Clear Sky Science · tr
U-Net ve DeepLabV3+’ın trafik ortamlarında anlamsal segmentasyon için karşılaştırmalı performans analizi
Neden daha net sokak görüntüleri önemli
Modern otomobiller ve şehir kameraları yol üzerinde olanları anlamak için giderek daha fazla dijital görmeye dayanıyor. Ancak gerçek sokaklar araştırma laboratuvarlarındaki keskin fotoğraflar gibi nadiren görünür: görüntüler karanlık, bulanık, gürültülü ya da düşük çözünürlüklü olabilir. Bu çalışma, bu tür kaba trafik görüntülerini nasıl temizleyeceğini ve ardından bilgisayarlara yolları, araçları ve yayaları güvenilir şekilde nasıl tespit edeceklerini öğretmeyi araştırıyor; böylece gelecekteki sürücü destek sistemleri ve trafik izleme araçları gerçek dünya koşullarında daha güvenli kararlar alabilir.

Ham anlık görüntülerden daha net sahnelere
Araştırmacılar, bir bilgisayarın bir görüntüdeki her piksele bir kategori atadığı ve yol yüzeyleri, kaldırım, otomobiller, otobüsler ve insanların anlamlı bölgelere ayrıldığı sahne anlama görevine odaklanıyor. Sıradan sistemler, resim loş, titrek veya grenliyken sıklıkla başarısız oluyor ki bu, güvenli kararların en kritik olduğu anlara denk geliyor. Bunu ele almak için ekip, önce görüntüyü iyileştiren sonra içeriğinin ayrıntılı analizini yapan bir iş akışı öneriyor; amaç kamera akışı kusurluyken bile yüksek performansı korumak.
Görüntü üzerinde üç aşamalı yol
İş akışının üç ana aşaması var: keskinleştirme, piksel etiketleme ve nesne tespiti. İlk olarak, gelişmiş bir iyileştirme yöntemine dayalı bir süper çözünürlük modülü her karede çözünürlüğü ve kontrastı artırarak şerit işaretleri veya küçük araçların konturları gibi ince dokuları daha belirgin hale getirir. Sonra, U-Net ve DeepLabV3+ adlı iki uzman araç, iyileştirilmiş görüntüyü alır ve her noktayı yol, yaya, araç veya arka plan olarak renklendiren piksel seviyesinde haritalar üretir. Son olarak, YOLOv8x adlı bir nesne algılayıcı, etiketlenmiş bölgelerin gerçekten makul otomobillere, insanlara ve trafik unsurlarına karşılık gelip gelmediğini kutularla kontrol eder ve sistemin pratikte ne kadar iyi çalışacağını ölçer.
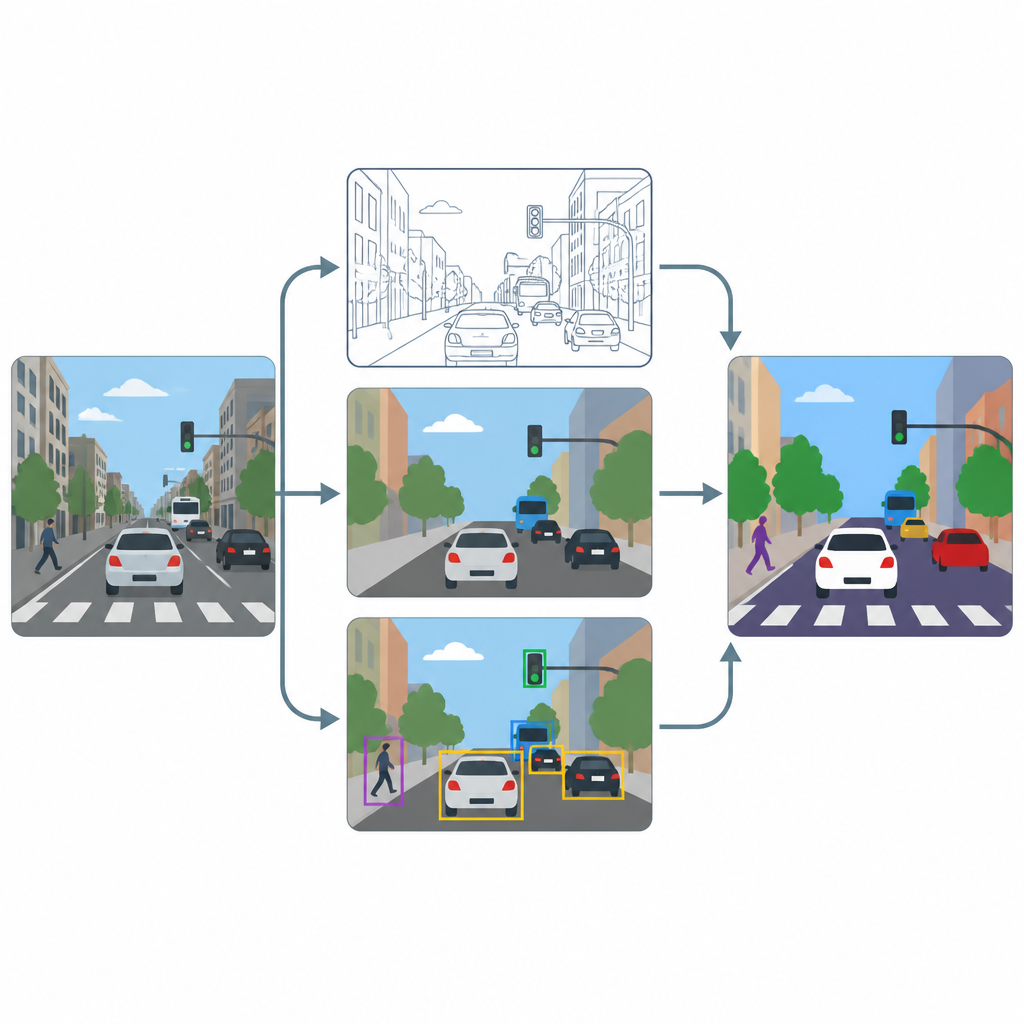
Kalabalık şehir sahnelerinde test
Bu düzenin ne kadar iyi çalıştığını görmek için yazarlar, sokaklar, araçlar, işaretler ve yayaların bulunduğu sahnelere odaklanarak yaygın olarak kullanılan COCO görsel koleksiyonunun bir alt kümesi üzerinde eğitip test ediyor. Kameradan gelen akışlara benzetmek için görüntüleri kasıtlı olarak mütevazı bir 640 x 640 piksel boyutuna yeniden boyutlandırıyorlar ve modellerin aydınlatma, bulanıklık ve bakış açısı açısından çok sayıda varyasyonu görmesi için güçlü veri artırma uyguluyorlar. Keskinleştirme adımının olduğu ve olmadığı durumu karşılaştırıyor ve bölgelerin ne kadar iyi çizildiğini yansıtan piksel tabanlı puanları ile bireysel sokak kullanıcılarının ne kadar iyi tespit edildiğini gösteren nesne tabanlı puanları izliyorlar.
İki görme aracının karşılaştırması
U-Net ve DeepLabV3+ göreve farklı güçlü yönler getiriyor. Farklı ölçeklerdeki görüntü detayları arasında güçlü bağlantılara sahip olan U-Net, genellikle nesnelerin etrafında keskin sınırları koruma eğilimindedir ve birkaç örnekte 40 desibelin üzerinde tepe sinyal-gürültü oranları ile 1.0’a yakın yapısal benzerlik değerleri dahil olmak üzere çok yüksek görüntü kalitesi ölçümleri elde eder. DeepLabV3+ ise araç kümelerinin ve yolların nasıl ilişkili olduğu gibi geniş bağlamı yakalamada daha iyidir ve bazı sahnelerde piksel örtüşme ve tespit puanlarında biraz daha yüksek sonuçlar elde edebilir. Birçok denemede, iyileştirme adımı her iki ölçü ailesini de tutarlı şekilde yükseltiyor; bu da daha net girdilerin trafik anlayışını daha güvenilir kıldığını gösteriyor.
Zorlu yollar üzerindeki sınırlamalar ve gelecek adımlar
Yazarlar ayrıca bazı sınırlamalara dikkat çekiyor. Sistemleri canlı video değil durağan görüntüler üzerinde test edildi ve yoğun sis veya şiddetli hareket bulanıklığı gibi koşullar son derece kötü olduğunda, süper çözünürlüğün bile yeterli ayrıntıyı kurtaramadığı durumlarda başarısız oluyor. Ek keskinleştirme aşaması ayrıca hesaplama yükünü artırıyor; bu da araç içindeki düşük güçlü cihazlar için bir zorluk olabilir. Gelecek çalışmalar daha hafif modeller, gece ve hava koşullarının daha iyi ele alınması ve izleme ile tam video akışlarına uzatma üzerinde duracak; amaç bu tür ayrıntılı sahne anlayışını gerçek zamanlı akıllı taşımacılığın taleplerine daha yakın hale getirmek.
Günlük yolculuklar için ne anlama geliyor
Basitçe söylemek gerekirse, çalışma bilgisayarlardan yorumlamadan önce yola daha temiz bir görüntü verildiğinde kararlarının daha güvenilir olabileceğini gösteriyor. Görüntü iyileştirme ile birbirini tamamlayan iki piksel etiketleme aracı ve bir nesne algılayıcıyı birleştirerek önerilen çerçeve, yoğun trafik sahnelerinde bir sistemin yolları, araçları ve insanları ne kadar iyi ayırabildiğini iyileştiriyor. Henüz her zorlu koşulu veya donanım kısıtını karşılayacak seviyede olmasa da bu yaklaşım, makine görüşünü gerçek sokakların sunduğu kusurlu görüntülerle başa çıkma konusunda bir adım daha ileri taşıyor.
Atıf: Ramyashree, Utsavi, S.R., Raghavendra, S. et al. Comparative performance analysis of U-Net and DeepLabV3+ for semantic segmentation in traffic environments. Sci Rep 16, 15614 (2026). https://doi.org/10.1038/s41598-026-46740-2
Anahtar kelimeler: anlamsal segmentasyon, trafik sahneleri, süper çözünürlük, U-Net, DeepLabV3+