Clear Sky Science · pl
Analiza porównawcza wydajności U-Net i DeepLabV3+ w segmentacji semantycznej w środowiskach drogowych
Dlaczego wyraźniejsze widoki ulic są istotne
Nowoczesne samochody i miejskie kamery coraz częściej polegają na wizji cyfrowej, by rozumieć, co dzieje się na drodze. Tymczasem prawdziwe ulice rzadko wyglądają jak ostre zdjęcia z laboratoriów badawczych: obrazy mogą być ciemne, rozmyte, zaszumione lub niskiej rozdzielczości. W tym badaniu autorzy badają, jak oczyścić takie surowe obrazy drogowe, a następnie nauczyć komputery niezawodnego rozpoznawania jezdni, pojazdów i pieszych, co może pomóc przyszłym systemom wspomagania kierowcy i narzędziom monitorowania ruchu podejmować bezpieczniejsze decyzje w chaotycznych, rzeczywistych warunkach.

Z surowych kadrów do wyraźniejszych scen
Badacze koncentrują się na zadaniu rozumienia sceny, w którym komputer przypisuje kategorię do każdego piksela obrazu, tak aby nawierzchnie dróg, chodniki, samochody, autobusy i ludzie były wyodrębnione jako sensowne regiony. Standardowe systemy często zawodzą, gdy obraz jest przyciemniony, poruszony lub ziarnisty — czyli w sytuacjach, gdy krytyczne jest podejmowanie bezpiecznych decyzji. Aby temu sprostać, zespół proponuje potok przetwarzania, który najpierw poprawia obraz, a następnie wykonuje szczegółową analizę jego zawartości, dążąc do utrzymania wysokiej wydajności nawet gdy strumień z kamery jest daleki od ideału.
Trójetapowa ścieżka przez obraz
Potok składa się z trzech głównych etapów: wyostrzenie, etykietowanie pikseli oraz wykrywanie obiektów. Najpierw moduł super-rozdzielczości oparty na zaawansowanej metodzie poprawia rozdzielczość i kontrast każdego kadru, tak aby drobne tekstury, jak oznakowanie pasów czy kontury małych pojazdów, stały się czytelniejsze. Następnie dwa wyspecjalizowane narzędzia, U-Net i DeepLabV3+, przetwarzają ulepszony obraz i generują mapy na poziomie pikseli, oznaczając każdy punkt jako drogę, pieszego, pojazd lub tło. Wreszcie detektor obiektów o nazwie YOLOv8x używa ramek ograniczających, by zweryfikować, czy oznaczone regiony rzeczywiście odpowiadają realistycznym samochodom, ludziom i elementom ruchu oraz by ocenić, jak system sprawdziłby się w praktyce.
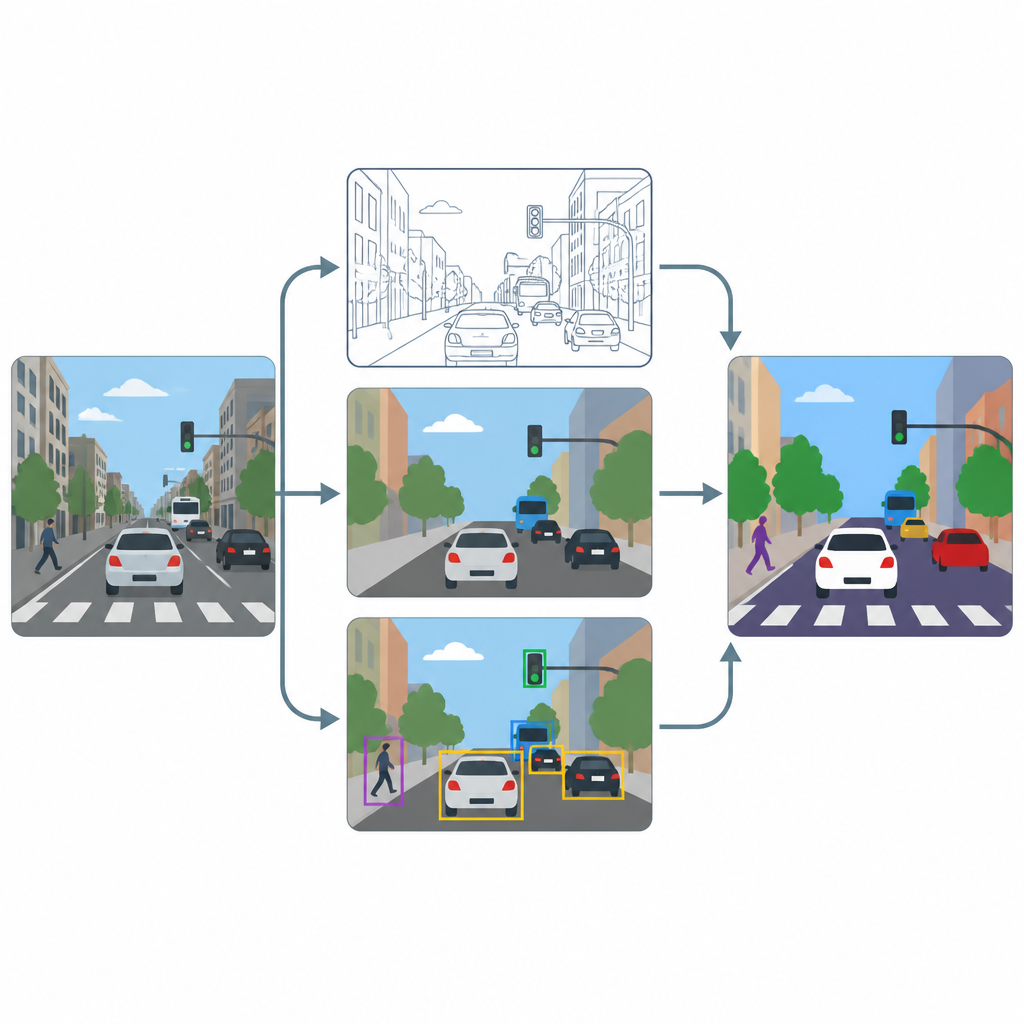
Testy na zatłoczonych miejskich scenach
Aby sprawdzić, jak dobrze ten układ działa, autorzy trenują i testują go na podzbiorze powszechnie używanej kolekcji obrazów COCO, skupiając się na scenach z ulicami, pojazdami, sygnałami i pieszymi. Celowo zmniejszają obrazy do skromnych wymiarów 640 na 640 pikseli, aby naśladować typowe strumienie z kamer, a następnie stosują silną augmentację danych, dzięki czemu modele widzą wiele wariantów oświetlenia, rozmycia i perspektywy. Porównują wyniki z etapem wyostrzania i bez niego oraz śledzą zarówno miary oparte na pikselach, które odzwierciedlają, jak dobrze zarysowano regiony, jak i miary oparte na obiektach, które pokazują, jak dobrze wykryto poszczególnych użytkowników drogi.
Jak porównują się dwa narzędzia wizji
U-Net i DeepLabV3+ wnoszą do zadania różne zalety. U-Net, dzięki silnym połączeniom między szczegółami obrazu na różnych skalach, ma tendencję do zachowywania wyraźnych krawędzi wokół obiektów i osiąga bardzo wysokie miary jakości obrazu, w tym wskaźniki PSNR powyżej 40 dB oraz wartości strukturalnego podobieństwa bliskie 1.0 w kilku próbkach. DeepLabV3+ lepiej oddaje szeroki kontekst, na przykład relacje między skupiskami pojazdów a drogami, i często osiąga nieco wyższe wskaźniki pokrycia pikselowego oraz wykrywania w niektórych scenach. W wielu próbach etap poprawy obrazu konsekwentnie podnosi obie grupy miar, co wskazuje, że wyraźniejsze wejścia przekładają się na bardziej wiarygodne rozumienie scen drogowych.
Ograniczenia w trudnych warunkach i kolejne kroki
Autorzy zauważają również ograniczenia. Ich system testowany jest na obrazach statycznych, a nie na wideo na żywo, i ma problemy, gdy warunki są ekstremalnie złe — na przykład przy gęstej mgle lub silnym rozmyciu ruchowym, gdzie nawet super-rozdzielczość nie jest w stanie odzyskać wystarczającej ilości szczegółów. Dodatkowy etap wyostrzania zwiększa też obciążenie obliczeniowe, co może być wyzwaniem dla urządzeń o niskiej mocy montowanych w pojazdach. Przyszłe prace będą dotyczyć lżejszych modeli, lepszego radzenia sobie z nocą i efektami pogodowymi oraz rozszerzenia na pełne strumienie wideo z śledzeniem, dążąc do przybliżenia tego rodzaju szczegółowego rozumienia sceny do wymagań systemów inteligentnego transportu w czasie rzeczywistym.
Co to oznacza dla codziennych podróży
Mówiąc prosto, badanie pokazuje, że dostarczenie komputerom czyściejszego obrazu drogi przed poproszeniem ich o interpretację może uczynić ich oceny bardziej niezawodnymi. Poprzez połączenie poprawy obrazu z dwoma uzupełniającymi się narzędziami do etykietowania pikseli oraz detektorem obiektów, proponowany schemat poprawia zdolność systemu do rozdzielania dróg, samochodów i ludzi na zatłoczonych scenach drogowych. Choć wciąż nie radzi sobie ze wszystkimi ekstremalnymi warunkami czy ograniczeniami sprzętowymi, podejście to przybliża wizję maszynową do radzenia sobie z niedoskonałymi obrazami, które dostarczają prawdziwe ulice.
Cytowanie: Ramyashree, Utsavi, S.R., Raghavendra, S. et al. Comparative performance analysis of U-Net and DeepLabV3+ for semantic segmentation in traffic environments. Sci Rep 16, 15614 (2026). https://doi.org/10.1038/s41598-026-46740-2
Słowa kluczowe: segmentacja semantyczna, sceny drogowe, super-rozdzielczość, U-Net, DeepLabV3+