamento, visando aproximar esse tipo de entendimento de cena detalhado das demandas do transporte inteligente em tempo real.
O que isso significa para o trânsito do dia a dia
Em termos simples, o estudo mostra que dar aos computadores uma visão mais limpa da via antes de pedir que a interpretem pode tornar seus julgamentos mais confiáveis. Ao combinar aprimoramento de imagem com duas ferramentas complementares de rotulagem por pixel e um detector de objetos, o framework proposto melhora a capacidade de separar vias, carros e pessoas em cenas de tráfego movimentadas. Embora ainda não esteja pronto para lidar com todas as condições severas ou restrições de hardware, essa abordagem aproxima a visão computacional da capacidade de conviver com as imagens imperfeitas que as ruas reais entregam.
Citação: Ramyashree, Utsavi, S.R., Raghavendra, S. et al. Comparative performance analysis of U-Net and DeepLabV3+ for semantic segmentation in traffic environments. Sci Rep 16, 15614 (2026). https://doi.org/10.1038/s41598-026-46740-2
Palavras-chave: segmentação semântica, cenas de tráfego, super-resolução, U-Net, DeepLabV3+