Clear Sky Science · sv
Jämförande prestandaanalys av U-Net och DeepLabV3+ för semantisk segmentering i trafikmiljöer
Varför skarpare gatubilder spelar roll
Moderna bilar och stadskameror bygger alltmer på digital syn för att förstå vad som händer i trafiken. Verklighetens gator ser sällan ut som de skarpa bilderna i forskningslaboratorier: bilder kan vara mörka, suddiga, brusiga eller ha låg upplösning. Denna studie utforskar hur man kan förbättra sådana grova trafikbilder och sedan lära datorer att pålitligt känna igen vägar, fordon och fotgängare, vilket hjälper framtida förarassistanssystem och trafikövervakningsverktyg att fatta säkrare beslut i röriga verkliga förhållanden.

Från grova ögonblicksbilder till klarare scener
Forskarna fokuserar på en uppgift kallad scenförståelse, där en dator tilldelar varje pixel i en bild en kategori så att vägytor, trottoarer, bilar, bussar och människor separeras i meningsfulla regioner. Vanliga system fallerar ofta när bilden är mörk, skakig eller kornig, vilket är precis när säkra beslut är viktigast. För att tackla detta föreslår teamet en pipeline som först förbättrar bilden och sedan utför en detaljerad analys av dess innehåll, med målet att bibehålla hög prestanda även när kameraflödet är långt ifrån perfekt.
Trestegsprocess genom bilden
Pipelinen har tre huvudsakliga steg: skärpning, pixelmärkning och objektdetektion. Först ökar en superupplösningsmodul baserad på en avancerad förbättringsmetod upplösningen och kontrasten i varje bildruta så att fina texturer, som körfältsmarkeringar eller konturerna av små fordon, blir tydligare. Därefter tar två specialverktyg, U-Net och DeepLabV3+, den förbättrade bilden och producerar pixelkartor som färgar varje punkt som väg, fotgängare, fordon eller bakgrund. Slutligen använder en objektupptäckare kallad YOLOv8x begränsningsrutor för att kontrollera att de märkta regionerna verkligen motsvarar trovärdiga bilar, människor och trafikelement och för att mäta hur väl systemet skulle fungera i praktiken.
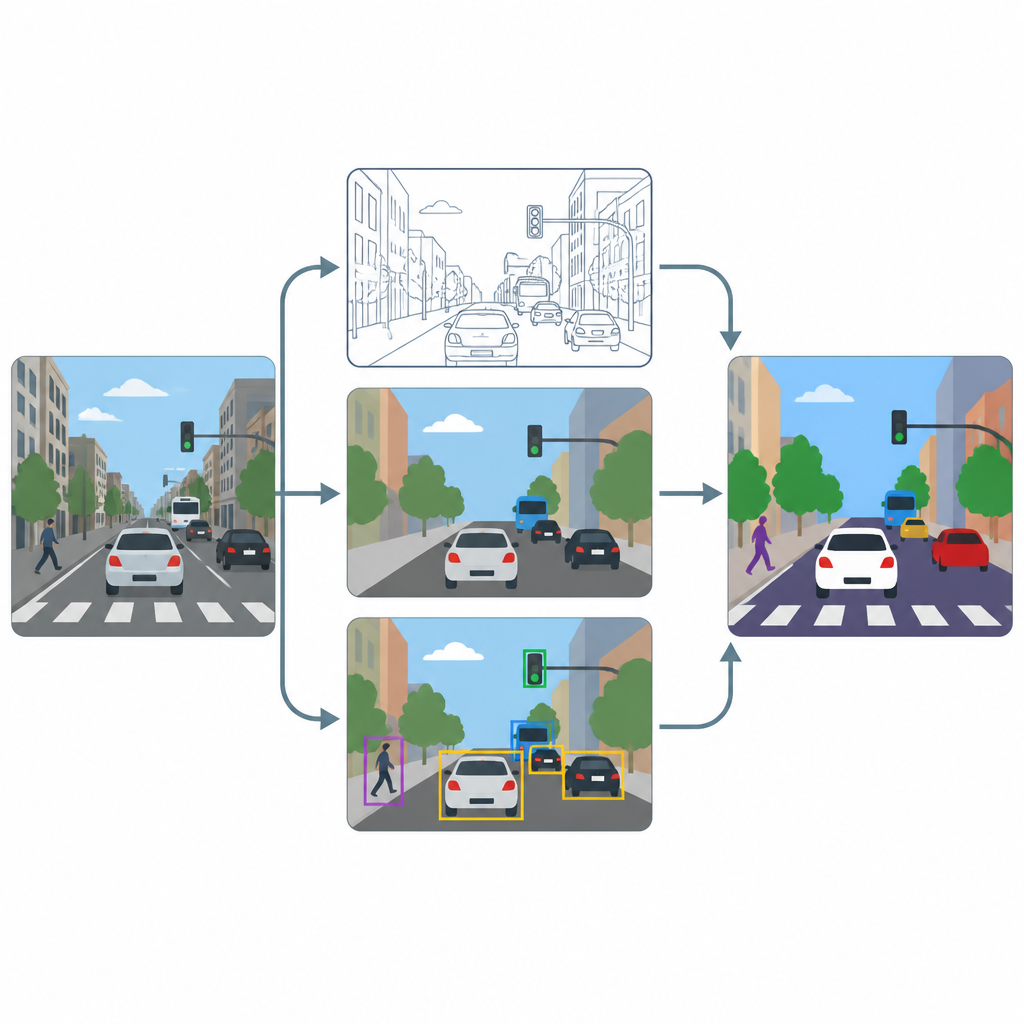
Testning på trånga stadsscener
För att se hur väl denna uppsättning fungerar tränar och testar författarna den på en delmängd av den välanvända COCO-bildsamlingen, med fokus på scener med gator, fordon, trafikljus och fotgängare. De ändrar medvetet storleken på bilderna till ett måttligt 640 x 640 pixlar för att efterlikna vanliga kameraflöden, och använder kraftig dataaugmentering så att modellerna ser många variationer i belysning, oskärpa och vyer. De jämför prestanda med och utan skärpningssteget och följer både pixelorienterade mått, som visar hur väl regioner är avgränsade, och objektorienterade mått, som visar hur väl enskilda trafikanter upptäcks.
Hur de två synverktygen står sig
U-Net och DeepLabV3+ tillför olika styrkor till uppgiften. U-Net, med sina starka förbindelser mellan bilddetaljer i olika skalor, tenderar att bevara skarpa gränser runt objekt och uppnår mycket höga bildkvalitetsmått, inklusive toppsignal-brusförhållanden över 40 decibel och strukturella likhetsvärden nära 1,0 på flera prover. DeepLabV3+ är bättre på att fånga bredare kontext, till exempel hur kluster av fordon och vägar förhåller sig, och uppnår ofta något högre pixelöverlappar och detektionspoäng i vissa scener. Över många försök förbättrar skärpningssteget konsekvent båda typerna av mått, vilket tyder på att klarare indata översätts till mer tillförlitlig trafikförståelse.
Begränsningar på hårda vägar och nästa steg
Författarna noterar också att det finns begränsningar. Deras system testas på stillbilder, inte livevideo, och det har svårigheter när förhållandena är extremt dåliga, såsom tät dimma eller kraftig rörelseoskärpa, där även superupplösning inte kan återställa tillräckligt med detalj. Det extra skärpningssteget ökar också beräkningsbelastningen, vilket kan vara en utmaning för lågströmsenheter i fordon. Framtida arbete kommer att se på lättare modeller, bättre hantering av natt- och vädereffekter och utvidgning till hela videoströmmar med spårning, i syfte att föra denna typ av detaljerad scenförståelse närmare kraven för realtidsintelligent transport.
Vad detta betyder för vardagsresor
Enkelt uttryckt visar studien att att ge datorer en renare vy av vägen innan man ber dem tolka den kan göra deras bedömningar mer tillförlitliga. Genom att kombinera bildförbättring med två kompletterande pixelmärkningsverktyg och en objektupptäckare förbättrar den föreslagna ramen hur väl ett system kan separera vägar, bilar och människor i trafiktäta scener. Även om metoden ännu inte klarar alla hårda förhållanden eller hårdvarubegränsningar, tar detta tillvägagångssätt maskinsyn ett steg närmare att hantera de ofullkomliga bilder som verkliga gator levererar.
Citering: Ramyashree, Utsavi, S.R., Raghavendra, S. et al. Comparative performance analysis of U-Net and DeepLabV3+ for semantic segmentation in traffic environments. Sci Rep 16, 15614 (2026). https://doi.org/10.1038/s41598-026-46740-2
Nyckelord: semantisk segmentering, trafikscener, superupplösning, U-Net, DeepLabV3+