Clear Sky Science · de
Vergleichende Leistungsanalyse von U-Net und DeepLabV3+ für semantische Segmentierung in Verkehrs‑umgebungen
Warum schärfere Straßensichten wichtig sind
Moderne Fahrzeuge und städtische Kameras verlassen sich zunehmend auf digitale Sicht, um zu erfassen, was auf der Straße passiert. Reale Straßen sehen jedoch selten aus wie die scharfen Fotos aus Forschungslabors: Bilder können dunkel, verschwommen, verrauscht oder niedrig aufgelöst sein. Diese Studie untersucht, wie man solche groben Verkehrsbilder bereinigt und anschließend Computern beibringt, zuverlässig Fahrbahnen, Fahrzeuge und Fußgänger zu erkennen, damit künftige Fahrerassistenzsysteme und Verkehrsüberwachungstools in unübersichtlichen realen Situationen sicherere Entscheidungen treffen können.

Von groben Schnappschüssen zu klareren Szenen
Die Forschenden konzentrieren sich auf eine Aufgabe, die als Szenenverständnis bezeichnet wird: Dabei weist ein Computer jedem Pixel im Bild eine Kategorie zu, sodass Fahrbahnflächen, Gehwege, Autos, Busse und Menschen in sinnvolle Regionen getrennt werden. Herkömmliche Systeme versagen oft, wenn das Bild dunkel, verwackelt oder körnig ist—gerade dann, wenn sichere Entscheidungen besonders wichtig sind. Um dem zu begegnen, schlägt das Team eine Pipeline vor, die das Bild zunächst verbessert und dann eine detaillierte Analyse seines Inhalts durchführt, mit dem Ziel, die Leistungsfähigkeit auch dann hochzuhalten, wenn das Kamerabild alles andere als perfekt ist.
Dreistufiger Pfad durch das Bild
Die Pipeline hat drei Hauptstufen: Schärfung, Pixelklassifizierung und Objekterkennung. Zuerst erhöht ein Super‑Resolution‑Modul, basierend auf einer fortgeschrittenen Aufbereitungsmethode, die Auflösung und den Kontrast jedes Frames, sodass feine Strukturen wie Fahrbahnmarkierungen oder die Konturen kleiner Fahrzeuge klarer werden. Danach erzeugen zwei spezialisierte Werkzeuge, U-Net und DeepLabV3+, aus dem verbesserten Bild Pixelkarten, die jeden Punkt als Straße, Fußgänger, Fahrzeug oder Hintergrund einfärben. Schließlich nutzt ein Objektdetektor namens YOLOv8x Begrenzungsrahmen, um zu prüfen, ob die markierten Regionen tatsächlich plausiblen Autos, Personen und Verkehrselementen entsprechen, und um zu messen, wie gut das System in der Praxis funktionieren würde.
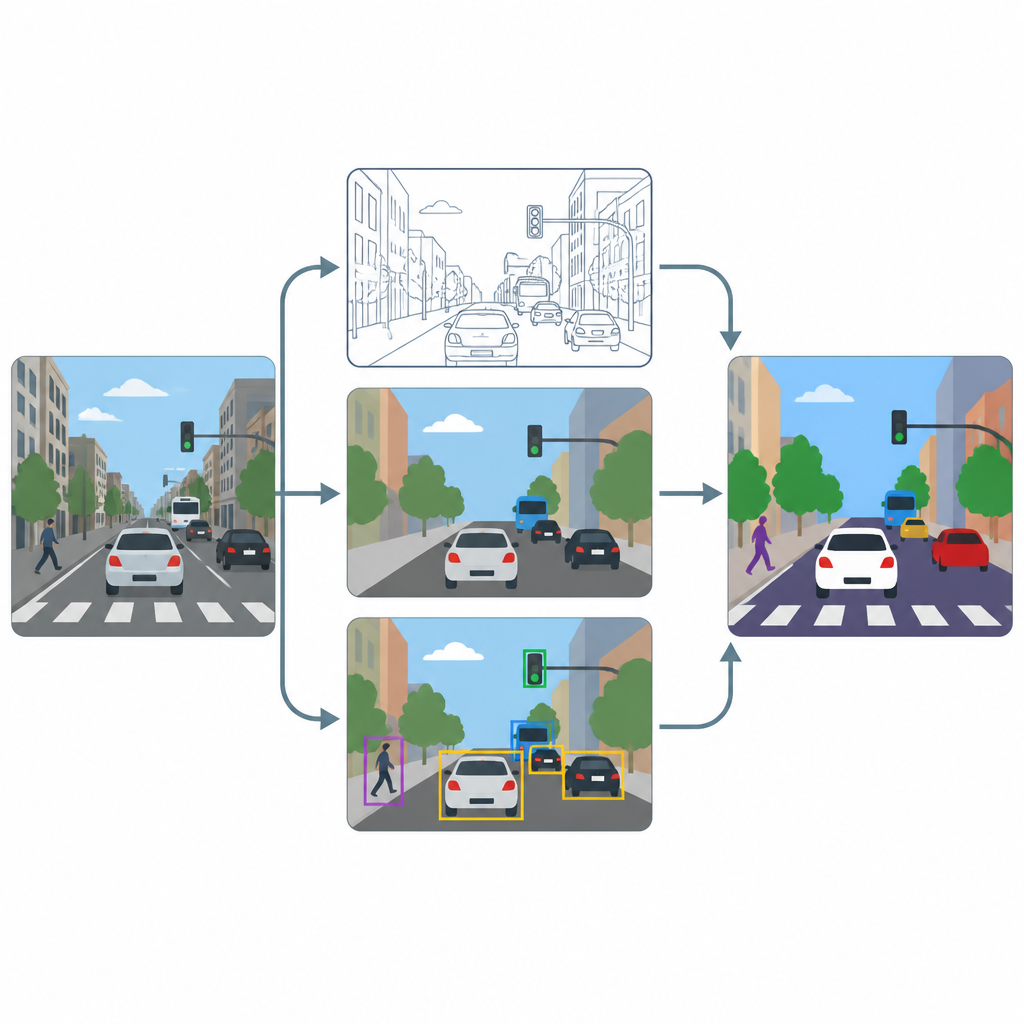
Test auf vollen Innenstadt‑Szenen
Um die Leistungsfähigkeit dieses Aufbaus zu prüfen, trainieren und testen die Autorinnen und Autoren ihn an einem Teilbestand der weit verbreiteten COCO‑Bildersammlung, mit Schwerpunkt auf Szenen mit Straßen, Fahrzeugen, Signalen und Fußgängern. Sie verkleinern die Bilder absichtlich auf ein moderates Format von 640 mal 640 Pixeln, um gängige Kamerafeeds zu imitieren, und wenden starke Datenaugmentierung an, damit die Modelle viele Variationen in Beleuchtung, Unschärfe und Blickwinkel sehen. Sie vergleichen die Leistung mit und ohne den Schärfungsschritt und verfolgen sowohl pixelbasierte Metriken, die widerspiegeln, wie gut Regionen abgegrenzt sind, als auch objektbasierte Kennzahlen, die zeigen, wie gut einzelne Verkehrsteilnehmer erkannt werden.
Wie sich die beiden Vision‑Werkzeuge vergleichen
U-Net und DeepLabV3+ bringen unterschiedliche Stärken in die Aufgabe ein. U-Net mit seinen starken Verbindungen zwischen Bilddetails auf verschiedenen Skalen neigt dazu, scharfe Kanten um Objekte zu erhalten und erreicht sehr hohe Bildqualitätsmaße, darunter Spitzenwertverhältnisse (PSNR) über 40 Dezibel und strukturelle Ähnlichkeitswerte nahe 1,0 in mehreren Beispielen. DeepLabV3+ erfasst dagegen besser den breiten Kontext, etwa wie Fahrzeuggruppen und Straßen zueinander in Beziehung stehen, und erzielt in einigen Szenen oft leicht höhere Pixelüberlappungs‑ und Erkennungswerte. In vielen Versuchen hebt der Verbesserungs‑Schritt beide Messgrößen konstant an, was darauf hindeutet, dass klarere Eingaben in ein vertrauenswürdigeres Verkehrsverständnis münden.
Grenzen auf rauen Straßen und nächste Schritte
Die Autorinnen und Autoren weisen auch auf Grenzen hin. Ihr System wurde an Standbildern getestet, nicht an Live‑Video, und es hat Schwierigkeiten, wenn die Bedingungen extrem schlecht sind—etwa dichter Nebel oder starke Bewegungsunschärfe—wo selbst Super Resolution nicht genügend Details zurückgewinnen kann. Die zusätzliche Schärfungsstufe erhöht außerdem die Rechenlast, was für energiearme Geräte in Fahrzeugen eine Herausforderung darstellen kann. Zukünftige Arbeiten werden leichtere Modelle, besseres Handling von Nacht‑ und Witterungseffekten sowie die Erweiterung auf vollständige Videoströme mit Tracking untersuchen, mit dem Ziel, dieses detaillierte Szenenverständnis näher an die Anforderungen des Echtzeit‑intelligenten Verkehrs zu bringen.
Was das für den Alltag im Verkehr bedeutet
Einfach gesagt zeigt die Studie, dass es die Urteile von Algorithmen verlässlicher machen kann, wenn man Computern vor der Interpretation eine sauberere Sicht auf die Straße gibt. Durch die Kombination von Bildverbesserung mit zwei komplementären Pixelkennzeichnern und einem Objektdetektor verbessert das vorgeschlagene Framework, wie gut ein System Straßen, Autos und Menschen in belebten Verkehrsszenen trennt. Auch wenn es noch nicht alle harten Bedingungen oder Hardwarebeschränkungen abdeckt, bringt dieser Ansatz die maschinelle Sicht einen Schritt näher daran, mit den unvollkommenen Bildern zurechtzukommen, die reale Straßen liefern.
Zitation: Ramyashree, Utsavi, S.R., Raghavendra, S. et al. Comparative performance analysis of U-Net and DeepLabV3+ for semantic segmentation in traffic environments. Sci Rep 16, 15614 (2026). https://doi.org/10.1038/s41598-026-46740-2
Schlüsselwörter: semantische Segmentierung, Verkehrsszenen, Super Resolution, U-Net, DeepLabV3+