Clear Sky Science · it
Analisi comparativa delle prestazioni di U-Net e DeepLabV3+ per la segmentazione semantica in ambienti stradali
Perché viste stradali più nitide sono importanti
Auto moderne e telecamere urbane si affidano sempre più alla visione digitale per capire cosa accade sulla strada. Eppure le strade reali raramente assomigliano alle foto nitide dei laboratori: le immagini possono essere scure, sfocate, rumorose o a bassa risoluzione. Questo studio esplora come ripulire immagini stradali imperfette e poi insegnare ai computer a riconoscere in modo affidabile corsie, veicoli e pedoni, aiutando i futuri sistemi di assistenza alla guida e gli strumenti di monitoraggio del traffico a prendere decisioni più sicure in condizioni reali e disordinate.

Da scatti grezzi a scene più chiare
I ricercatori si concentrano su un compito chiamato comprensione della scena, in cui un computer assegna una categoria a ogni pixel di un’immagine in modo che superfici stradali, marciapiedi, auto, autobus e persone siano separati in regioni significative. I sistemi ordinari spesso vacillano quando l’immagine è fioca, mossa o granulosa, proprio quando le decisioni sicure sono più critiche. Per affrontare questo problema, il team propone una pipeline che prima migliora l’immagine e poi ne esegue un’analisi dettagliata, con l’obiettivo di mantenere alte le prestazioni anche quando il flusso delle telecamere è ben lontano dalla perfezione.
Percorso in tre fasi attraverso l’immagine
La pipeline ha tre fasi principali: affinamento, etichettatura dei pixel e rilevamento degli oggetti. Innanzitutto, un modulo di super risoluzione basato su un metodo avanzato di miglioramento aumenta la risoluzione e il contrasto di ogni fotogramma in modo che le texture fini, come le segnaletiche di corsia o i contorni di piccoli veicoli, diventino più leggibili. Successivamente, due strumenti specialistici, U-Net e DeepLabV3+, prendono l’immagine migliorata e producono mappe a livello di pixel che colorano ogni punto come strada, pedone, veicolo o sfondo. Infine, un rilevatore di oggetti chiamato YOLOv8x usa riquadri di delimitazione per verificare che le regioni etichettate corrispondano effettivamente a auto, persone ed elementi del traffico credibili e per misurare quanto il sistema funzionerebbe in pratica.
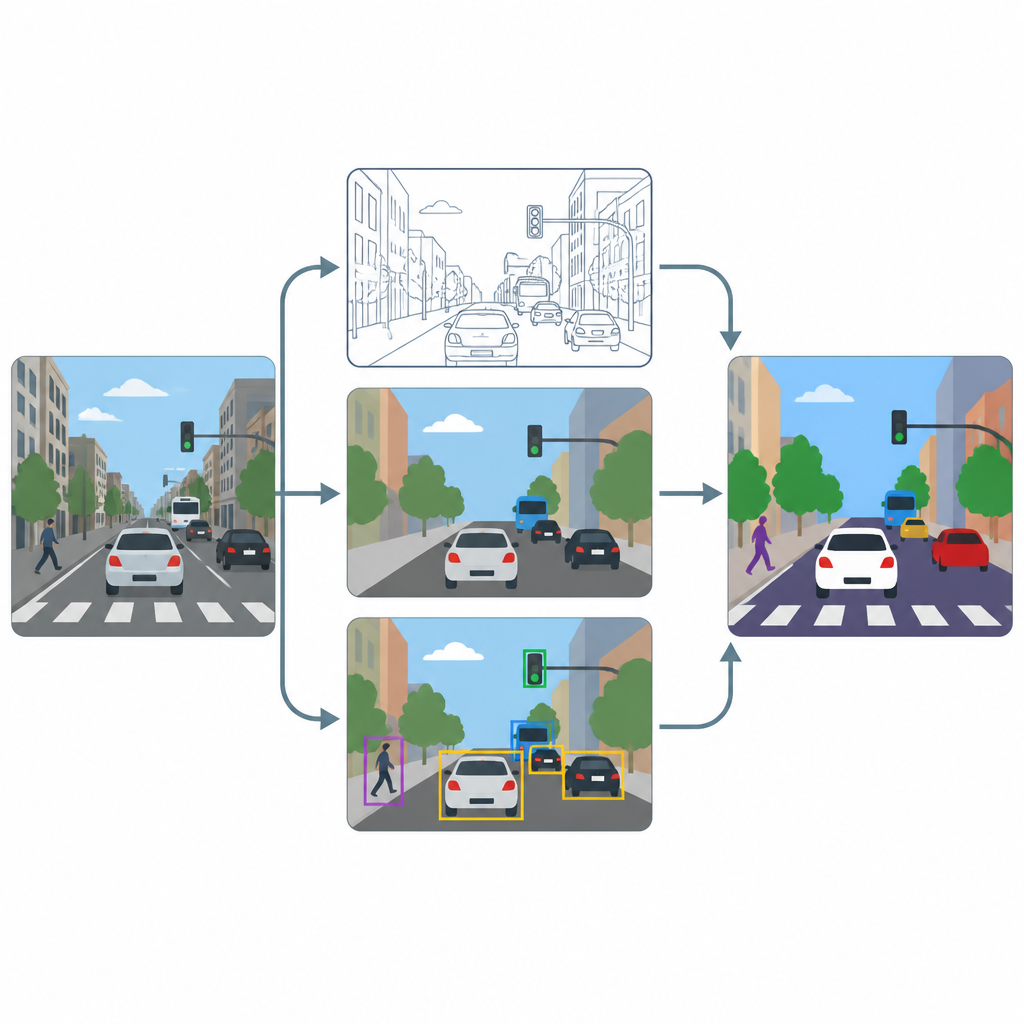
Test su scene cittadine affollate
Per valutare l’efficacia di questo approccio, gli autori lo addestrano e lo testano su un sottoinsieme della nota raccolta di immagini COCO, concentrandosi su scene con strade, veicoli, segnali e pedoni. Ridimensionano intenzionalmente le immagini a una modesta risoluzione di 640 per 640 pixel per imitare i flussi delle telecamere comuni, quindi usano robuste tecniche di data augmentation affinché i modelli vedano molte variazioni di illuminazione, sfocatura e punto di vista. Confrontano le prestazioni con e senza la fase di affinamento e monitorano sia i punteggi basati sui pixel, che riflettono quanto bene sono delineate le regioni, sia i punteggi basati sugli oggetti, che indicano quanto bene vengono rilevati i singoli utenti della strada.
Come si confrontano i due strumenti di visione
U-Net e DeepLabV3+ offrono punti di forza diversi per il compito. U-Net, con le sue solide connessioni tra dettagli dell’immagine a scale differenti, tende a preservare bordi netti attorno agli oggetti e raggiunge misure di qualità dell’immagine molto elevate, inclusi rapporti segnale-rumore di picco oltre i 40 decibel e valori di similarità strutturale vicini a 1.0 su diversi campioni. DeepLabV3+ è migliore nel catturare il contesto ampio, ad esempio come si relazionano gruppi di veicoli e strade, e spesso ottiene sovrapposizioni di pixel e punteggi di rilevamento leggermente più alti in alcune scene. In molte prove, la fase di miglioramento solleva costantemente entrambe le famiglie di misure, indicando che input più chiari si traducono in una comprensione del traffico più affidabile.
Limiti su strade difficili e passi futuri
Gli autori osservano anche dei limiti. Il loro sistema è testato su immagini statiche, non su video in tempo reale, e fatica quando le condizioni sono estremamente avverse, come nebbia densa o sfocature da moto severe, in cui anche la super risoluzione non riesce a recuperare dettagli sufficienti. La fase di affinamento aggiuntiva aumenta inoltre il carico computazionale, il che può rappresentare una sfida per dispositivi a bassa potenza installati nei veicoli. Il lavoro futuro indagherà modelli più leggeri, una migliore gestione degli effetti notturni e meteorologici e l’estensione a flussi video completi con tracciamento, con l’obiettivo di avvicinare questo tipo di comprensione dettagliata della scena alle esigenze del trasporto intelligente in tempo reale.
Cosa significa per il viaggio quotidiano
In termini semplici, lo studio mostra che fornire ai computer una vista della strada più pulita prima di chiedere loro di interpretarla può rendere i loro giudizi più affidabili. Combinando il miglioramento dell’immagine con due strumenti complementari di etichettatura dei pixel e un rilevatore di oggetti, il framework proposto migliora la capacità di separare strade, auto e persone in scene di traffico affollate. Pur non essendo ancora pronto a gestire tutte le condizioni estreme o i vincoli hardware, questo approccio avvicina la visione artificiale alla capacità di affrontare le immagini imperfette che le strade reali offrono.
Citazione: Ramyashree, Utsavi, S.R., Raghavendra, S. et al. Comparative performance analysis of U-Net and DeepLabV3+ for semantic segmentation in traffic environments. Sci Rep 16, 15614 (2026). https://doi.org/10.1038/s41598-026-46740-2
Parole chiave: segmentazione semantica, scene stradali, super risoluzione, U-Net, DeepLabV3+