Clear Sky Science · nl
Vergelijkende prestatieanalyse van U-Net en DeepLabV3+ voor semantische segmentatie in verkeersomgevingen
Waarom scherpere straatbeelden ertoe doen
Moderne auto’s en stadscamera’s vertrouwen steeds vaker op digitale visie om te begrijpen wat er op de weg gebeurt. Toch lijken echte straten zelden op de scherpe foto’s in laboratoria: beelden kunnen donker, wazig, ruisig of van lage resolutie zijn. Deze studie onderzoekt hoe zulke ruwe verkeersbeelden kunnen worden opgeschoond en vervolgens hoe computers betrouwbaar wegen, voertuigen en voetgangers kunnen herkennen, zodat toekomstige rijhulpsystemen en verkeersmonitoringtools onder rommelige, realistische omstandigheden veiliger beslissingen kunnen nemen.

Van ruwe snapshots naar helderdere scènes
De onderzoekers richten zich op een taak die scene understanding heet, waarbij een computer elke pixel in een afbeelding van een categorie voorziet zodat wegoppervlakken, trottoirs, auto’s, bussen en mensen in betekenisvolle regio’s worden gescheiden. Gewone systemen falen vaak wanneer het beeld donker, schokkerig of korrelig is — precies wanneer veilige beslissingen het belangrijkst zijn. Om dit aan te pakken, stelt het team een pijplijn voor die eerst het beeld verbetert en daarna een gedetailleerde analyse van de inhoud uitvoert, met als doel de prestaties hoog te houden, zelfs wanneer de camerafeed verre van perfect is.
Drie stappen door het beeld
De pijplijn heeft drie hoofdstadia: verscherping, pixellabeling en objectdetectie. Eerst verhoogt een superresolutiemodule gebaseerd op een geavanceerde verbeteringsmethode de resolutie en het contrast van elk frame, zodat fijne texturen, zoals wegbelijning of de contouren van kleine voertuigen, duidelijker worden. Vervolgens produceren twee specialistische tools, U-Net en DeepLabV3+, van het verbeterde beeld pixelniveaumappen die elk punt kleuren als weg, voetganger, voertuig of achtergrond. Ten slotte gebruikt een objectdetector genaamd YOLOv8x begrenzende kaders om te controleren of de gelabelde regio’s daadwerkelijk overeenkomen met geloofwaardige auto’s, mensen en verkeersobjecten en om te meten hoe goed het systeem in de praktijk zou werken.
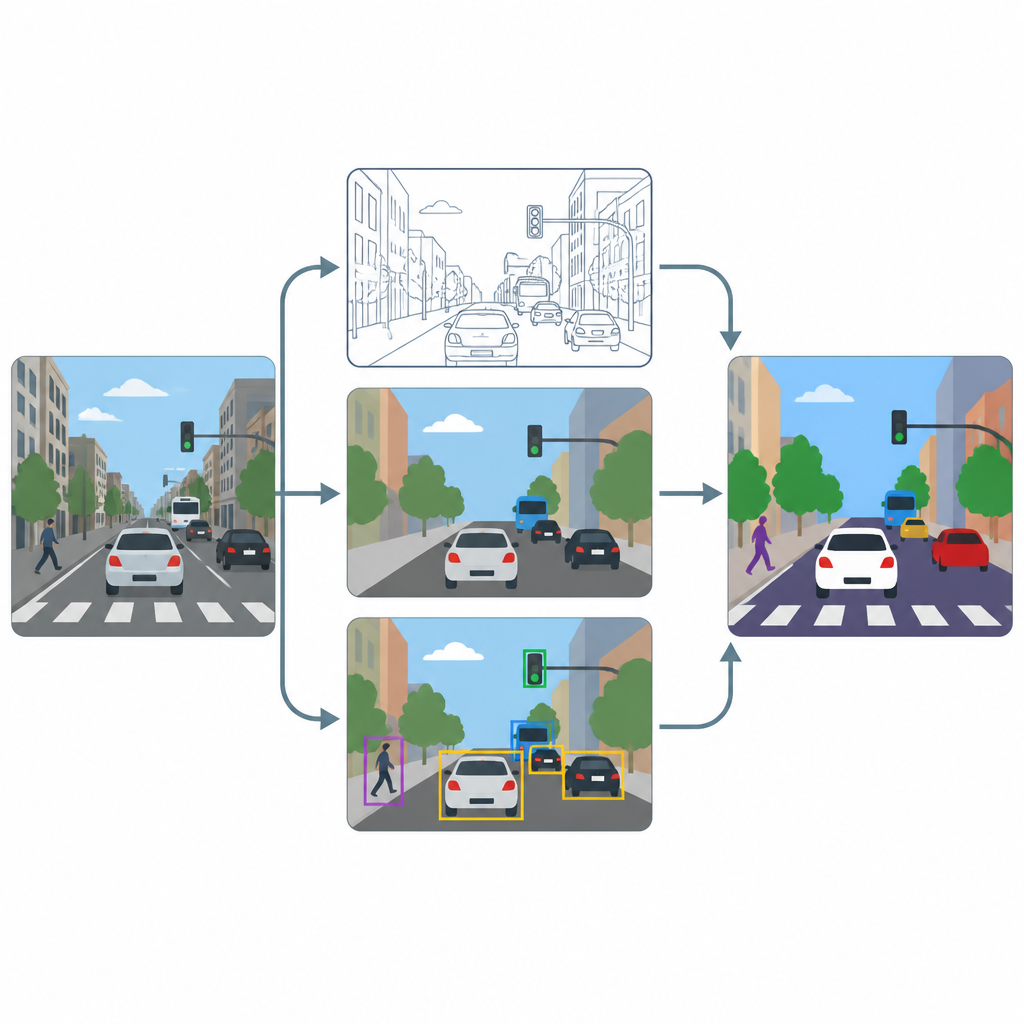
Testen op drukke stadsbeelden
Om te zien hoe goed deze opzet werkt, trainen en testen de auteurs het op een subset van de veelgebruikte COCO-afbeeldingsverzameling, met de nadruk op scènes met straten, voertuigen, verkeerslichten en voetgangers. Ze verkleinen beelden doelbewust tot een bescheiden 640 bij 640 pixels om veelvoorkomende camerafeeds na te bootsen, en gebruiken sterke data-augmentatie zodat de modellen veel variaties in verlichting, onscherpte en gezichtspunt zien. Ze vergelijken de prestaties met en zonder de verscherpingsstap en volgen zowel pixelgebaseerde scores, die weergeven hoe goed regio’s omlijnd zijn, als objectgebaseerde scores, die weergeven hoe goed individuele weggebruikers worden gedetecteerd.
Hoe de twee visietools zich tot elkaar verhouden
U-Net en DeepLabV3+ brengen verschillende sterke punten naar de taak. U-Net, met zijn sterke verbindingen tussen afbeeldingsdetails op verschillende schalen, heeft de neiging om scherpe randen rond objecten te behouden en behaalt zeer hoge beeldkwaliteitsmaten, waaronder pieksignaal-ruisverhoudingen boven 40 decibel en structurele gelijkeniswaarden dicht bij 1,0 in meerdere monsters. DeepLabV3+ is beter in het vastleggen van brede context, zoals hoe clusters voertuigen en wegen zich tot elkaar verhouden, en behaalt vaak iets hogere pixeloverlap- en detectiescores in sommige scènes. Over veel proefopstellingen heen tilt de verbeteringsstap consequent beide soorten maatstaven, wat aangeeft dat scherpere invoer leidt tot betrouwbaardere verkeersinterpretatie.
Beperkingen op zware wegen en volgende stappen
De auteurs merken ook op dat er beperkingen zijn. Hun systeem is getest op stilstaande beelden, niet op livevideo, en het heeft moeite wanneer de omstandigheden extreem slecht zijn, zoals bij dichte mist of sterke bewegingsonscherpte, waar zelfs superresolutie niet genoeg detail kan herstellen. De extra verscherpingsfase verhoogt bovendien de rekenbelasting, wat een uitdaging kan zijn voor apparaten met weinig vermogen in voertuigen. Toekomstig werk zal zich richten op lichtere modellen, betere afhandeling van nacht- en weersinvloeden en uitbreiding naar volledige videostreams met tracking, met als doel dit soort gedetailleerde scene understanding dichter bij de eisen van realtime intelligent transport te brengen.
Wat dit betekent voor alledaags vervoer
Simpel gezegd toont de studie aan dat het geven van een schoner beeld van de weg aan computers voordat ze het moeten interpreteren hun oordelen betrouwbaarder kan maken. Door beeldverbetering te combineren met twee elkaar aanvullende pixellabelingtools en een objectdetector verbetert het voorgestelde kader hoe goed een systeem wegen, auto’s en mensen in drukke verkeersscènes kan scheiden. Hoewel het nog niet klaar is om elke zware conditie of hardwarebeperking aan te kunnen, brengt deze aanpak machinale visie een stap dichter bij het omgaan met de onvolmaakte beelden die echte straten leveren.
Bronvermelding: Ramyashree, Utsavi, S.R., Raghavendra, S. et al. Comparative performance analysis of U-Net and DeepLabV3+ for semantic segmentation in traffic environments. Sci Rep 16, 15614 (2026). https://doi.org/10.1038/s41598-026-46740-2
Trefwoorden: semantische segmentatie, verkeersscènes, superresolutie, U-Net, DeepLabV3+