Clear Sky Science · ru
Сравнительный анализ производительности U-Net и DeepLabV3+ для семантической сегментации в дорожных условиях
Почему важны более чёткие уличные виды
Современные автомобили и городские камеры всё больше полагаются на цифровое зрение, чтобы понимать происходящее на дороге. Однако настоящие улицы редко выглядят как резкие фотографии из лабораторий: изображения могут быть тёмными, размытыми, зашумлёнными или иметь низкое разрешение. В этом исследовании рассматриваются методы очистки таких «сыровых» дорожных изображений и обучения компьютеров надёжному распознаванию дорог, транспортных средств и пешеходов, что поможет системам помощи водителю и инструментам мониторинга движения принимать более безопасные решения в реальных, сложных условиях.

От грубых снимков к более ясным сценам
Исследователи сосредоточены на задаче понимания сцены, когда компьютер присваивает категорию каждому пикселю изображения, чтобы поверхности дорог, тротуары, автомобили, автобусы и люди были разделены на осмысленные области. Обычные системы часто дают сбой, когда изображение тусклое, дрожит или зернистое — как раз тогда, когда важны безопасные решения. Чтобы справиться с этим, команда предлагает конвейер, который сначала улучшает изображение, а затем выполняет подробный анализ его содержимого, стремясь сохранить высокую точность даже при далеко не идеальной подаче с камеры.
Трёхэтапный путь через изображение
Конвейер состоит из трёх основных этапов: повышение чёткости, пометка пикселей и обнаружение объектов. Сначала модуль супер-разрешения на основе продвинутого метода улучшения повышает разрешение и контраст каждого кадра, чтобы тонкие текстуры, такие как разметка полос или контуры мелких транспортных средств, становились более различимыми. Затем два специализированных инструмента, U-Net и DeepLabV3+, берут улучшенное изображение и формируют картографию на уровне пикселей, окрашивая каждый пиксель как дорогу, пешехода, транспортное средство или фон. Наконец, детектор объектов YOLOv8x использует ограничивающие прямоугольники, чтобы подтвердить, что размеченные области действительно соответствуют реалистичным автомобилям, людям и элементам дорожной обстановки, и чтобы оценить, насколько система работала бы на практике.
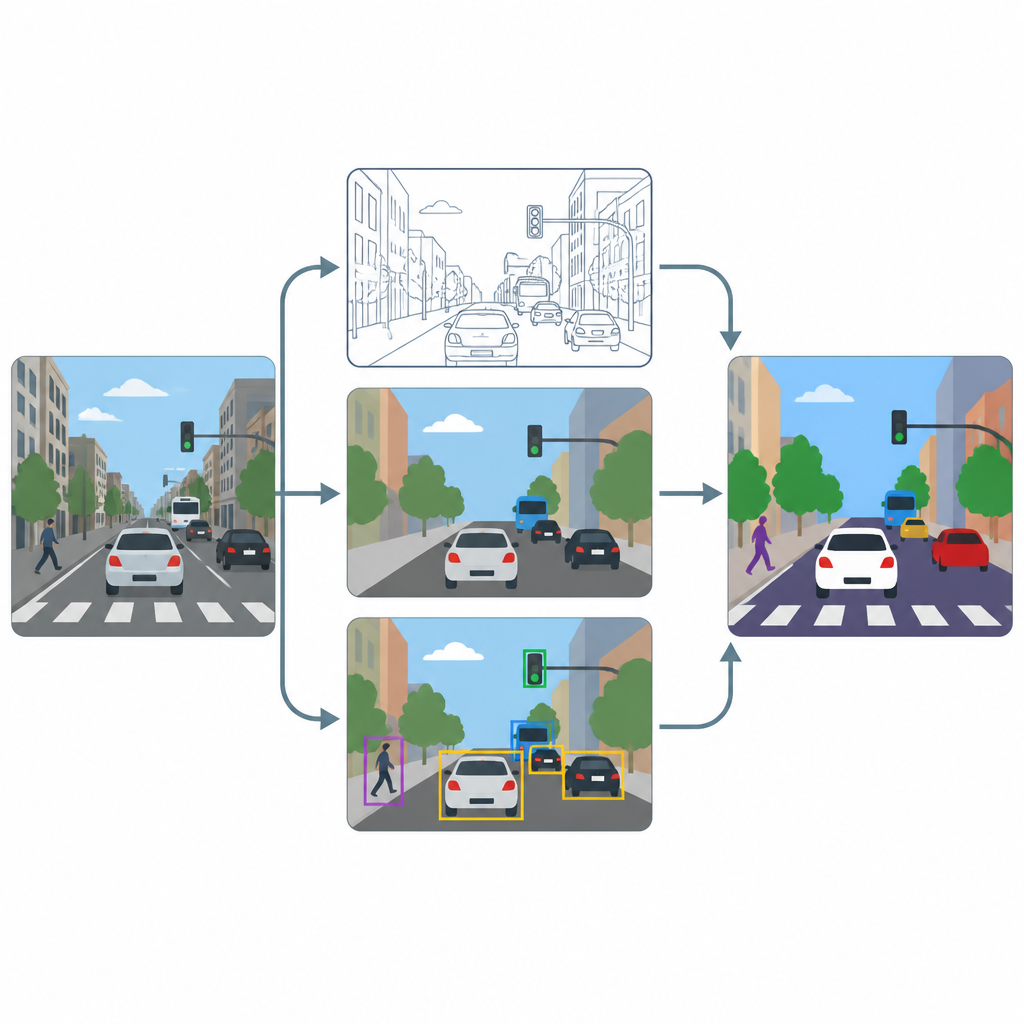
Тестирование на оживлённых городских сценах
Чтобы оценить работоспособность этой схемы, авторы обучают и тестируют её на подмножестве широко используемой коллекции изображений COCO, фокусируясь на сценах с улицами, транспортом, светофорами и пешеходами. Они сознательно изменяют размер изображений до скромных 640 на 640 пикселей, чтобы имитировать распространённые потоки с камер, затем применяют серьёзное увеличение данных, чтобы модели увидели множество вариаций освещения, размытия и точек зрения. Сравнивают производительность с этапом повышения чёткости и без него, отслеживая как метрики на уровне пикселей, отражающие точность контуров областей, так и метрики на уровне объектов, показывающие, насколько хорошо обнаруживаются отдельные участники дорожного движения.
Сравнение двух инструментов компьютерного зрения
U-Net и DeepLabV3+ вносят разные сильные стороны в задачу. U-Net, с его мощными связями между деталями изображения на разных масштабах, склонен сохранять чёткие границы вокруг объектов и достигает очень высоких показателей качества изображения, включая отношение сигнал/шум выше 40 децибел и значения структурного сходства близкие к 1.0 в нескольких образцах. DeepLabV3+ лучше улавливает широкий контекст, например, взаимосвязь между группами транспортных средств и дорогами, и часто показывает слегка лучшие показатели перекрытия пикселей и обнаружения в некоторых сценах. Во множестве испытаний этап улучшения последовательно повышает оба типа показателей, указывая на то, что более чистые входные данные приводят к более надёжному пониманию дорожной обстановки.
Ограничения в жёстких условиях и дальнейшие шаги
Авторы также отмечают ограничения. Их система протестирована на статичных изображениях, а не на видеопотоках, и она испытывает трудности при крайне тяжёлых условиях, таких как плотный туман или сильное движение, когда даже супер-разрешение не может восстановить достаточно деталей. Дополнительный этап повышения чёткости также увеличивает вычислительную нагрузку, что может стать проблемой для энергонезависимых устройств в транспортных средствах. В будущем планируется работа над более лёгкими моделями, лучшей обработкой ночных и погодных эффектов, а также расширение на полноценные видеопотоки с отслеживанием, чтобы приблизить такое детальное понимание сцены к требованиям реального времени в интеллектуальном транспорте.
Что это значит для повседневных поездок
Проще говоря, исследование показывает, что предоставление компьютерам более чистого вида дороги перед её интерпретацией может сделать их суждения более надёжными. Сочетая улучшение изображений с двумя дополняющими друг друга инструментами пометки пикселей и детектором объектов, предложенная схема повышает способность системы разделять дороги, автомобили и людей в оживлённых дорожных сценах. Хотя подход ещё не готов справляться со всеми экстремальными условиями или ограничениями по оборудованию, он приближает машинное зрение к умению работать с несовершенными изображениями, которые дают реальные улицы.
Цитирование: Ramyashree, Utsavi, S.R., Raghavendra, S. et al. Comparative performance analysis of U-Net and DeepLabV3+ for semantic segmentation in traffic environments. Sci Rep 16, 15614 (2026). https://doi.org/10.1038/s41598-026-46740-2
Ключевые слова: семантическая сегментация, дорожные сцены, супер-разрешение, U-Net, DeepLabV3+