Clear Sky Science · es
Análisis comparativo del rendimiento de U-Net y DeepLabV3+ para segmentación semántica en entornos de tráfico
Por qué importan vistas callejeras más nítidas
Los automóviles modernos y las cámaras urbanas dependen cada vez más de la visión digital para entender lo que ocurre en la vía. Sin embargo, las calles reales rara vez se parecen a las fotos nítidas de los laboratorios: las imágenes pueden estar oscuras, borrosas, ruidosas o tener baja resolución. Este estudio explora cómo limpiar esas imágenes de tráfico degradadas y luego enseñar a los ordenadores a identificar de forma fiable calzadas, vehículos y peatones, ayudando a futuros sistemas de asistencia al conductor y herramientas de monitorización del tráfico a tomar decisiones más seguras en condiciones reales y desordenadas.

De instantáneas deficientes a escenas más claras
Los investigadores se centran en una tarea llamada entendimiento de escenas, en la que un ordenador asigna una categoría a cada píxel de una imagen para separar superficies de calzada, aceras, coches, autobuses y peatones en regiones con significado. Los sistemas ordinarios suelen fallar cuando la imagen está tenue, movida o granulada, que es exactamente cuando las decisiones seguras son más críticas. Para abordar esto, el equipo propone una canalización que primero mejora la imagen y luego realiza un análisis detallado de su contenido, con el objetivo de mantener un alto rendimiento incluso cuando la señal de la cámara está lejos de ser perfecta.
Un camino de tres pasos a través de la imagen
La canalización tiene tres etapas principales: agudizado, etiquetado de píxeles y detección de objetos. Primero, un módulo de superresolución basado en un método avanzado de mejora aumenta la resolución y el contraste de cada fotograma para que texturas finas, como marcas de carril o contornos de vehículos pequeños, sean más claras. A continuación, dos herramientas especializadas, U-Net y DeepLabV3+, toman la imagen mejorada y generan mapas a nivel de píxel que colorean cada punto como calzada, peatón, vehículo o fondo. Finalmente, un detector de objetos llamado YOLOv8x usa cuadros delimitadores para comprobar que las regiones etiquetadas corresponden realmente a coches, personas y elementos de tráfico plausibles y para medir qué tan bien funcionaría el sistema en la práctica.
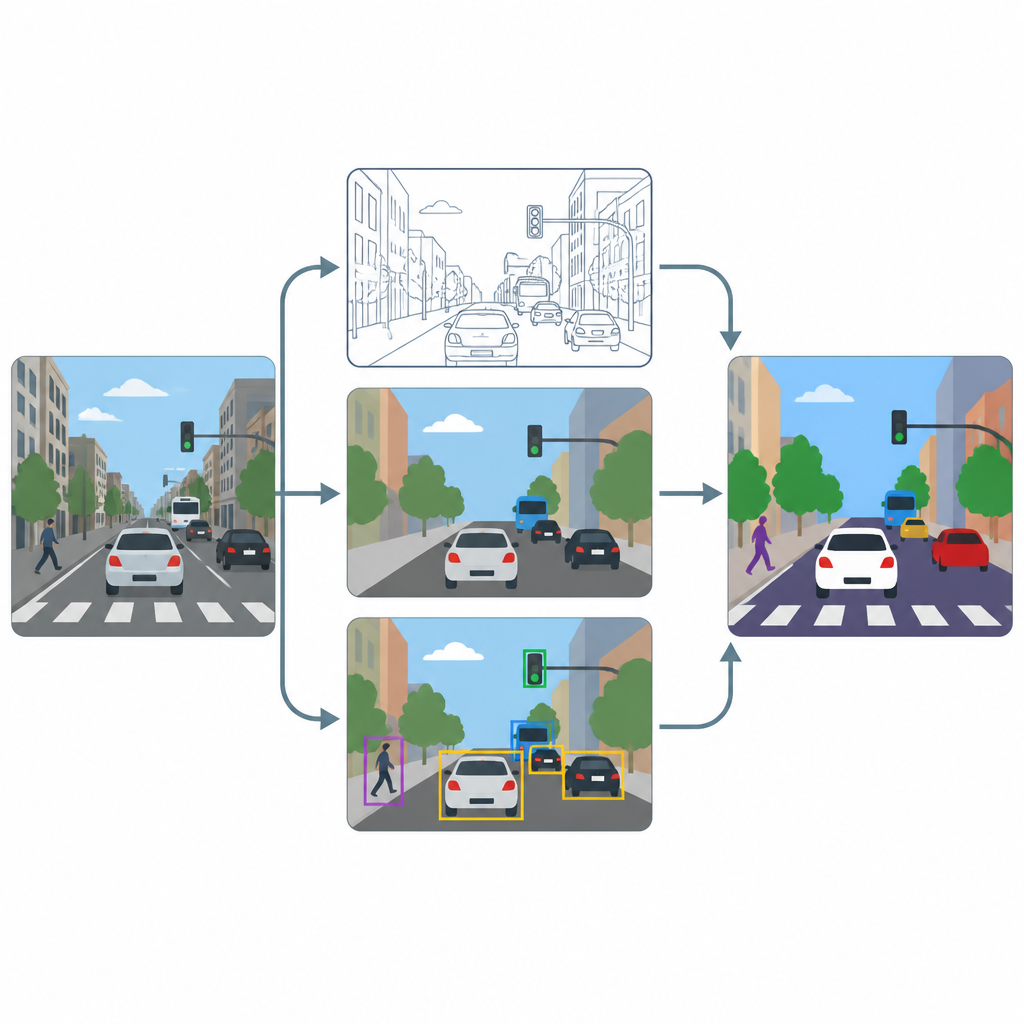
Pruebas en escenas urbanas concurridas
Para evaluar el rendimiento de esta configuración, los autores la entrenan y prueban en un subconjunto de la ampliamente utilizada colección de imágenes COCO, centrándose en escenas con calles, vehículos, señales y peatones. A propósito redimensionan las imágenes a un modesto 640 por 640 píxeles para imitar las transmisiones de cámaras comunes, y emplean una fuerte augmentación de datos para que los modelos vean muchas variaciones en iluminación, desenfoque y punto de vista. Comparan el rendimiento con y sin la etapa de agudizado y registran tanto las métricas basadas en píxeles, que reflejan qué tan bien se delinean las regiones, como las métricas basadas en objetos, que reflejan qué tan bien se detectan usuarios individuales de la vía.
Cómo se comparan las dos herramientas de visión
U-Net y DeepLabV3+ aportan fortalezas diferentes a la tarea. U-Net, con sus fuertes conexiones entre detalles de imagen a distintas escalas, tiende a preservar bordes nítidos alrededor de los objetos y alcanza medidas de calidad de imagen muy altas, incluyendo relaciones señal-ruido pico por encima de 40 decibelios y valores de similitud estructural cercanos a 1.0 en varias muestras. DeepLabV3+ es mejor captando contexto amplio, como cómo se relacionan grupos de vehículos y las vías, y a menudo logra solapamientos de píxel y puntuaciones de detección ligeramente más altas en algunas escenas. A lo largo de múltiples pruebas, la etapa de mejora eleva de forma consistente ambas familias de medidas, lo que indica que entradas más claras se traducen en una comprensión del tráfico más fiable.
Límites en condiciones difíciles y pasos futuros
Los autores también señalan que existen límites. Su sistema se prueba en imágenes estáticas, no en vídeo en directo, y tiene dificultades cuando las condiciones son extremadamente adversas, como niebla densa o desenfoque de movimiento severo, donde incluso la superresolución no puede recuperar suficiente detalle. La etapa adicional de agudizado también incrementa la carga computacional, lo que puede ser un reto para dispositivos de baja potencia en el interior de vehículos. Trabajos futuros buscarán modelos más ligeros, un mejor manejo de efectos nocturnos y meteorológicos, y la extensión a flujos de vídeo completos con seguimiento, con la meta de acercar este tipo de entendimiento detallado de escenas a las exigencias del transporte inteligente en tiempo real.
Qué significa esto para los desplazamientos cotidianos
En términos sencillos, el estudio muestra que ofrecer a los ordenadores una vista más limpia de la calzada antes de pedirles que la interpreten puede hacer sus juicios más fiables. Al combinar la mejora de imagen con dos herramientas complementarias de etiquetado de píxeles y un detector de objetos, el marco propuesto mejora la capacidad de un sistema para separar calzadas, coches y personas en escenas de tráfico concurridas. Aunque todavía no está listo para manejar todas las condiciones adversas o limitaciones de hardware, este enfoque acerca la visión por máquina un paso más a lidiar con las imágenes imperfectas que entregan las calles reales.
Cita: Ramyashree, Utsavi, S.R., Raghavendra, S. et al. Comparative performance analysis of U-Net and DeepLabV3+ for semantic segmentation in traffic environments. Sci Rep 16, 15614 (2026). https://doi.org/10.1038/s41598-026-46740-2
Palabras clave: segmentación semántica, escenas de tráfico, superresolución, U-Net, DeepLabV3+