Clear Sky Science · ar
تحليل أداء مقارن بين U-Net و DeepLabV3+ للتقسيم الدلالي في بيئات المرور
لماذا تهم مشاهد الشوارع الأكثر وضوحاً
تعتمد السيارات الحديثة وكاميرات المدن بشكل متزايد على الرؤية الرقمية لفهم ما يجري على الطريق. ومع ذلك، نادراً ما تبدو الشوارع الحقيقية كالصورة الواضحة في مختبرات البحث: فقد تكون الصور مظلمة أو ضبابية أو مشوشة أو منخفضة الدقة. تستكشف هذه الدراسة كيف يمكن تنظيف مثل هذه صور المرور الخشنة ثم تعليم الحواسيب اكتشاف الطرق والمركبات والمشاة بثقة، لمساعدة أنظمة مساعدة السائق وأدوات مراقبة المرور على اتخاذ قرارات أكثر أماناً في ظروف العالم الحقيقي المعقدة.

من لقطات خام إلى مشاهد أوضح
يركز الباحثون على مهمة تسمى فهم المشهد، حيث يخصص الحاسوب فئة لكل بكسل في الصورة بحيث تُفصل أسطح الطريق والأرصفة والسيارات والحافلات والأشخاص إلى مناطق ذات معنى. غالباً ما تفشل الأنظمة العادية عندما تكون الصورة مظلمة أو مهتزة أو حبيبية، وهي بالضبط اللحظات التي تكون فيها القرارات الآمنة بالغة الأهمية. لمواجهة ذلك، يقترح الفريق خط أنابيب يُحسن الصورة أولاً ثم يُجري تحليلاً مفصلاً لمحتوياتها، بهدف الحفاظ على أداء عالٍ حتى عندما يكون تدفق الكاميرا بعيداً عن الكمال.
مسار من ثلاث خطوات عبر الصورة
يتألف خط الأنابيب من ثلاث مراحل رئيسية: الشحذ، تمييز البكسلات، ورصد الأجسام. أولاً، يعزز وحدة تحسين فائق الدقة مبنية على طريقة متقدمة الدقة والتباين لكل إطار بحيث تتضح القوام الدقيقة، مثل علامات الحارة أو محيط المركبات الصغيرة. بعد ذلك، تستخدم أداتان متخصصتان، U-Net و DeepLabV3+، الصورة المحسنة لإنتاج خرائط على مستوى البكسل تُلوّن كل نقطة كطريق أو مشاة أو مركبة أو خلفية. أخيراً، يستخدم كاشف الأجسام المسمى YOLOv8x مربعات التقيد للتحقق من أن المناطق المعلّمة تتوافق فعلاً مع سيارات وأشخاص وعناصر مرورية معقولة ولقياس مدى عمل النظام في التطبيق العملي.
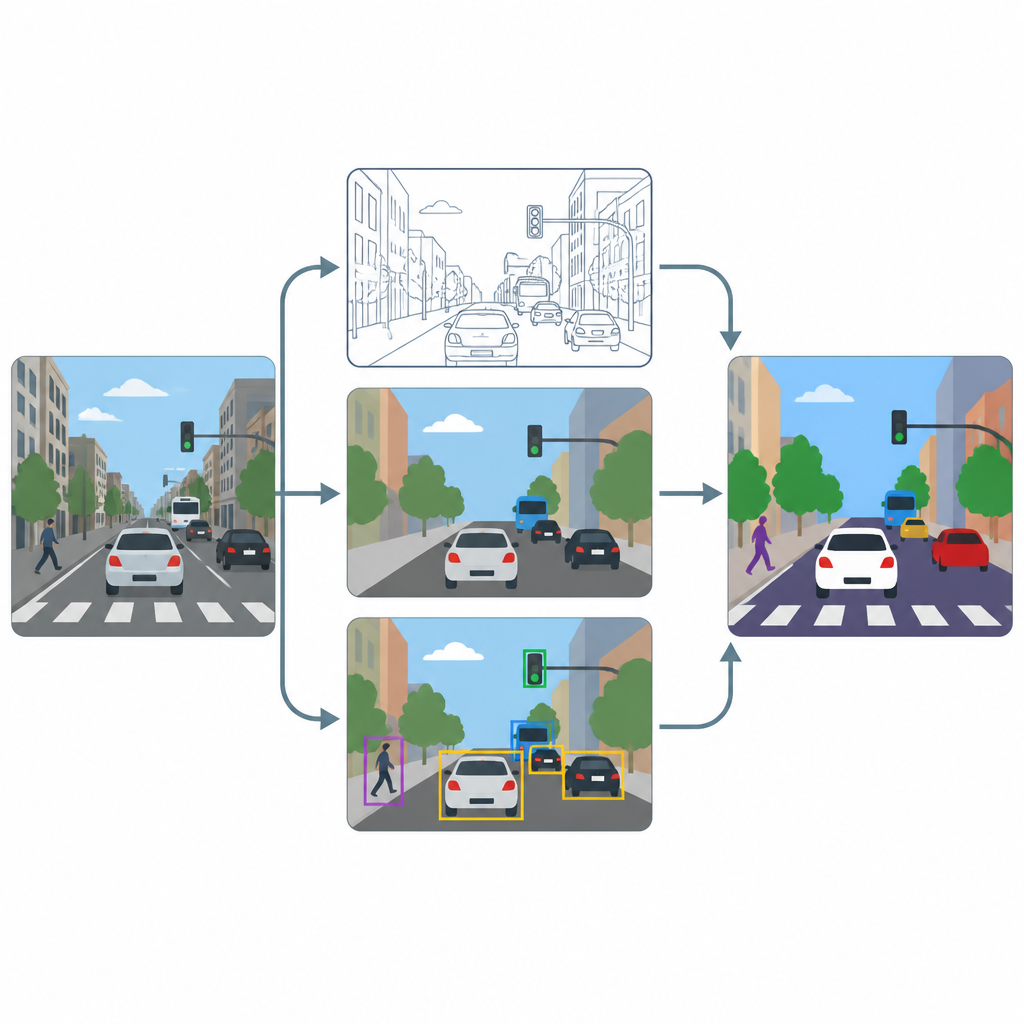
الاختبار على مشاهد مدن مكتظة
لمعرفة مدى فعالية هذا الإعداد، يدرب المؤلفون ويختبرونه على مجموعة فرعية من مجموعة صور COCO واسعة الاستخدام، مع التركيز على المشاهد التي تحتوي على شوارع ومركبات وإشارات ومشاة. عمدوا إلى إعادة تحجيم الصور إلى دقة متواضعة 640×640 بكسل لمحاكاة تدفقات الكاميرات الشائعة، ثم استخدموا تعزيز بيانات قوي حتى ترى النماذج العديد من التنويعات في الإضاءة والضبابية وزاوية الرؤية. يقارنون الأداء مع وجود خطوة الشحذ وبدونها ويتتبعون كل من الدرجات القائمة على البكسل، التي تعكس مدى دقة تحديد المناطق، والدرجات القائمة على الأجسام، التي تعكس مدى اكتشاف مستخدمي الطريق الفرديين.
كيف يقارن الأداتان البصريتان
تجلب U-Net و DeepLabV3+ نقاط قوة مختلفة للمهمة. تميل U-Net، بفضل اتصالاتها القوية بين تفاصيل الصورة على مقاييس مختلفة، إلى الحفاظ على حدود حادة حول الأجسام وتحقق مقاييس جودة صورة عالية جداً، بما في ذلك نسب إشارة إلى ضوضاء مرتفعة تزيد عن 40 ديسيبل وقيم تشابه بنيوي قريبة من 1.0 في عدة عينات. أما DeepLabV3+ فهي أفضل في التقاط السياق الواسع، مثل كيف تتعلق مجموعات المركبات والطرقات ببعضها، وغالباً ما تحقق تداخل بكسلات ودرجات اكتشاف أعلى قليلاً في بعض المشاهد. عبر العديد من التجارب، ترفع خطوة التحسين كلا عائلات المقاييس بشكل مستمر، مما يشير إلى أن المدخلات أوضح تترجم إلى فهم مروري أكثر موثوقية.
حدود على الطرق القاسية والخطوات المستقبلية
يلاحظ المؤلفون أيضاً وجود حدود. فقد اختُبر نظامهم على صور ثابتة، وليس على فيديو مباشر، ويواجه صعوبات عندما تكون الظروف سيئة للغاية، مثل الضباب الكثيف أو الضباب الحركي الشديد، حيث لا يستطيع حتى التحسين الفائق استعادة ما يكفي من التفاصيل. كما تزيد مرحلة الشحذ الإضافية من العبء الحاسوبي، وهو ما قد يشكل تحدياً للأجهزة منخفضة الطاقة داخل المركبات. سينظر العمل المستقبلي في نماذج أخف وزناً، وتحسين التعامل مع ظروف الليل والطقس، والامتداد إلى تدفقات فيديو كاملة مع التتبع، بهدف تقريب هذا النوع من فهم المشهد التفصيلي إلى متطلبات النقل الذكي في الزمن الحقيقي.
ما يعنيه ذلك للتنقل اليومي
بعبارات بسيطة، تُظهر الدراسة أن تزويد الحواسيب بصورة أنظف للطريق قبل مطالبتها بتفسيرها يمكن أن يجعل أحكامها أكثر موثوقية. من خلال الجمع بين تحسين الصور وأداتين تكليفيتين مكملتين على مستوى البكسل وكاشف للأجسام، يُحسن الإطار المقترح مدى قدرة النظام على فصل الطرق والسيارات والأشخاص في مشاهد المرور المزدحمة. وعلى الرغم من أنه لم يصبح جاهزاً بعد للتعامل مع كل الظروف القاسية أو قيود الأجهزة، فإن هذا النهج يقرب رؤية الآلة خطوة نحو التكيف مع الصور غير المثالية التي تلتقطها الشوارع الحقيقية.
الاستشهاد: Ramyashree, Utsavi, S.R., Raghavendra, S. et al. Comparative performance analysis of U-Net and DeepLabV3+ for semantic segmentation in traffic environments. Sci Rep 16, 15614 (2026). https://doi.org/10.1038/s41598-026-46740-2
الكلمات المفتاحية: التقسيم الدلالي, مشاهد المرور, التحسين الفائق للدقة, U-Net, DeepLabV3+