Clear Sky Science · zh
SVRS:基于立体视觉的自监督三维体素重建网络
为了更安全的机器人而以三维看世界
自动驾驶汽车和服务型机器人必须以三维理解周围环境的形状,才能避免碰撞并安全行驶。本研究介绍了一种更快且更准确的方式,将成对的普通相机图像转换为附近物体的细致三维网格地图,可能在不依赖昂贵激光传感器的前提下提升未来机器人的可靠性。
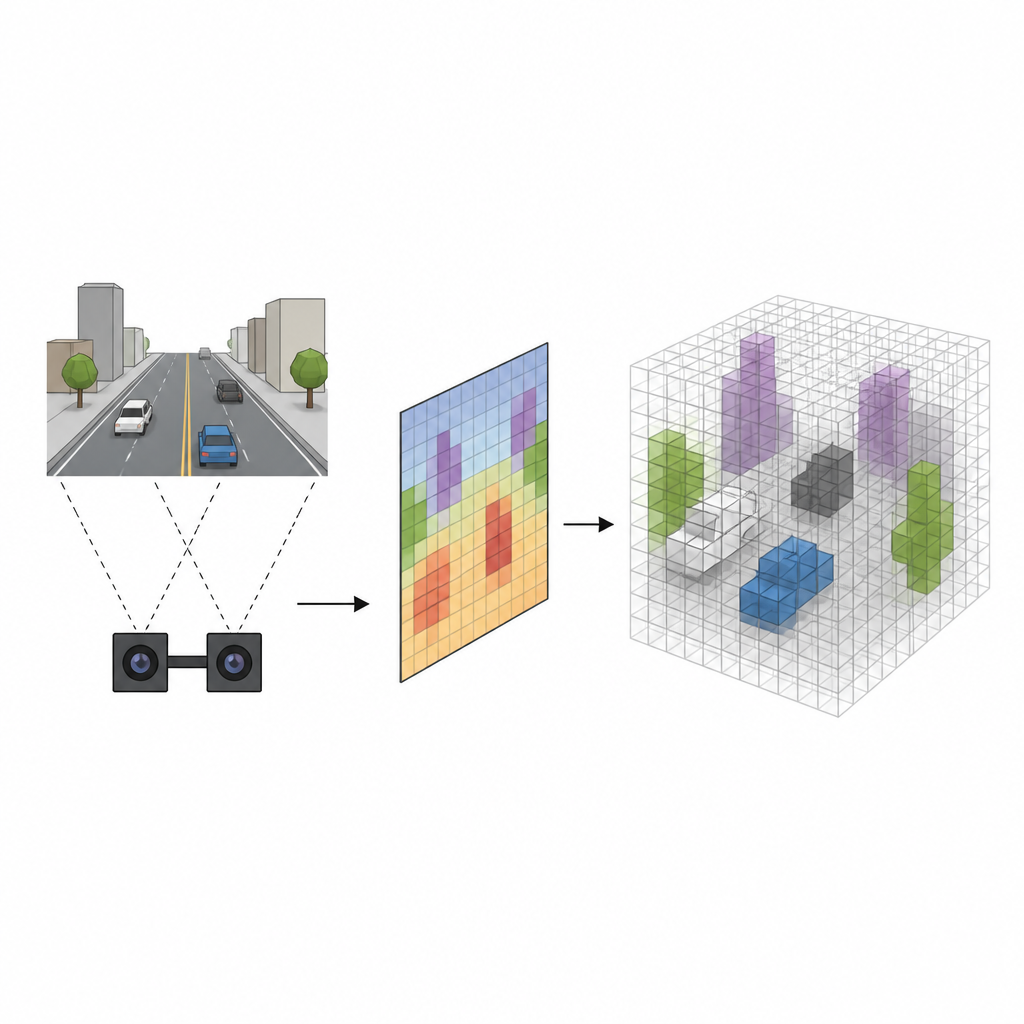
从平面图像到实体空间
许多机器人使用立体相机,从两个略有不同的视点观察场景,类似于人眼。传统系统通常先估计每个像素到相机的距离,然后将像素投影到三维空间,填充称为体素的小立方体以标记可能存在物体的位置。尽管该方法可行,但它速度较慢且容易模糊物体边界,导致把空白区域错误标记为被占据产生误报。新方法称为 SVRS,跳过了逐像素投影的繁重步骤,而是学习一种更直接的关联,将相机所见与空间中真正被占据的体素直接连接起来。
教网络用立方体思考
研究人员将车辆前方区域表示为一叠匀称小立方体,组成一个三维网格。他们不是从像素出发把它们推入空间,而是让其像素体素投影模块从每个立方体出发,询问该立方体在相机图像中会出现在哪里。利用已知的立体相机几何关系,该模块将每个体素反投影到两幅图像上,并采样现代立体网络计算得到的丰富内部特征。这样就把稠密的图像信息转为与每个体素直接关联的稀疏三维信号,切除空白区域的不必要计算并减少导致误报的边缘模糊。
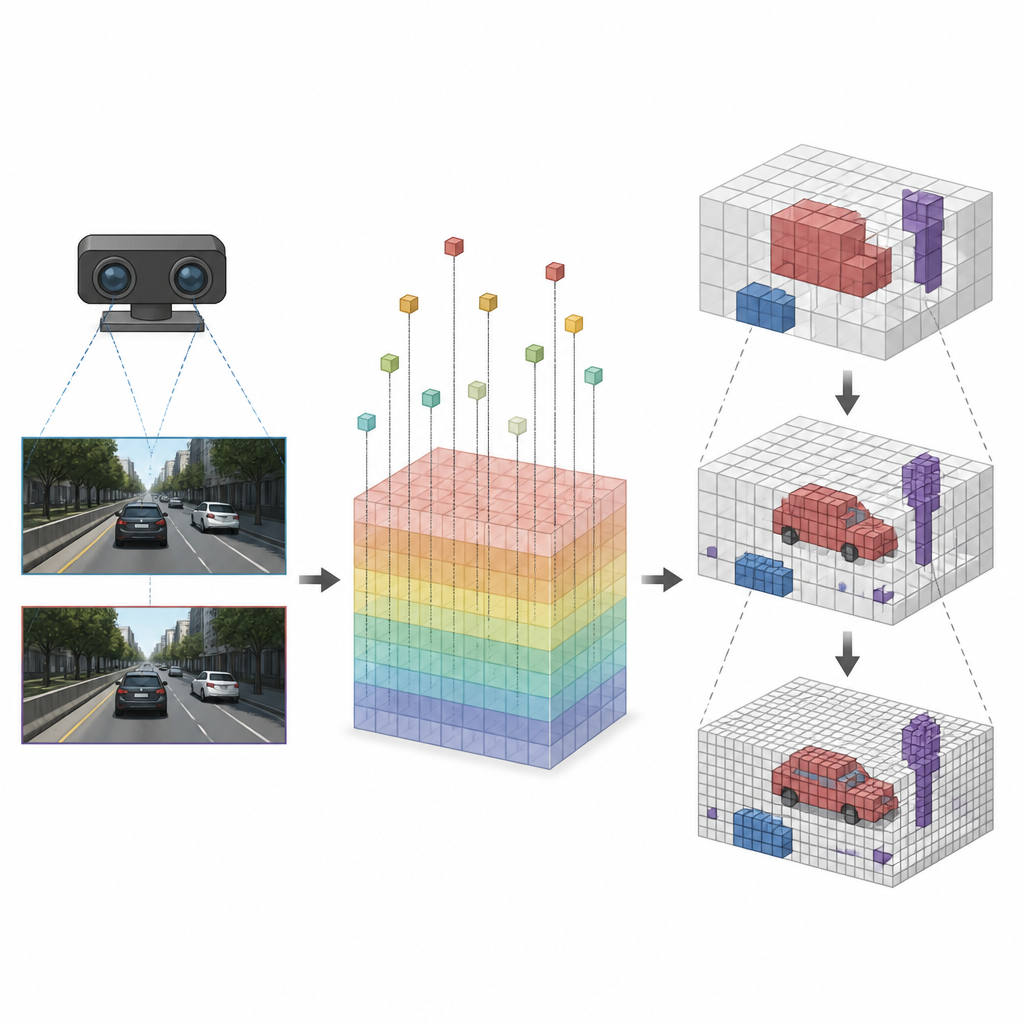
在重要处集中细节
一旦每个体素与合适的图像特征建立了联系,SVRS 采用基于八叉树的编码-解码结构来判断哪些体素被占据。其思想是从粗略的场景视图开始,然后逐步细化。在每个层级,网络预测哪些较大的立方体包含物体,并用该信息指导下一更细的层级,只有有希望的区域才会被详细检查。空白区域在早期被抑制,这样在放大细节时它们不会淹没网络。由粗到细的策略使计算集中在车辆、道路边缘和其他重要物体上,而不是在空旷空气上浪费资源。
用现有传感器数据自我监督,无需人工标注
在训练系统时,作者避免了昂贵的三维场景人工标注。相反,他们使用由现有强大的立体和基于激光的方法产生的深度图和点云作为教学信号。他们在将立体深度转为三维网格之前,用简单的边缘检测器清理深度数据,并且也尝试直接以激光测量作为训练目标。这种自监督设置让网络能够模拟高质量的三维数据,同时在运行时更轻、更快,使其适用于车辆中的嵌入式计算平台。
为移动机械提供更快更清晰的三维视图
在一个大型驾驶数据集上的测试表明,SVRS 在重建三维网格的准确性上可与领先的立体方法相匹配,同时在速度上比一些强基线快多达十四倍,比其他实时系统约快三倍。它减少了将空白误判为被占据的情况,尽管可能会漏检一些小物体,这反映了谨慎与完整性之间的权衡。对于普通读者来说,关键信息是该方法帮助机器将相机图像转化为更清晰、更高效的道路三维图景,这是通向更安全、更强大自动驾驶车辆和机器人的重要一步。
引用: Zou, Z., Wu, Y., Zhang, H. et al. SVRS: self-supervised 3D voxel reconstruction network from stereo vision. Sci Rep 16, 15548 (2026). https://doi.org/10.1038/s41598-026-45924-0
关键词: 立体视觉, 三维重建, 体素网格, 自动驾驶, 机器人感知