Clear Sky Science · he
ניתוח ביצועים השוואתי של U-Net ו-DeepLabV3+ לחלוקה סמנטית בסביבות תעבורה
למה חשובות תצוגות רחוב חדות יותר
מכוניות מודרניות ומצלמות עירוניות מסתמכות יותר ויותר על ראייה דיגיטלית כדי להבין מה קורה על הכביש. עם זאת רחובות אמיתיים נדירים כמוחשבים בתמונות חדות ממעבדות מחקר: תמונות יכולות להיות חשוכות, מטושטשות, רעשניות או בעלות רזולוציה נמוכה. מחקר זה חוקר כיצד לנקות תמונות תעבורה גסות כאלה ולאחר מכן ללמד מחשבים לזהות באופן אמין כבישים, כלי רכב והולכי רגל, כדי לעזור למערכות סיוע לנהג ולעקיבת תנועה לקבל החלטות בטוחות יותר בתנאים אמיתיים ואי-סדירים.

מתמונות גסות לסצנות ברורות יותר
החוקרים מתמקדים במשימה הנקראת הבנת סצנה, שבה מחשב מקצה קטגוריה לכל פיקסל בתמונה כך שמשטחים כביש, מדרכות, מכוניות, אוטובוסים ואנשים יופרדו לאזורים משמעותיים. מערכות רגילות נכשלים לעתים קרובות כאשר התמונה חשוכה, רעועה או גרעינית — בדיוק ברגעים שבהם החלטות בטוחות הן הקריטיות ביותר. כדי להתמודד עם זאת, הצוות מציע צינור עיבוד שמתחיל בהשבחת התמונה ולאחר מכן מבצע ניתוח מפורט של התכולה, במטרה לשמר ביצועים גבוהים גם כאשר זרם המצלמה רחוק מהאידיאל.
נתיב תלת־שלבי דרך התמונה
לצינור שלוש שלבים עיקריים: השחזה, תיוג פיקסלים וזיהוי עצמים. תחילה מודול שיפור רזולוציה המבוסס על שיטת השבחה מתקדמת מעלה את הרזולוציה והניגודיות של כל פריים כך שמרקמים דקים, כמו סימוני נתיבים או קווי מתאר של כלי רכב קטנים, יהיו ברורים יותר. לאחר מכן שני כלים מומחים, U-Net ו-DeepLabV3+, מעבדים את התמונה המשופרת ויוצרים מפות פיקסלים שמצבעות כל נקודה ככביש, הולך רגל, כלי רכב או רקע. לבסוף, גלאי עצמים בשם YOLOv8x משתמש בקופסאות חוצות כדי לבדוק שהאזורים המסומנים אכן מתאימים למכוניות, אנשים ואלמנטים תעבורתיים אמינים ולמדוד עד כמה המערכת תעבוד בפועל.
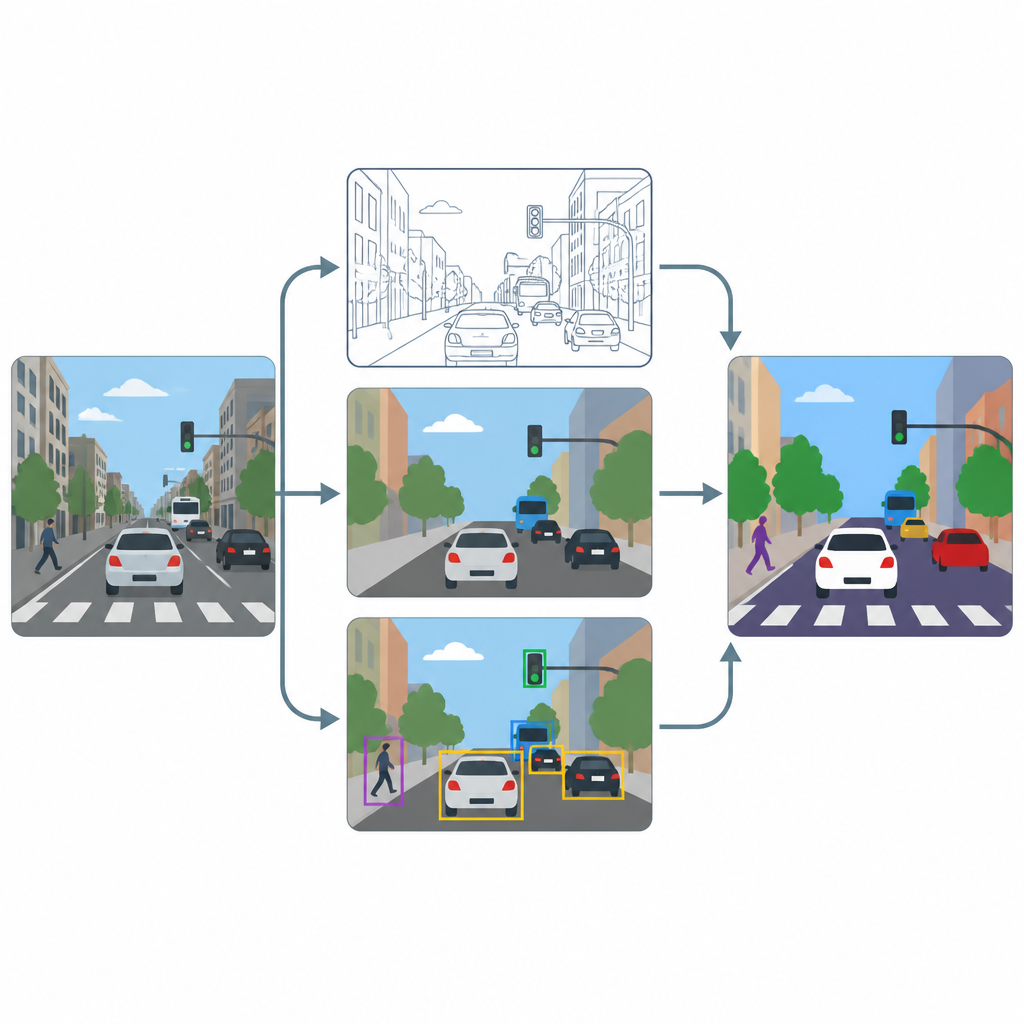
בדיקות בסצנות עירוניות צפופות
כדי לבדוק עד כמה ההתקנה הזו עובדת, המחברים מאמנים ובוחנים אותה על תת-קבוצה מאוסף התמונות הנפוץ COCO, המתמקדת בסצנות עם רחובות, כלי רכב, אותות והולכי רגל. הם בכוונה משנים גודל תמונות ל-640 על 640 פיקסלים כדי לדמות זרמי מצלמות נפוצים, ואז משתמשים בהגברה חזקה של נתונים כדי שהמודלים יראו וריאציות רבות של תאורה, טשטוש וזוויות מבט. הם משווים ביצועים עם וללא שלב ההשחזה ועוקבים הן אחר מדדי פיקסל, המשקפים עד כמה האזורים מתוכננים היטב, והן אחר מדדי עצמים, המשקפים עד כמה משתמשי הדרך הבודדים מזוהים כהלכה.
כיצד שני כלי הראייה משתווים
U-Net ו-DeepLabV3+ מביאים חוזקות שונות למשימה. U-Net, עם הקשרים החזקים שלו בין פרטי תמונה בקני מידה שונים, נוטה לשמר גבולות חדים סביב עצמים ומשיג מדדי איכות תמונה גבוהים מאוד, כולל יחס אות לרעש שיא מעל 40 דציבלים וערכי דמיון מבני קרובים ל-1.0 בדגימות מסוימות. DeepLabV3+ טוב יותר בלכידת הקשר הרחב, כמו איך קבוצות כלי רכב וכבישים מתקשרות זה עם זה, ולעתים משיג מעט נחיתות חופפת פיקסלים ומדדי זיהוי גבוהים יותר בסצנות מסוימות. בכל ניסויי הרב, שלב ההשבחה מעלה בעקביות את שתי משפחות המדדים, מה שמעיד שקלטים ברורים יותר מתורגמים להבנה תעבורתית אמינה יותר.
מגבלות בכבישים קשים וצעדים עתידיים
המחברים גם מציינים שיש מגבלות. המערכת שלהם נבדקה על תמונות סטילס, לא על וידאו חי, והיא מתקשה כאשר התנאים גרועים מאוד, כמו ערפול כבד או טשטוש תנועה חמור, שבהם אפילו שיפור רזולוציה אינו משיב מספיק פרטים. שלב ההשחזה הנוסף גם מגדיל את העומס החישובי, מה שעלול להוות אתגר למכשירים בעלי צריכת חשמל נמוכה בתוך כלי רכב. עבודת המשך תבחן מודלים קלים יותר, טיפול טוב יותר בנסיבות לילה ומזג אוויר, והרחבה לזרמי וידאו מלאים עם מעקב, במטרה לקרב את סוג זה של הבנת סצנה מפורטת לדרישות זמן-אמת של תעבורה חכמה.
מה משמעות הדבר לנסיעות יומיומיות
באופן פשוט, המחקר מראה שלהעניק למחשבים תצוגה נקייה יותר של הכביש לפני שמבקשים מהם לפרש אותה יכול להפוך את שיפוטיהם לאמינים יותר. על ידי שילוב שיפור תמונה עם שני כלים משלימים לתיוג פיקסלים וגלאי עצמים, המסגרת המוצעת משפרת עד כמה מערכת יכולה להפריד כבישים, מכוניות ואנשים בסצנות תעבורה עמוסות. למרות שהיא עדיין לא ערוכה להתמודד עם כל תנאי קיצון או מגבלות חומרה, גישה זו מקרבת את הראייה הממכנית צעד נוסף להתמודדות עם התמונות הפגומות שמספקים הרחובות האמיתיים.
ציטוט: Ramyashree, Utsavi, S.R., Raghavendra, S. et al. Comparative performance analysis of U-Net and DeepLabV3+ for semantic segmentation in traffic environments. Sci Rep 16, 15614 (2026). https://doi.org/10.1038/s41598-026-46740-2
מילות מפתח: חלוקה סמנטית, סצנות תעבורה, שיפור רזולוציה, U-Net, DeepLabV3+