Clear Sky Science · en
Comparative performance analysis of U-Net and DeepLabV3+ for semantic segmentation in traffic environments
Why sharper street views matter
Modern cars and city cameras increasingly rely on digital vision to understand what happens on the road. Yet real streets rarely look like the crisp photos in research labs: images can be dark, blurry, noisy, or low resolution. This study explores how to clean up such rough traffic images and then teach computers to reliably spot roads, vehicles, and pedestrians, helping future driver-assistance systems and traffic monitoring tools make safer decisions in messy real-world conditions.

From rough snapshots to clearer scenes
The researchers focus on a task called scene understanding, where a computer assigns a category to every pixel in an image so that road surfaces, sidewalks, cars, buses, and people are all separated into meaningful regions. Ordinary systems often falter when the picture is dim, shaky, or grainy, which is exactly when safe decisions are most critical. To tackle this, the team proposes a pipeline that first enhances the image and then performs a detailed analysis of its contents, aiming to keep performance high even when the camera feed is far from perfect.
Three step path through the image
The pipeline has three main stages: sharpening, pixel labeling, and object spotting. First, a super resolution module based on an advanced enhancement method boosts the resolution and contrast of each frame so that fine textures, such as lane markings or the outlines of small vehicles, become clearer. Next, two specialist tools, U-Net and DeepLabV3+, take the improved image and produce pixel level maps that color each point as road, pedestrian, vehicle, or background. Finally, an object detector called YOLOv8x uses bounding boxes to check that the labeled regions really correspond to believable cars, people, and traffic elements and to measure how well the system would work in practice.
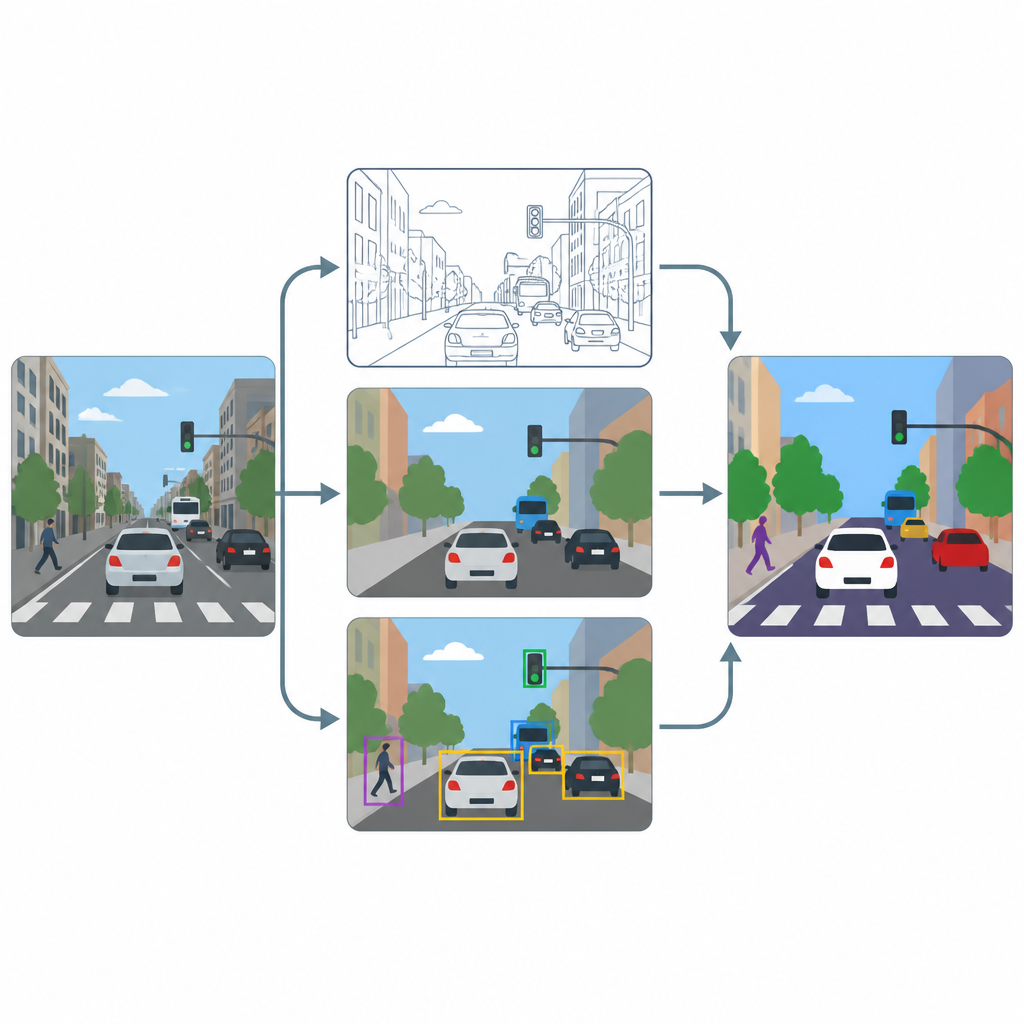
Testing on crowded city scenes
To see how well this setup works, the authors train and test it on a subset of the widely used COCO image collection, focusing on scenes with streets, vehicles, signals, and pedestrians. They purposely resize images to a modest 640 by 640 pixels to mimic common camera feeds, then use strong data augmentation so the models see many variations in lighting, blur, and viewpoint. They compare performance with and without the sharpening step and track both pixel based scores, which reflect how well regions are outlined, and object based scores, which reflect how well individual street users are detected.
How the two vision tools compare
U-Net and DeepLabV3+ bring different strengths to the task. U-Net, with its strong connections between image details at different scales, tends to preserve crisp borders around objects and achieves very high image quality measures, including peak signal to noise ratios above 40 decibels and structural similarity values near 1.0 on several samples. DeepLabV3+ is better at capturing broad context, such as how clusters of vehicles and roads relate, and often achieves slightly higher pixel overlap and detection scores on some scenes. Across many trials, the enhancement step consistently lifts both families of measures, indicating that clearer inputs translate into more trustworthy traffic understanding.
Limits on harsh roads and future steps
The authors also note that there are limits. Their system is tested on still images, not live video, and it struggles when conditions are extremely bad, such as dense fog or severe motion blur, where even super resolution cannot recover enough detail. The extra sharpening stage also increases computational load, which may be a challenge for low power devices inside vehicles. Future work will look at lighter models, better handling of night and weather effects, and extension to full video streams with tracking, aiming to bring this kind of detailed scene understanding closer to the demands of real time intelligent transport.
What this means for everyday travel
In plain terms, the study shows that giving computers a cleaner view of the road before asking them to interpret it can make their judgments more reliable. By combining image enhancement with two complementary pixel labeling tools and an object detector, the proposed framework improves how well a system can separate roads, cars, and people in busy traffic scenes. While not yet ready to handle every harsh condition or hardware constraint, this approach moves machine vision a step closer to coping with the imperfect images that real streets deliver.
Citation: Ramyashree, Utsavi, S.R., Raghavendra, S. et al. Comparative performance analysis of U-Net and DeepLabV3+ for semantic segmentation in traffic environments. Sci Rep 16, 15614 (2026). https://doi.org/10.1038/s41598-026-46740-2
Keywords: semantic segmentation, traffic scenes, super resolution, U-Net, DeepLabV3+