Clear Sky Science · ja
交通環境におけるセマンティックセグメンテーションの比較性能解析:U-Net と DeepLabV3+
なぜ鮮明な街路映像が重要か
現代の自動車や都市監視カメラは、路上で何が起きているかを理解するためにデジタルビジョンに依存することが増えています。しかし実際の街路映像は研究室の鮮明な写真とは異なり、暗い、ぼやけている、ノイズが多い、解像度が低いといったことがしばしば起こります。本研究は、そのような粗い交通画像を改善し、道路、車両、歩行者を確実に検出できるようにコンピュータを訓練する方法を検討し、将来の運転支援システムや交通監視ツールが現実の過酷な条件下でもより安全な判断を下せるようにすることを目指します。

粗いスナップショットから鮮明なシーンへ
研究者らはシーン理解と呼ばれる課題に注目しています。これは画像内の各ピクセルにカテゴリを割り当て、道路面、歩道、車、バス、歩行者などを意味ある領域に分離する作業です。一般的なシステムは、画像が暗い、手ぶれしている、あるいは粒状性が高い場合にうまく機能しないことが多く、まさに安全な判断が重要になる状況で性能が低下します。これに対処するため、研究チームはまず画像を強調してから内容を詳しく解析するパイプラインを提案し、カメラ映像が完璧でない場合でも性能を維持することを目指します。
画像処理の三段階
パイプラインは三つの主要な段階から成ります:シャープ化、ピクセルラベリング、物体検出。まず、高度な強調手法に基づく超解像モジュールがフレームの解像度とコントラストを向上させ、車線の細いテクスチャや小さな車両の輪郭などの微細な特徴を明瞭にします。次に、U-Net と DeepLabV3+ という二つの専用ツールが改善された画像を入力として、各ピクセルを道路、歩行者、車両、背景などに色分けしたマップを生成します。最後に、YOLOv8x という物体検出器がバウンディングボックスを用いて、ラベル付けされた領域が実際に妥当な車や人、交通要素に対応しているかを検証し、実用面での性能を評価します。
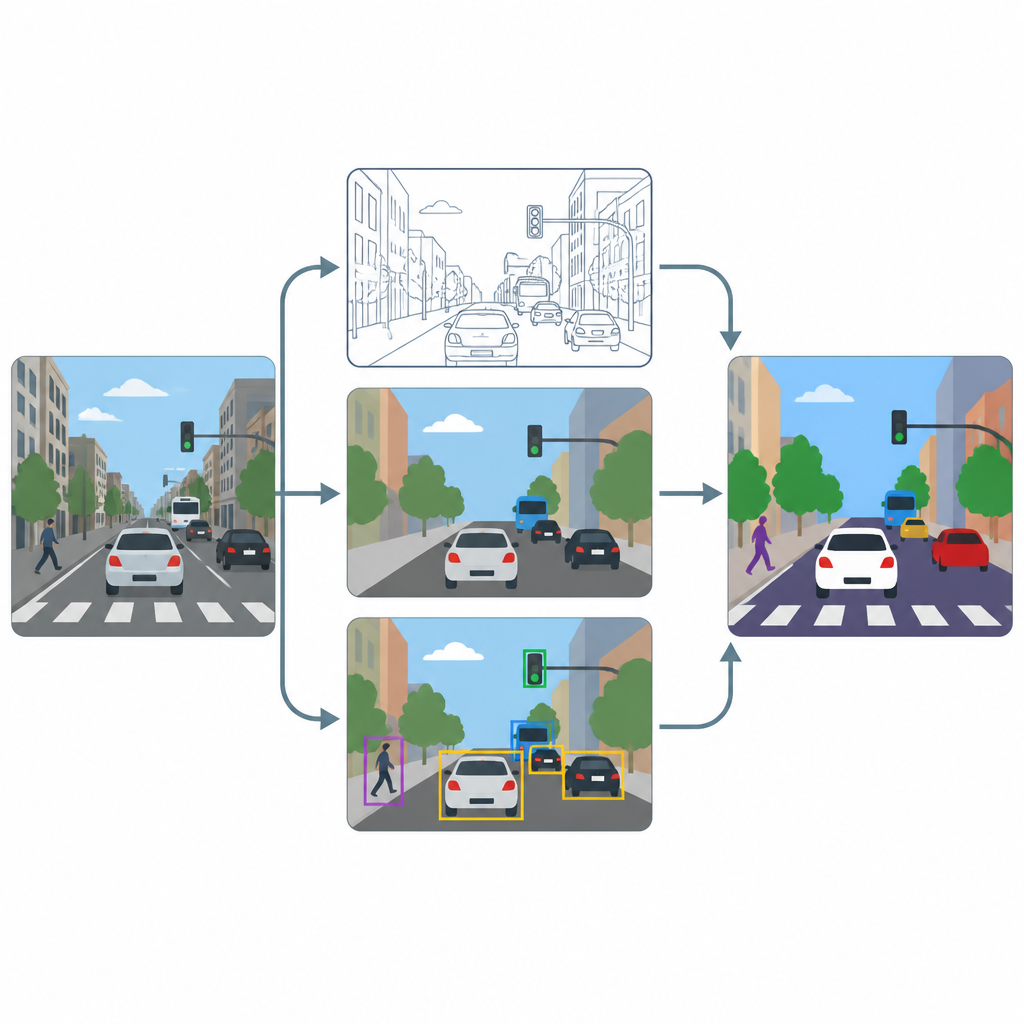
混雑した都市景観でのテスト
この構成の有効性を評価するため、著者らは広く使われる COCO 画像コレクションの一部を用いて学習とテストを行い、道路、車両、信号、歩行者を含むシーンに焦点を当てました。一般的なカメラ映像を模すために画像はあえて 640×640 ピクセルにリサイズされ、強力なデータ拡張を用いて明るさ、ぼけ、視点の変化など多様な状況をモデルに見せています。シャープ化工程の有無で性能を比較し、領域の輪郭精度を示すピクセルベースのスコアと、個々の通行者の検出精度を示すオブジェクトベースのスコアの両方を追跡しました。
二つのビジョン手法の比較
U-Net と DeepLabV3+ はそれぞれ異なる強みを持ちます。U-Net は異なるスケールでの画像特徴間の強い接続を持ち、物体の境界を保持する傾向があり、いくつかのサンプルで 40 デシベルを超えるピーク信号対雑音比や 1.0 に近い構造類似度など非常に高い画像品質指標を達成しました。DeepLabV3+ は車両群と道路の関係など広い文脈を捉えるのが得意で、あるシーンでは若干高いピクセル重なり(オーバーラップ)や検出スコアを示すことがありました。多数の試行を通じて、強調工程はこれら両方の指標を一貫して向上させており、より鮮明な入力がより信頼できる交通理解につながることを示しています。
過酷な路面での限界と今後の課題
著者らは限界点も指摘しています。システムは静止画像で評価されており、ライブ映像には適用されていません。また、濃霧や極端なモーションブラーのように条件が非常に悪い場合は、超解像でも十分な細部を回復できず性能が低下します。さらに、追加のシャープ化工程は計算負荷を増加させ、車載の低消費電力デバイスでは課題となる可能性があります。今後の研究では、より軽量なモデル、夜間や天候影響への対処の改善、追跡を伴うフルビデオストリームへの拡張を検討し、リアルタイムな交通インテリジェンスの要求に近づけることが目標とされています。
日常の移動にとっての意味
平たく言えば、本研究は、コンピュータに道路の解像度の高い映像を与えてから解釈させることで判断の信頼性が向上することを示しています。画像強調と二つの補完的なピクセルラベリング手法、そして物体検出器を組み合わせることで、提案フレームワークは混雑した交通シーンで道路、車両、人を分離する精度を高めます。すべての過酷な条件やハードウェア制約に対処できる段階には達していませんが、このアプローチは現実の街路が生み出す不完全な画像に対処するための機械視覚の前進を意味します。
引用: Ramyashree, Utsavi, S.R., Raghavendra, S. et al. Comparative performance analysis of U-Net and DeepLabV3+ for semantic segmentation in traffic environments. Sci Rep 16, 15614 (2026). https://doi.org/10.1038/s41598-026-46740-2
キーワード: セマンティックセグメンテーション, 交通シーン, 超解像, U-Net, DeepLabV3+